
🌿데이터 색인
Elasticsearch는 Oracle보다 훨씬 더 많은 양의 데이터를 검색한다.
Elasticsearch는 데이터를 저장할 때 색인을 거쳐서 저장이 된다는 특징이 있다.
Full Text Search
[AWS] Elasticsearch 검색: Multitenancy, Full Text Search, QueryDSL
🌿Elasticsearch 검색 Elasticsearch는 관계형 데이터베이스에 비해 다양하고 효과적인 검색 기능을 제공한다. 가장 주된 특징은 풀 텍스트 검색(Full Text Search)을 지원한다는 점이다. 누군가 Elasticsearch
isaac-christian.tistory.com
앞서 사용할 Elasticsearch 검색 방법은 위 글을 참고한다.
Elasticsearch는 키워드로 검색한다는 의미의 Full Text Search를 지원하며, 기본적인 검색에서는 공백으로 구분된 토큰(텀, Term)을 기준으로 검색을 한다.
match, match_all, match_phrase 등의 검색 방법이 있으며, 검색 옵션으로 slop을 사용할 수 있다. 이때 slop이 너무 많아지면 단지 두 단어가 포함되었다는 것만으로 단어를 찾기 때문에 주의해야 한다.
역인덱스 (Inverted Index)
데이터 저장 방식
# 영문 데이터
POST my_english/_bulk
{"index":{"_id":1}}
{"message":"The quick brown fox"}
{"index":{"_id":2}}
{"message":"The quick brown fox jumps over the lazy dog"}
{"index":{"_id":3}}
{"message":"The quick brown fox jumps over the quick dog"}
{"index":{"_id":4}}
{"message":"Brown fox brown dog"}
{"index":{"_id":5}}
{"message":"Lazy jumping dog"}
# 한글 데이터
POST my_korean/_bulk
{"index":{"_id":1}}
{"message":"지붕 위의 갈색 닭"}
{"index":{"_id":2}}
{"message":"지붕 위의 갈색 닭 그리고 밑에 검은색 강아지"}
{"index":{"_id":3}}
{"message":"지붕 위의 갈색 우는 닭 그리고 밑에 갈색 게으른 강아지"}
{"index":{"_id":4}}
{"message":"갈색 게으른 바보 강아지 옆에 빨간색 닭"}
{"index":{"_id":5}}
{"message":"졸고 있는 갈색 강아지"}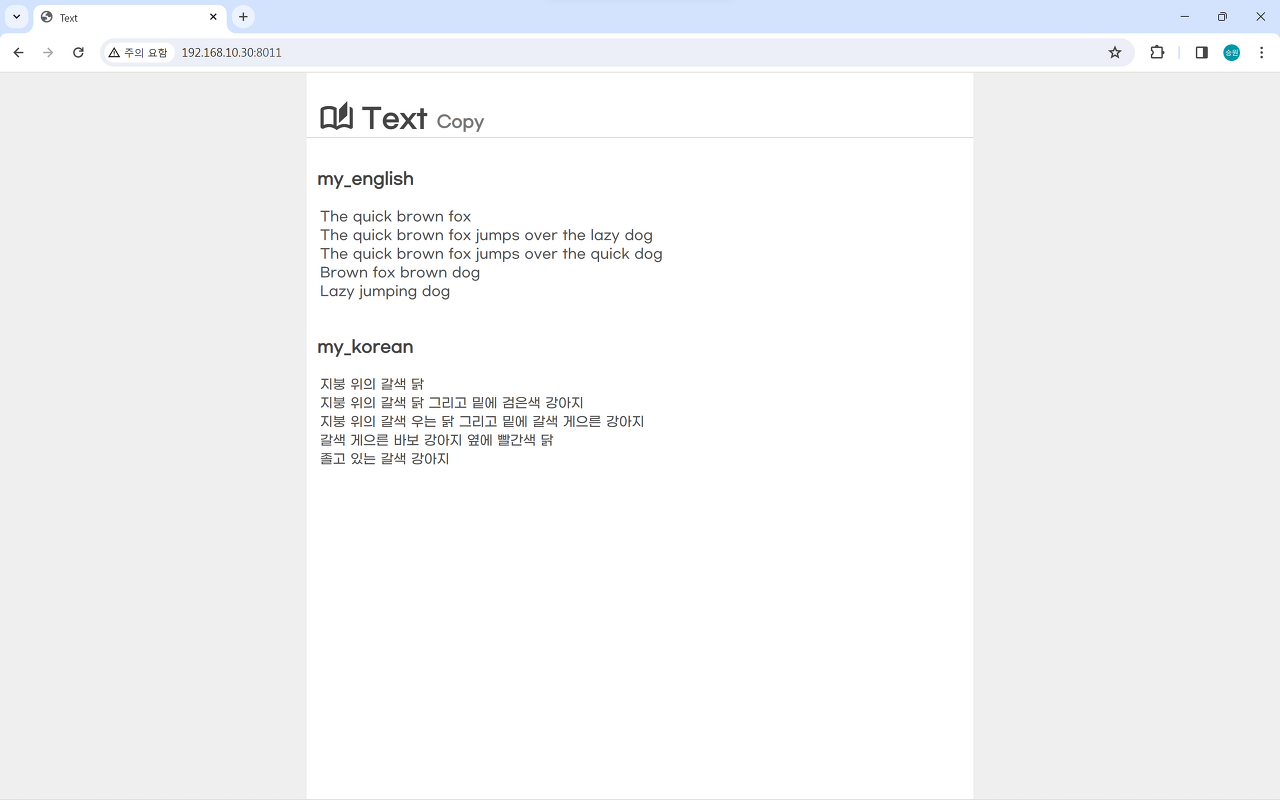
위의 데이터를 저장한다고 할 때, Elasticsearch는 완전히 다르게 데이터를 저장한다.
관계형 데이터베이스(RDBMS)는 데이터가 깨지지 않는 데이터만을 저장할 수 있도록 개입하기에 검색을 하기 좋은 환경은 아니다. 검색할 데이터가 점점 많아지면 이러한 환경은 문제가 될 수 있다.
Elasticsearch는 데이터를 저장할 때 토큰으로 쪼갠다. "The quick brown fox"라는 문장이 있다면 'The', 'quick', 'brown', 'fox'의 4개의 단어로 쪼개서 저장하게 되며, 이때 기준은 텀(Term)이다. 이를 역인덱스 구조라고 하며, 오로지 검색에 구조가 맞춰져 있는 방식이다.
🌿애널라이저 (Analyzer)
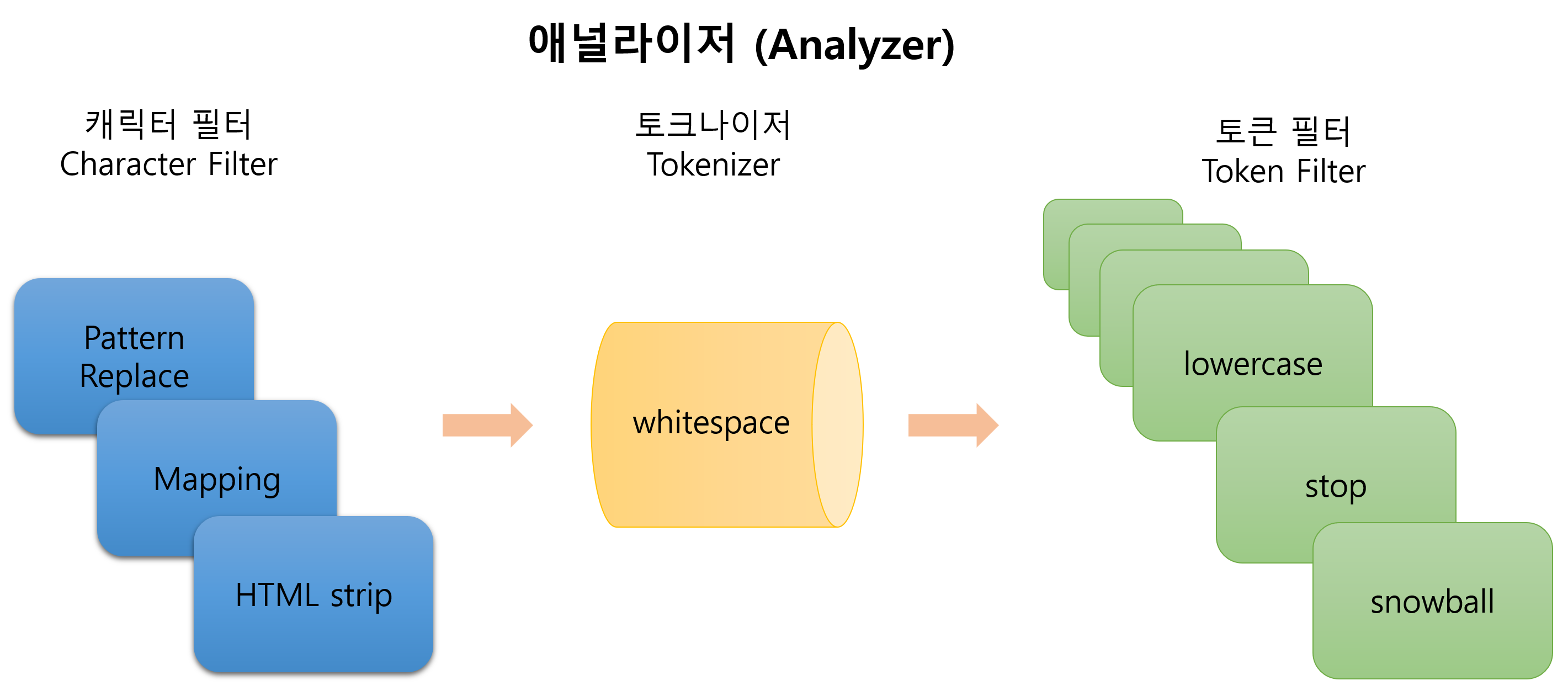
witespace 토크나이저는 말 그대로 토큰으로 쪼개는 역할을 한다. 이때, 공백을 기준으로 쪼갠다.
아무런 설정을 하지 않으면 whitespace 토크나이저만 작동한다.
lowercase는 모든 대문자를 소문자로 바꾸는 역할을 한다. 만약 대문자로 시작하는 The와 소문자로 시작하는 the가 있다면 단어를 병합하게 된다.
Stopword는 우리말로 하면 불용어라고 한다. 불용어는 검색어로서 가치가 없는 단어를 의미한다. stop에서는 동사나 명사를 주로 검색하기 때문에, 검색에 활용도가 떨어지는 단어를 제외하는 작업을 하게 된다.
snowball은 형태소 분석을 하면 기본 형태로 변환을 하게 된다. 기본적으로 가지고 있는 사전으로 jumps와 jumping을 모두 기본 형태인 jump로 변환한다.
누군가 Elasticsearch에 대해 묻는다면 반드시 답변에 역인덱스에 대해 들어가야 한다. 예로 들어 역인덱스 구조로 데이터를 저장하기 때문에 검색에 용이한 구조로 들어가 있다고 대답할 수 있어야 한다.
analyze API
analyze API는 임시로 애널라이저의 적용을 확인하는 도구이다.
실제 수행하는 게 아니므로 테스트로 사용한다.
GET _analyze
{
"text": "The quick brown fox jumps over the lazy dog",
"tokenizer": "whitespace"
}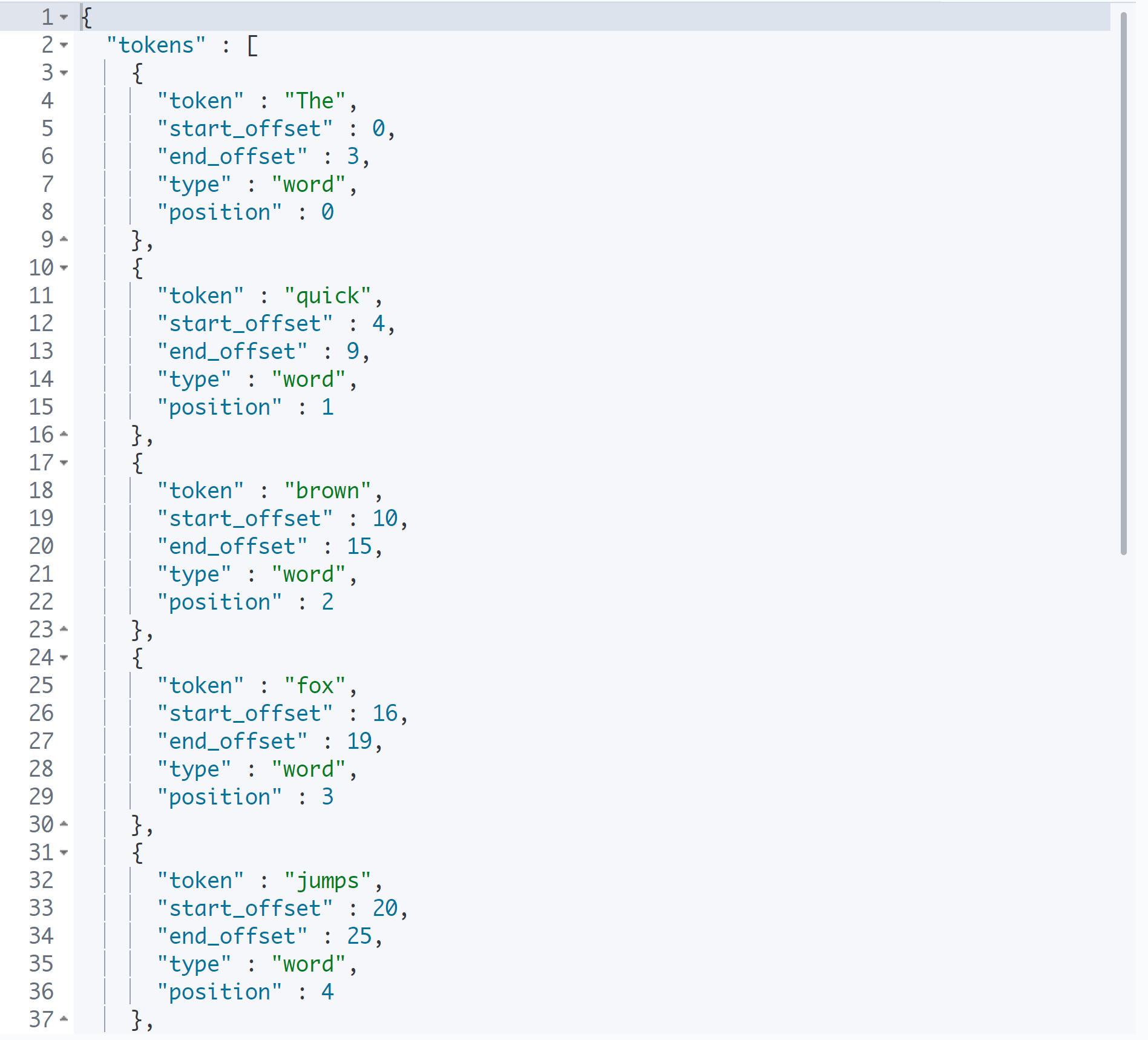
토크나이저를 진행했을 때의 결과를 보여준다.
토큰을 텀이라는 형태로 저장하는 것을 볼 수 있다.
여기에 추가로 토큰 필터를 걸어보도록 하자.
토크나이저는 유일하지만, 필터는 여러 개를 걸 수 있기 때문에 배열이다.
Filter
filter: lowercase
GET _analyze
{
"text": "The quick brown fox jumps over the lazy dog",
"tokenizer": "whitespace",
"filter": [
"lowercase"
]
}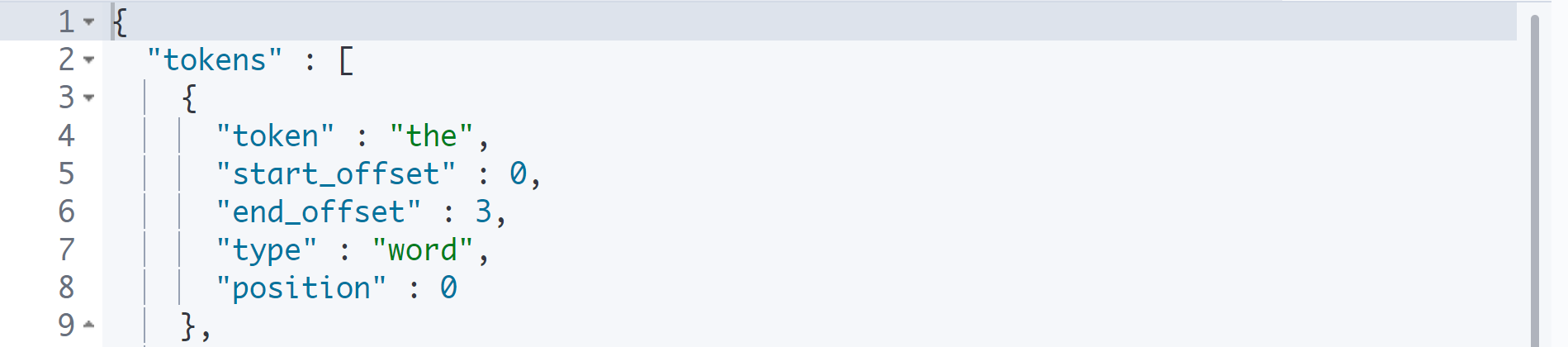
대문자 'The'가 소문자 'the'로 변경되었다.
filter: stop
GET _analyze
{
"text": "The quick brown fox jumps over the lazy dog",
"tokenizer": "whitespace",
"filter": [
"stop"
]
}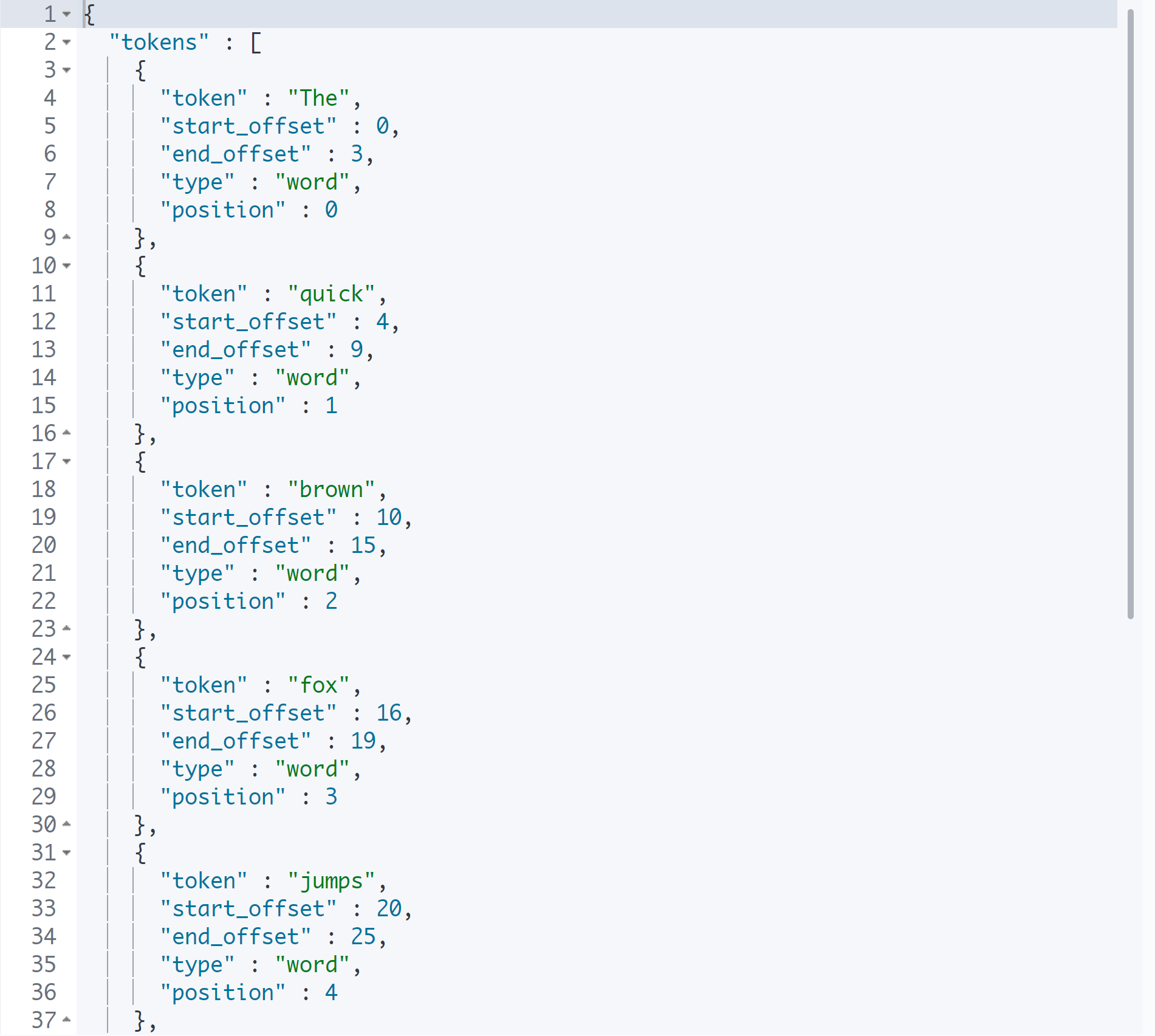
The는 정관사이지만, 모든 정관사는 소문자로 되어 있기 때문에 대문자 The를 불용어로 없애고 싶으면 lowercase를 같이 적용시키면 된다.
filter: snow

형태소 분석을 해서 단어의 가장 원형을 남겨 놓고 저장을 한다.
jumps가 jump가 되고, lazy가 lazi로 변경된 것을 확인할 수 있다.
snowball 애널라이저
토큰 필터 중에 snoball 토큰 필터가 있고, whitespace 토크나이저 + lowercase, stop, snoball 토큰 필터를 세트로 합친 snowball 애널라이저가 있다.
기본적인 검색을 할 때에는 이 snowball 애널라이저를 사용한다.
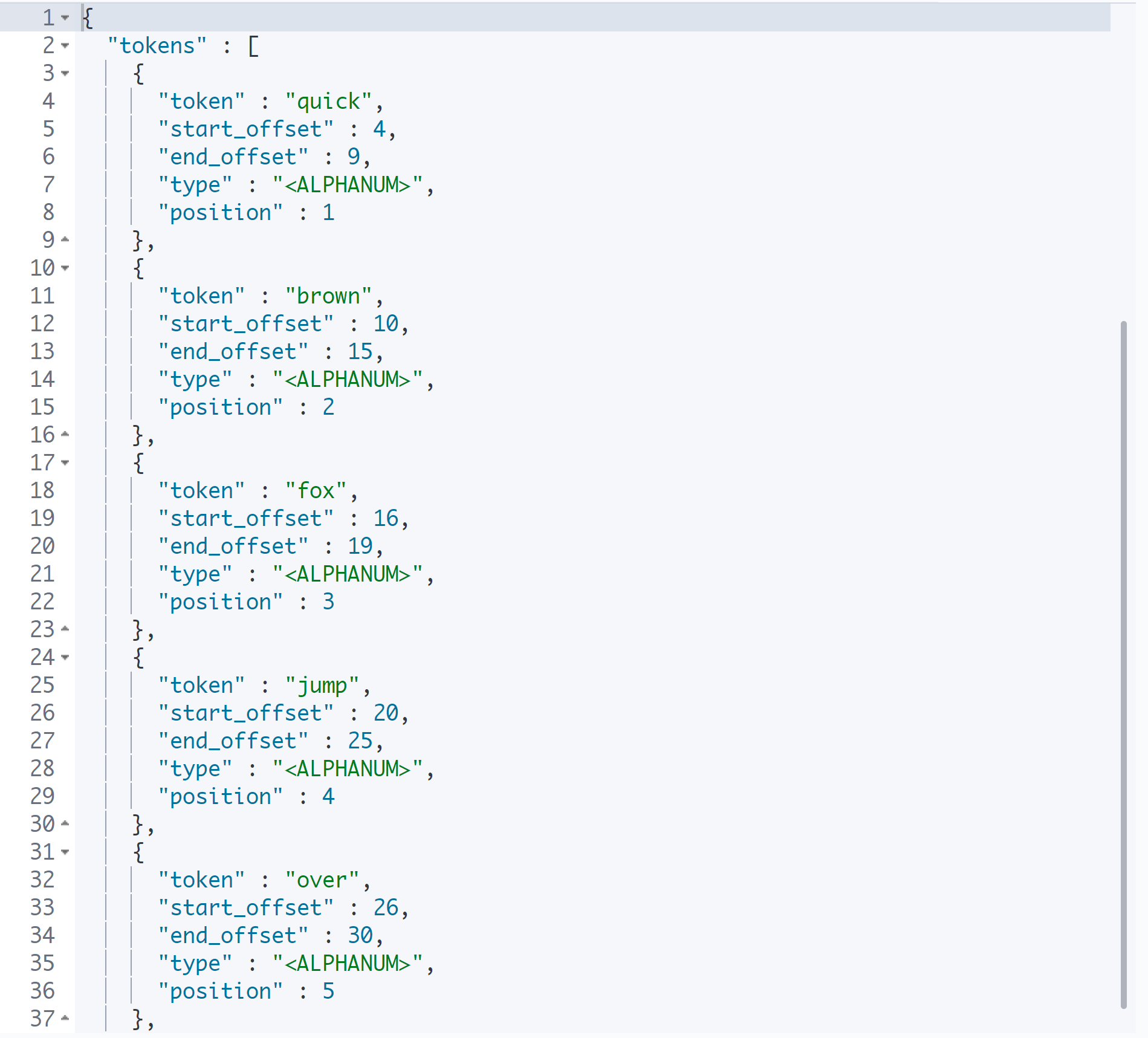
GET _analyze
{
"text": "The quick brown fox jumps over the lazy dog",
"analyzer": "snowball"
}
인덱스 + 애널라이저 적용
생성된 인덱스에 애널라이저를 적용하여 실제로 저장해 보도록 하자.
Elasticsearch에서는 스키마라는 표현 대신에 매핑이라는 표현을 사용한다.
mapping API
GET my_english/_mapping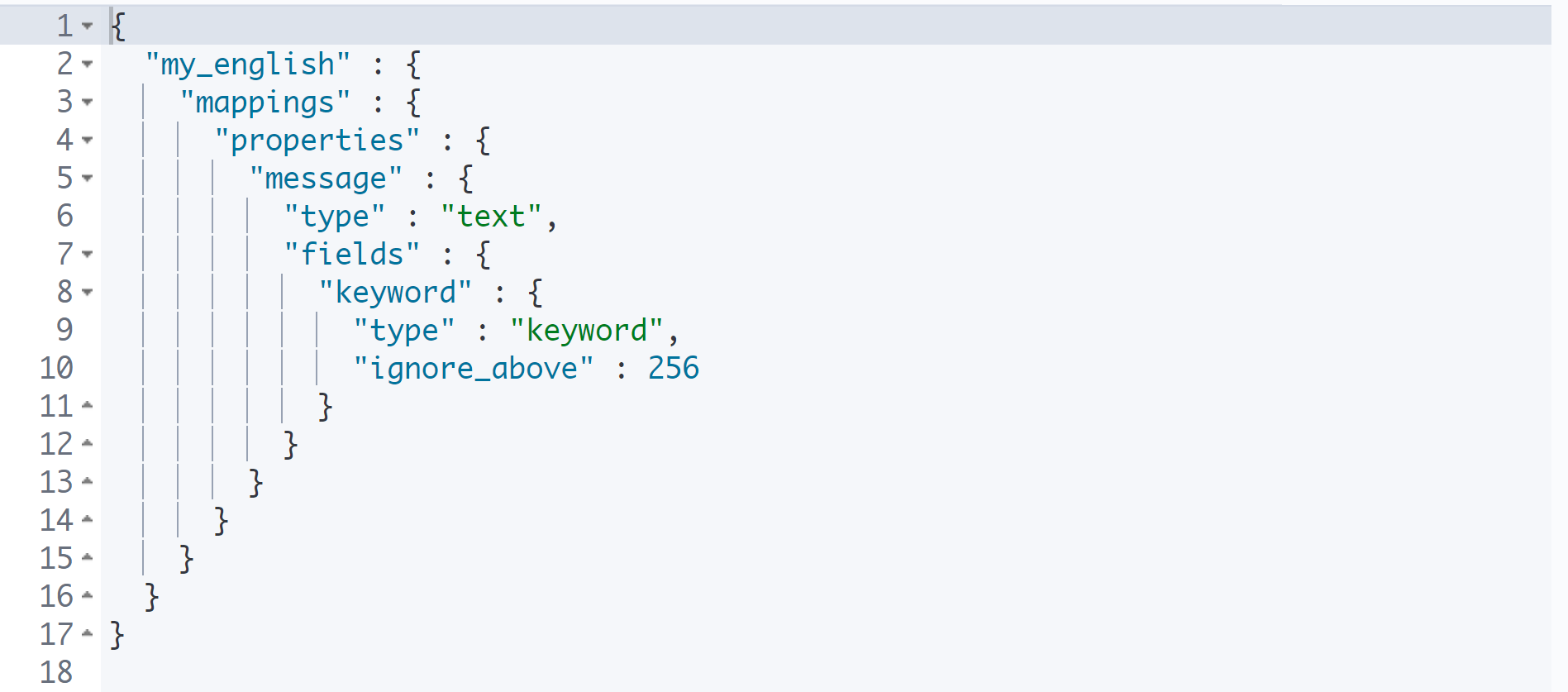
mapping API를 사용하여 인덱스의 구조를 확인할 수 있다.
my_english 인덱스에는 message라는 프로퍼티가 1개 있으며, 이에 대한 정의를 하고 있다.
기본적으로 문자열을 저장하면 text type으로 저장된다.
정적 매핑과 동적 매핑
# 정적 매핑
PUT my_english2
# 동적 매핑
PUT my_english2
{
"mappings": {
"properties": {
"message": {
"type": "text",
"analyzer": "standard"
}
}
}
}Elasticsearch는 자동으로 매핑이 된다. 즉, 저장소의 규칙이 자동으로 생성된다. 이는 인덱스의 구조가 자동으로 생성된다고 이해하면 된다.
Oracle 또는 CSS 등에서 데이터를 수급하여 Elasticsearch에서 검색을 하게 된다. 이때 Elasticsearch가 들어가는 데이터에 따라서 동적으로 데이터 구조가 생성되는데, 이를 그냥 두면 안 된다.
나중에 검색을 할 때 데이터가 숫자, 텍스트, 날짜 중 어떤 자료형이냐에 따라서 검색 패턴이 달라지기 때문이다.
인덱스를 만들 때에는 이와 같이 어떤 데이터를 어떤 자료형으로 넣을 것이라는 매핑 작업이 필요하다.
snowball 정적 매핑
# 기존 인덱스 삭제
DELETE my_english3
# 정적 매핑: snowball
PUT my_english3
{
"mappings": {
"properties": {
"message": {
"type": "text",
"analyzer": "snowball"
}
}
}
}
# 영문 데이터
POST my_english3/_bulk
{"index":{"_id":1}}
{"message":"The quick brown fox"}
{"index":{"_id":2}}
{"message":"The quick brown fox jumps over the lazy dog"}
{"index":{"_id":3}}
{"message":"The quick brown fox jumps over the quick dog"}
{"index":{"_id":4}}
{"message":"Brown fox brown dog"}
{"index":{"_id":5}}
{"message":"Lazy jumping dog"}
# 검색
GET my_english3/_search
{
"query": {
"match": {
"message": "jump"
}
}
}
snowball 애널라이즈로 저장되었기 때문에 jump로 검색하면 jumping, jumps 모두 찾아주는 것을 확인할 수 있다.
🌿Nori
형태소 분석기
영어 형태소 분석기는 snowball이며, 한글 형태소 분석기는 Nori로 ES 6.X에서부터 적용되었다.
Nori 설치
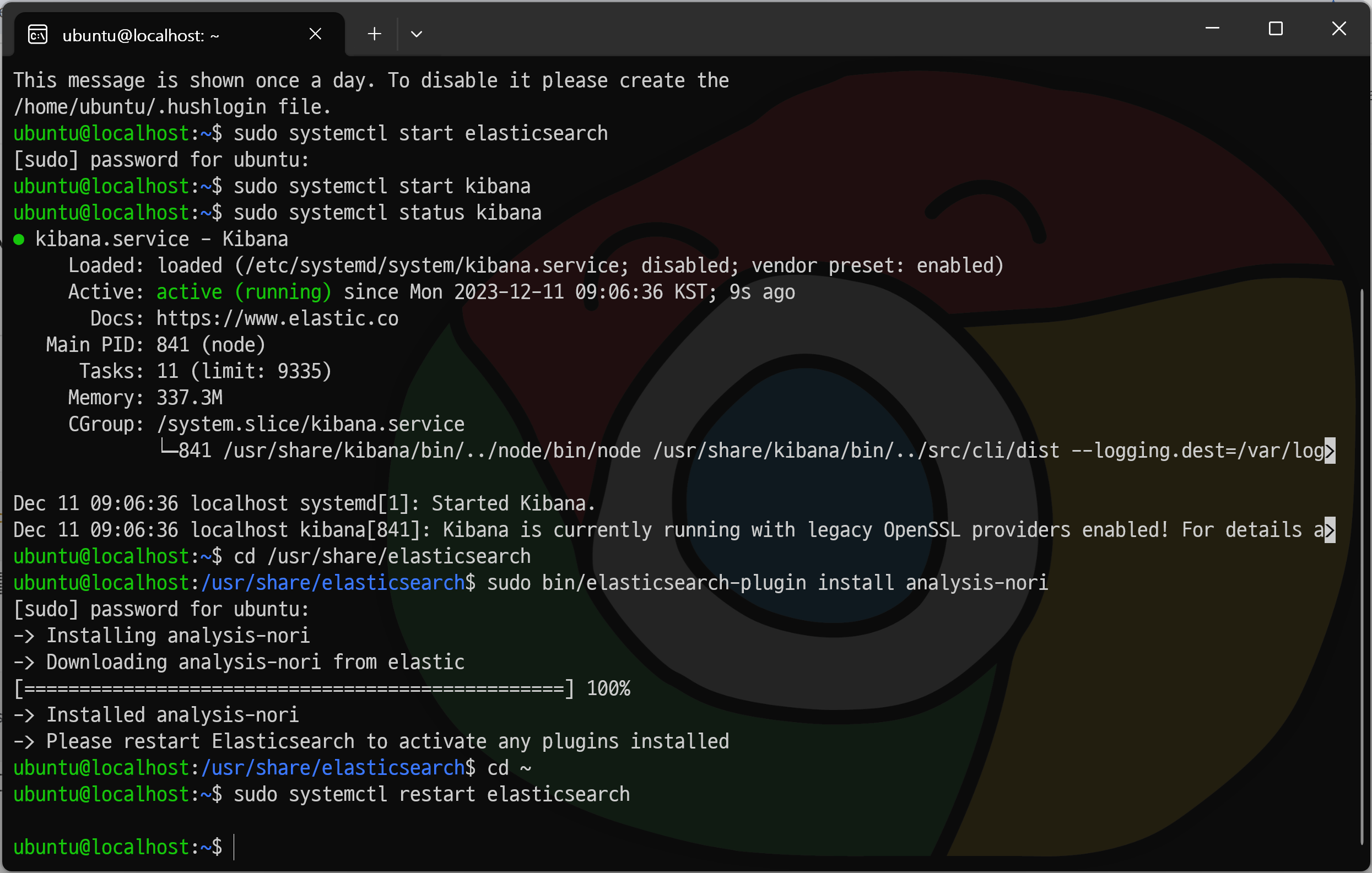
$ cd /usr/share/elasticsearchNori를 설치하기 위해 Elasticsearch 폴더로 이동한다.
$ sudo bin/elasticsearch-plugin install analysis-nori플러그인 명령어로 analysis-nori를 설치한다.
$ cd ~
$ sudo systemctl restart elasticsearch다시 홈 폴더로 이동한다.
그리고 플러그인을 실행시키기 위해 반드시 서비스를 재시작해야 한다.
nori_tokenizer
GET _analyze
{
"text": "동해물과 백두산이",
"tokenizer": "standard"
}
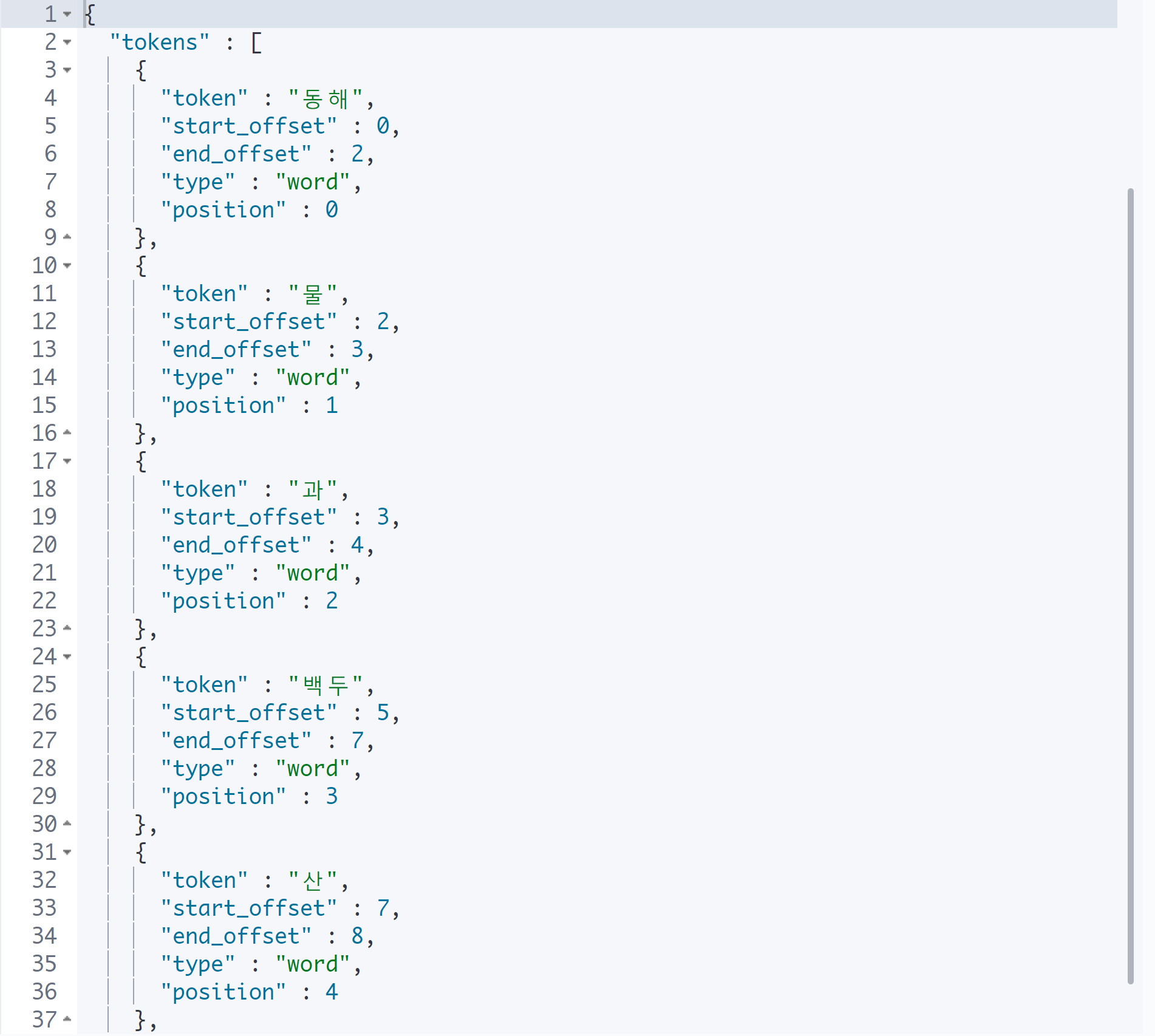
GET _analyze
{
"text": "동해물과 백두산이",
"tokenizer": "nori_tokenizer"
}
my_nori 데이터 삽입
# my_nori
PUT my_nori
{
"settings": {
"analysis": {
"tokenizer": {
"nori_none": {
"type": "nori_tokenizer",
"decompound_mode": "none"
},
"nori_discard": {
"type": "nori_tokenizer",
"decompound_mode": "discard"
},
"nori_mixed": {
"type": "nori_tokenizer",
"decompound_mode": "mixed"
}
}
}
}
}
nori_tokenizer의 종류
GET my_nori/_analyze
{
"text": "백두산이",
"tokenizer": "nori_tokenizer"
}
GET my_nori/_analyze
{
"text": "백두산이",
"tokenizer": "nori_none"
}
GET my_nori/_analyze
{
"text": "백두산이",
"tokenizer": "nori_discard"
}
GET my_nori/_analyze
{
"text": "백두산이",
"tokenizer": "nori_mixed"
}검색에 따라 기본을 사용해도 되고, 경우에 따라 합성어를 쪼개지 않고 한 덩어리로 묶을 수도 있다.
nori_readingform
GET _analyze
{
"tokenizer": "nori_tokenizer",
"text": "春夏秋冬",
"filter": [
"nori_readingform"
]
}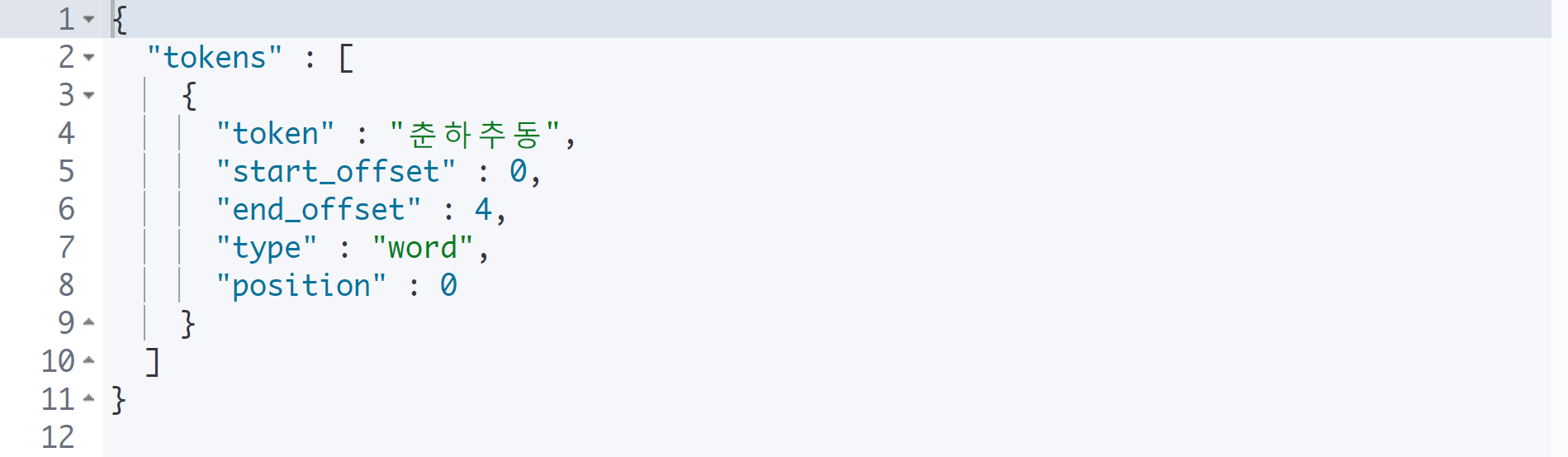
검색해야 할 대상 중에 한자가 많은 경우 nori_readingform 필터를 걸어 한글로 출력할 수 있다.

🌿데이터 색인
Elasticsearch는 Oracle보다 훨씬 더 많은 양의 데이터를 검색한다.
Elasticsearch는 데이터를 저장할 때 색인을 거쳐서 저장이 된다는 특징이 있다.
Full Text Search
[AWS] Elasticsearch 검색: Multitenancy, Full Text Search, QueryDSL
🌿Elasticsearch 검색 Elasticsearch는 관계형 데이터베이스에 비해 다양하고 효과적인 검색 기능을 제공한다. 가장 주된 특징은 풀 텍스트 검색(Full Text Search)을 지원한다는 점이다. 누군가 Elasticsearch
isaac-christian.tistory.com
앞서 사용할 Elasticsearch 검색 방법은 위 글을 참고한다.
Elasticsearch는 키워드로 검색한다는 의미의 Full Text Search를 지원하며, 기본적인 검색에서는 공백으로 구분된 토큰(텀, Term)을 기준으로 검색을 한다.
match, match_all, match_phrase 등의 검색 방법이 있으며, 검색 옵션으로 slop을 사용할 수 있다. 이때 slop이 너무 많아지면 단지 두 단어가 포함되었다는 것만으로 단어를 찾기 때문에 주의해야 한다.
역인덱스 (Inverted Index)
데이터 저장 방식
# 영문 데이터
POST my_english/_bulk
{"index":{"_id":1}}
{"message":"The quick brown fox"}
{"index":{"_id":2}}
{"message":"The quick brown fox jumps over the lazy dog"}
{"index":{"_id":3}}
{"message":"The quick brown fox jumps over the quick dog"}
{"index":{"_id":4}}
{"message":"Brown fox brown dog"}
{"index":{"_id":5}}
{"message":"Lazy jumping dog"}
# 한글 데이터
POST my_korean/_bulk
{"index":{"_id":1}}
{"message":"지붕 위의 갈색 닭"}
{"index":{"_id":2}}
{"message":"지붕 위의 갈색 닭 그리고 밑에 검은색 강아지"}
{"index":{"_id":3}}
{"message":"지붕 위의 갈색 우는 닭 그리고 밑에 갈색 게으른 강아지"}
{"index":{"_id":4}}
{"message":"갈색 게으른 바보 강아지 옆에 빨간색 닭"}
{"index":{"_id":5}}
{"message":"졸고 있는 갈색 강아지"}위의 데이터를 저장한다고 할 때, Elasticsearch는 완전히 다르게 데이터를 저장한다.
관계형 데이터베이스(RDBMS)는 데이터가 깨지지 않는 데이터만을 저장할 수 있도록 개입하기에 검색을 하기 좋은 환경은 아니다. 검색할 데이터가 점점 많아지면 이러한 환경은 문제가 될 수 있다.
Elasticsearch는 데이터를 저장할 때 토큰으로 쪼갠다. "The quick brown fox"라는 문장이 있다면 'The', 'quick', 'brown', 'fox'의 4개의 단어로 쪼개서 저장하게 되며, 이때 기준은 텀(Term)이다. 이를 역인덱스 구조라고 하며, 오로지 검색에 구조가 맞춰져 있는 방식이다.
🌿애널라이저 (Analyzer)
witespace 토크나이저는 말 그대로 토큰으로 쪼개는 역할을 한다. 이때, 공백을 기준으로 쪼갠다.
아무런 설정을 하지 않으면 whitespace 토크나이저만 작동한다.
lowercase는 모든 대문자를 소문자로 바꾸는 역할을 한다. 만약 대문자로 시작하는 The와 소문자로 시작하는 the가 있다면 단어를 병합하게 된다.
Stopword는 우리말로 하면 불용어라고 한다. 불용어는 검색어로서 가치가 없는 단어를 의미한다. stop에서는 동사나 명사를 주로 검색하기 때문에, 검색에 활용도가 떨어지는 단어를 제외하는 작업을 하게 된다.
snowball은 형태소 분석을 하면 기본 형태로 변환을 하게 된다. 기본적으로 가지고 있는 사전으로 jumps와 jumping을 모두 기본 형태인 jump로 변환한다.
누군가 Elasticsearch에 대해 묻는다면 반드시 답변에 역인덱스에 대해 들어가야 한다. 예로 들어 역인덱스 구조로 데이터를 저장하기 때문에 검색에 용이한 구조로 들어가 있다고 대답할 수 있어야 한다.
analyze API
analyze API는 임시로 애널라이저의 적용을 확인하는 도구이다.
실제 수행하는 게 아니므로 테스트로 사용한다.
GET _analyze
{
"text": "The quick brown fox jumps over the lazy dog",
"tokenizer": "whitespace"
}토크나이저를 진행했을 때의 결과를 보여준다.
토큰을 텀이라는 형태로 저장하는 것을 볼 수 있다.
여기에 추가로 토큰 필터를 걸어보도록 하자.
토크나이저는 유일하지만, 필터는 여러 개를 걸 수 있기 때문에 배열이다.
Filter
filter: lowercase
GET _analyze
{
"text": "The quick brown fox jumps over the lazy dog",
"tokenizer": "whitespace",
"filter": [
"lowercase"
]
}대문자 'The'가 소문자 'the'로 변경되었다.
filter: stop
GET _analyze
{
"text": "The quick brown fox jumps over the lazy dog",
"tokenizer": "whitespace",
"filter": [
"stop"
]
}The는 정관사이지만, 모든 정관사는 소문자로 되어 있기 때문에 대문자 The를 불용어로 없애고 싶으면 lowercase를 같이 적용시키면 된다.
filter: snow
형태소 분석을 해서 단어의 가장 원형을 남겨 놓고 저장을 한다.
jumps가 jump가 되고, lazy가 lazi로 변경된 것을 확인할 수 있다.
snowball 애널라이저
토큰 필터 중에 snoball 토큰 필터가 있고, whitespace 토크나이저 + lowercase, stop, snoball 토큰 필터를 세트로 합친 snowball 애널라이저가 있다.
기본적인 검색을 할 때에는 이 snowball 애널라이저를 사용한다.
GET _analyze
{
"text": "The quick brown fox jumps over the lazy dog",
"analyzer": "snowball"
}
인덱스 + 애널라이저 적용
생성된 인덱스에 애널라이저를 적용하여 실제로 저장해 보도록 하자.
Elasticsearch에서는 스키마라는 표현 대신에 매핑이라는 표현을 사용한다.
mapping API
GET my_english/_mappingmapping API를 사용하여 인덱스의 구조를 확인할 수 있다.
my_english 인덱스에는 message라는 프로퍼티가 1개 있으며, 이에 대한 정의를 하고 있다.
기본적으로 문자열을 저장하면 text type으로 저장된다.
정적 매핑과 동적 매핑
# 정적 매핑
PUT my_english2
# 동적 매핑
PUT my_english2
{
"mappings": {
"properties": {
"message": {
"type": "text",
"analyzer": "standard"
}
}
}
}Elasticsearch는 자동으로 매핑이 된다. 즉, 저장소의 규칙이 자동으로 생성된다. 이는 인덱스의 구조가 자동으로 생성된다고 이해하면 된다.
Oracle 또는 CSS 등에서 데이터를 수급하여 Elasticsearch에서 검색을 하게 된다. 이때 Elasticsearch가 들어가는 데이터에 따라서 동적으로 데이터 구조가 생성되는데, 이를 그냥 두면 안 된다.
나중에 검색을 할 때 데이터가 숫자, 텍스트, 날짜 중 어떤 자료형이냐에 따라서 검색 패턴이 달라지기 때문이다.
인덱스를 만들 때에는 이와 같이 어떤 데이터를 어떤 자료형으로 넣을 것이라는 매핑 작업이 필요하다.
snowball 정적 매핑
# 기존 인덱스 삭제
DELETE my_english3
# 정적 매핑: snowball
PUT my_english3
{
"mappings": {
"properties": {
"message": {
"type": "text",
"analyzer": "snowball"
}
}
}
}
# 영문 데이터
POST my_english3/_bulk
{"index":{"_id":1}}
{"message":"The quick brown fox"}
{"index":{"_id":2}}
{"message":"The quick brown fox jumps over the lazy dog"}
{"index":{"_id":3}}
{"message":"The quick brown fox jumps over the quick dog"}
{"index":{"_id":4}}
{"message":"Brown fox brown dog"}
{"index":{"_id":5}}
{"message":"Lazy jumping dog"}
# 검색
GET my_english3/_search
{
"query": {
"match": {
"message": "jump"
}
}
}snowball 애널라이즈로 저장되었기 때문에 jump로 검색하면 jumping, jumps 모두 찾아주는 것을 확인할 수 있다.
🌿Nori
형태소 분석기
영어 형태소 분석기는 snowball이며, 한글 형태소 분석기는 Nori로 ES 6.X에서부터 적용되었다.
Nori 설치
$ cd /usr/share/elasticsearchNori를 설치하기 위해 Elasticsearch 폴더로 이동한다.
$ sudo bin/elasticsearch-plugin install analysis-nori플러그인 명령어로 analysis-nori를 설치한다.
$ cd ~
$ sudo systemctl restart elasticsearch다시 홈 폴더로 이동한다.
그리고 플러그인을 실행시키기 위해 반드시 서비스를 재시작해야 한다.
nori_tokenizer
GET _analyze
{
"text": "동해물과 백두산이",
"tokenizer": "standard"
}GET _analyze
{
"text": "동해물과 백두산이",
"tokenizer": "nori_tokenizer"
}
my_nori 데이터 삽입
# my_nori
PUT my_nori
{
"settings": {
"analysis": {
"tokenizer": {
"nori_none": {
"type": "nori_tokenizer",
"decompound_mode": "none"
},
"nori_discard": {
"type": "nori_tokenizer",
"decompound_mode": "discard"
},
"nori_mixed": {
"type": "nori_tokenizer",
"decompound_mode": "mixed"
}
}
}
}
}
nori_tokenizer의 종류
GET my_nori/_analyze
{
"text": "백두산이",
"tokenizer": "nori_tokenizer"
}
GET my_nori/_analyze
{
"text": "백두산이",
"tokenizer": "nori_none"
}
GET my_nori/_analyze
{
"text": "백두산이",
"tokenizer": "nori_discard"
}
GET my_nori/_analyze
{
"text": "백두산이",
"tokenizer": "nori_mixed"
}검색에 따라 기본을 사용해도 되고, 경우에 따라 합성어를 쪼개지 않고 한 덩어리로 묶을 수도 있다.
nori_readingform
GET _analyze
{
"tokenizer": "nori_tokenizer",
"text": "春夏秋冬",
"filter": [
"nori_readingform"
]
}검색해야 할 대상 중에 한자가 많은 경우 nori_readingform 필터를 걸어 한글로 출력할 수 있다.