
🌿Elasticsearch 검색
Elasticsearch는 관계형 데이터베이스에 비해 다양하고 효과적인 검색 기능을 제공한다.
가장 주된 특징은 풀 텍스트 검색(Full Text Search)을 지원한다는 점이다.
누군가 Elasticsearch가 뭔지를 물어보면 풀 텍스트 검색을 지원하는 검색 엔진이라고 대답하면 된다.
QueryDSL
검색을 할 때에는 QueryDSL(Query Domain Specifin Language)을 사용한다. 이는 검색을 할 때 표현을 위한 언어로, 검색하는 환경에서 조건을 만드는 표현식 중 하나이다.
검색 대상
match_all 검색
GET <인덱스명>/_search검색은 Index를 대상으로 수행된다. 즉, Index가 다르면 검색을 따로 해야 한다.
match_all은 검색 방식 중에 하나로, 전체 Document를 찾아달라는 의미의 검색이다.
Multitenancy
멀티테넌시는 여러 개의 Index를 한 번에 묶어서 검색할 수 있는 기능이다.
Oracle로 치면 물리적으로 테이블이 분리되어 있지만, 합쳐서 결과 셋을 만들 때 사용하는 Union 같은 느낌이다.
여러 개의 분산되어 있는 인덱스를 묶어서 검색해야 할 때 사용할 수 있다.
Elasticsearch로 많이 하는 행동 중에 하나가 프로그램의 로그 파일을 분석하는 업무이다. 그런데 로그 파일의 특성상 logs-2023-01, logs-2023-02, logs-2023-03와 같이 날짜나 시간으로 파일을 만드는 게 일반적이다. 이때 인덱스가 분리되어 있기 때문에 합쳐야 하는 상황에서 다음의 방법을 사용한다.
1. 인덱스명을 연결하여 검색
GET logs-2023-01,logs-2023-02,logs-2023-03/_search
GET member,address/_search
2. 와일드카드로 검색
GET logs-*/_search공통적인 부분을 와일드카드로 처리하여 검색할 수 있다.
3. 모든 데이터를 검색
GET _all/_search모든 Index를 대상으로 검색하기 때문에 이 방법은 작업의 부하가 심하다.
멀티테넌시는 로그같이 시간 순으로 쌓이는 데이터에 적용하기 좋다.
🌿Full Text Search
Bulk API로 데이터 삽입
POST member/_bulk
{ "index" : { "_index" : "member", "_type" : "_doc", "_id" : 1 } }
{ "name" : "Isaac", "age": 22, "gender": "m", "address": "서울시 강남구 역삼동", "height": 171, "weight": 58}
{ "index" : { "_index" : "member", "_type" : "_doc", "_id" : 2 } }
{ "name" : "Sopia", "age": 25, "gender": "f", "address": "서울시 강남구 대치동", "height": 157, "weight": 45}
{ "index" : { "_index" : "member", "_type" : "_doc", "_id" : 3 } }
{ "name" : "Itsh", "age": 30, "gender": "m", "address": "서울시 강남구 압구정동", "height": 180, "weight": 77}
{ "index" : { "_index" : "member", "_type" : "_doc", "_id" : 4 } }
{ "name" : "Itsha", "age": 45, "gender": "m", "address": "서울시 강남구 청담동", "height": 184, "weight": 95}
{ "index" : { "_index" : "member", "_type" : "_doc", "_id" : 5 } }
{ "name" : "Paul", "age": 40, "gender": "m", "address": "서울시 강남구 신사동", "height": 178, "weight": 62}
{ "index" : { "_index" : "member", "_type" : "_doc", "_id" : 6 } }
{ "name" : "Noah", "age": 33, "gender": "m", "address": "서울시 강동구 명일동", "height": 176, "weight": 68}
{ "index" : { "_index" : "member", "_type" : "_doc", "_id" : 7 } }
{ "name" : "Abraham", "age": 27, "gender": "f", "address": "서울시 강동구 고덕동", "height": 152, "weight": 53}
{ "index" : { "_index" : "member", "_type" : "_doc", "_id" : 8 } }
{ "name" : "Jacob", "age": 32, "gender": "m", "address": "서울시 강동구 천호동", "height": 158, "weight": 66}
{ "index" : { "_index" : "member", "_type" : "_doc", "_id" : 9 } }
{ "name" : "Joseph", "age": 37, "gender": "m", "address": "서울시 강서구 등촌동", "height": 192, "weight": 78}
{ "index" : { "_index" : "member", "_type" : "_doc", "_id" : 10 } }
{ "name" : "Moses", "age": 28, "gender": "f", "address": "서울시 강서구 가양동", "height": 179, "weight": 71}
검색 방식
- URI 검색
- JSON Data Body 검색
URI 검색은 단순한 검색만 가능하므로 주된 검색으로는 JSON Data Body 검색 방식을 사용한다.
URI 검색
필드명을 표시하지 않고 검색
GET <도큐먼트>/_search?q=조건
GET member/_search
GET member/_search?q=m
GET member/_search?q=f
GET member/_search?q=강서구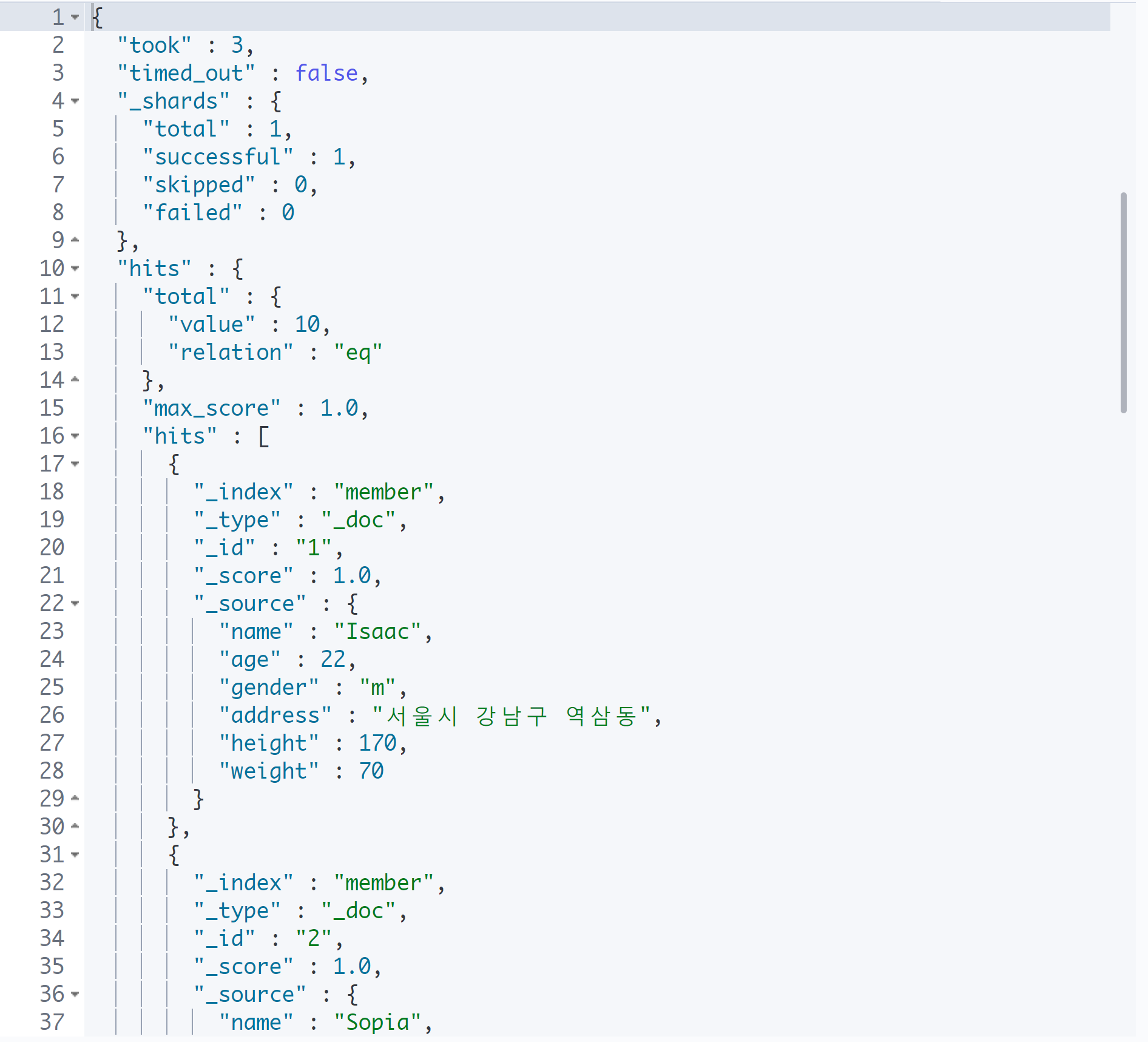
URI 검색은 _search 뒤에 쿼리 스트링을 넘긴다.
search를 하게 되면 결괏값 중에 hits가 있다. 그리고 hits 안에 또 다른 hits가 있다. 2번째 hits에서 배열인 Document를 보여주게 된다.
value는 검색하여 얻은 결과 개수이다. 10명을 넣었기 때문에 value는 10이다.
다중 조건 검색
GET member/_search?q=강서구 AND m
GET member/_search?q=강서구 OR f
GET member/_search?q=강서구 NOT f
GET member/_search?q=강서구 AND m OR Sopia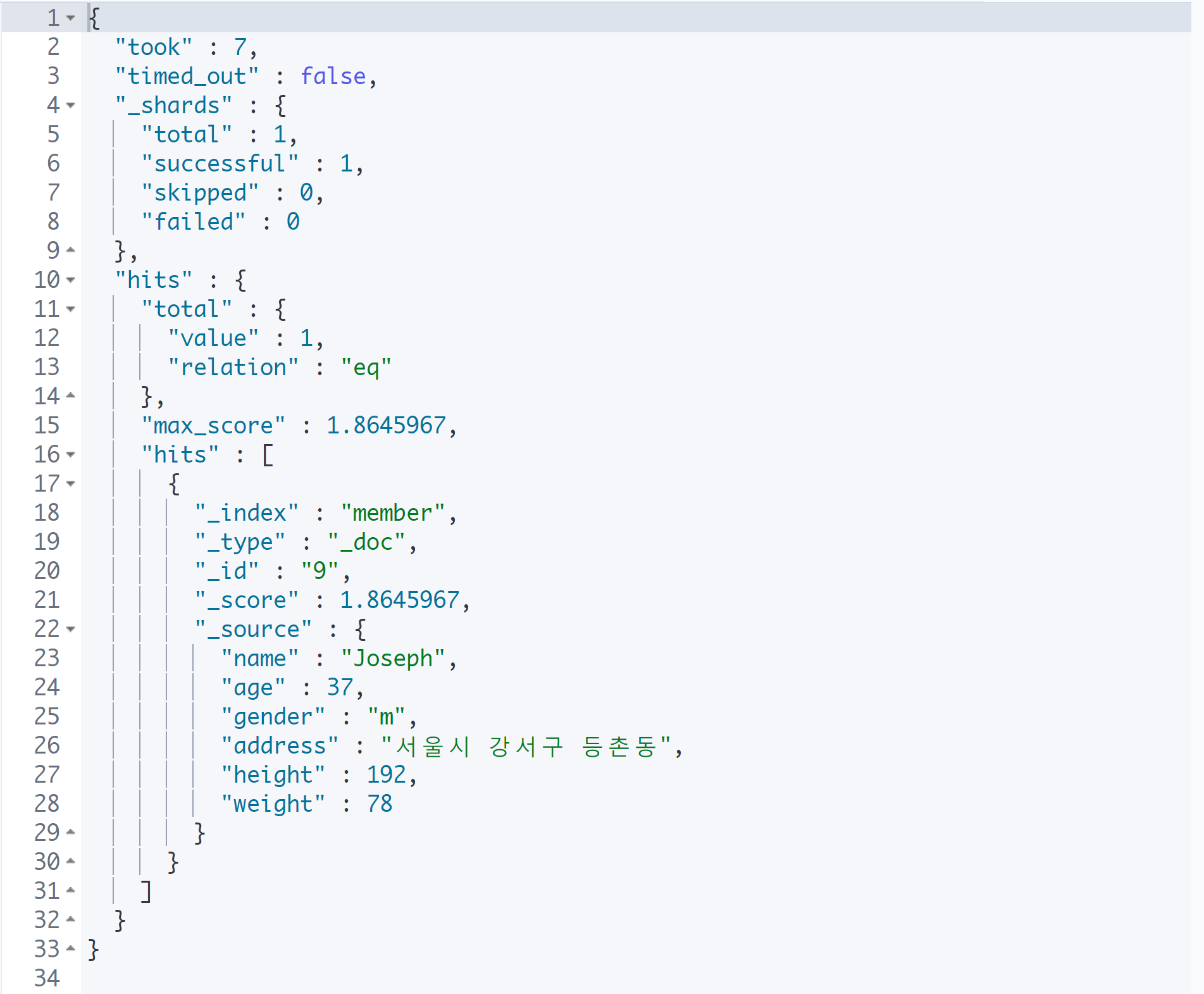
기본 URI에서는 띄어쓰기를 하면 안 되는데 검색을 할 때에는 띄어쓰기를 한다.
AND 혹은 OR로 조건을 묶을 수 있으며, 부정 연산자를 사용할 수도 있다.
필드가 정해져 있지 않기 때문에 현재 원하지 않는 검색 결과도 얻을 수 있는 상태이다.
필드명을 표시하여 검색
GET member/_search?q=address:강서구
GET member/_search?q=address:강서구 AND gender:m필드명을 표시하여 검색하면 데이터가 복잡할 때 검색에 용이하게 사용할 수 있다.
URI 검색은 이와 같이 간단하게 키워드로 검색할 때 사용한다.
JSON Data Body 검색
데이터 본문 검색을 의미하며, 검색한 쿼리를 전송할 데이터 본문에 넣어서 입력하는 방식이다.
Elasticsearch로 검색하는 방법으로 URI로 검색하는 방법과 JSON Body Data로 검색하는 방법이 있다.
URI로 검색하는 방법은 q라는 이름의 파라미터로 필드명을 이용해서 검색하며, 간단한 검색만 가능하므로 잘 사용하지 않고, JSON Body Data로 검색을 많이 하게 된다.
Body Search
GET <도큐먼트>/_search
{
"query": {
"쿼리의 종류": {
세부사항
}
}
}
match 쿼리
GET <도큐먼트>/_search
{
"query": {
"match": {
"<필드명>": "<검색어>"
}
}
}
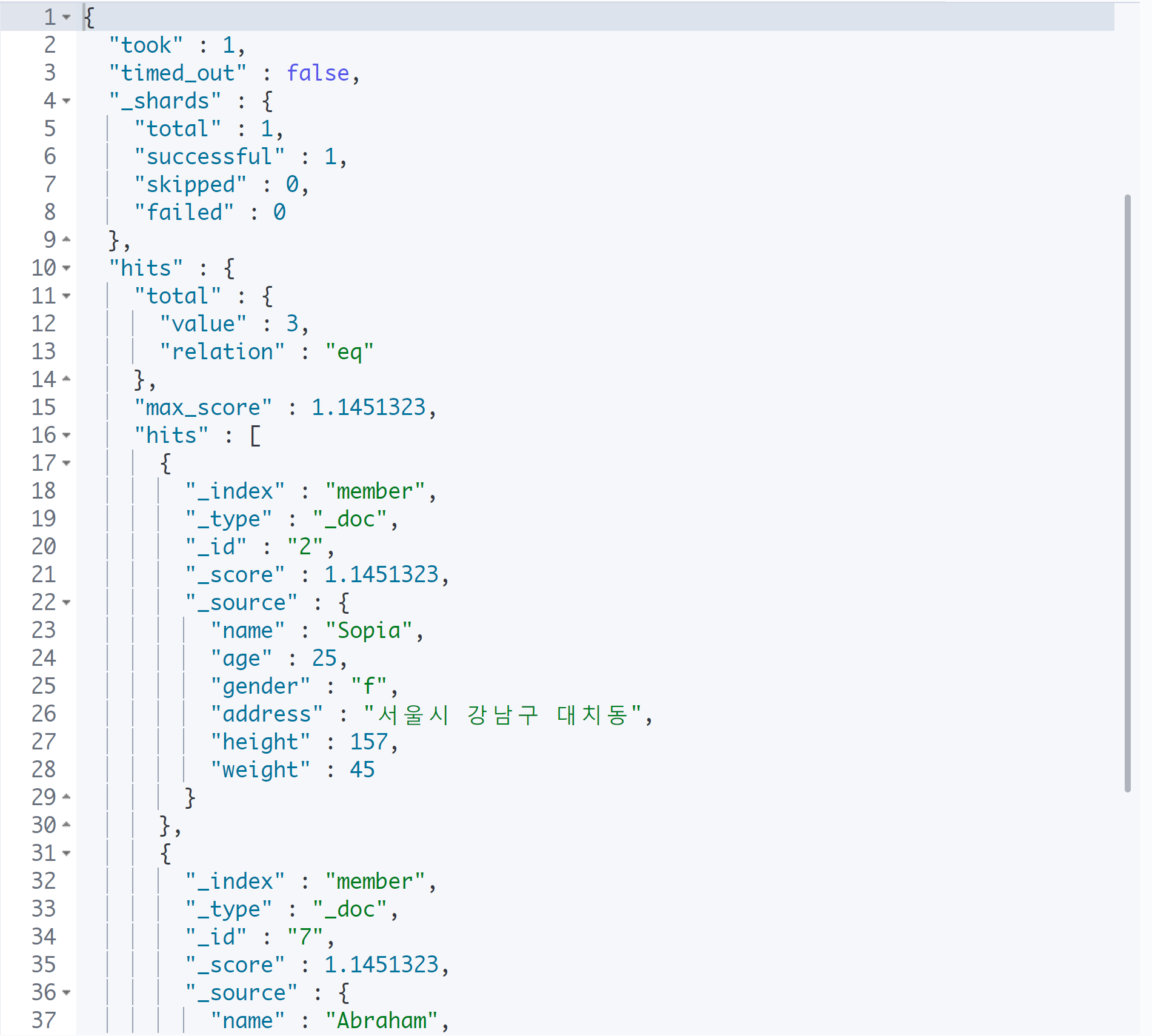
GET member/_search
{
"query": {
"match": {
"gender": "f"
}
}
}
검색에 가장 많이 사용하는 쿼리 중 하나가 match 쿼리이다.
match 쿼리는 부분 검색을 할 수 있게 해 주며, 사용하기 위해서는 match 쿼리를 쿼리의 종류에 작성하면 된다.
실제로는 부분 검색이라고 부르지 않고, Full Text Search 혹은 Full Test Query라고 부른다. 이는 전체 내용이 아닌 키워드로 검색하더라도 검색을 할 수 있는 방법이다.
이때, 숫자와 날짜는 정확히 일치하는 값만을 검색하게 된다. 따라서 나이가 24인 사람을 검색한다고 해서 240살인 사람이 검색되진 않는다.
relation은 검색 방식을 의미한다. 현재는 equal 즉, 같은 값을 찾는 방식을 사용하여 검색한 것이다.
토큰 검색
- 토큰 == 텀(Term)
Full Text Search는 토큰(공백으로 구분된 단어) 검색을 지원한다.
즉, Elasticsearch는 텀 검색을 지원한다.
Bulk API로 데이터 삽입
# 영문 데이터
POST my_english/_bulk
{"index":{"_id":1}}
{"message":"The quick brown fox"}
{"index":{"_id":2}}
{"message":"The quick brown fox jumps over the lazy dog"}
{"index":{"_id":3}}
{"message":"The quick brown fox jumps over the quick dog"}
{"index":{"_id":4}}
{"message":"Brown fox brown dog"}
{"index":{"_id":5}}
{"message":"Lazy jumping dog"}
# 한글 데이터
POST my_korean/_bulk
{"index":{"_id":1}}
{"message":"지붕 위의 갈색 닭"}
{"index":{"_id":2}}
{"message":"지붕 위의 갈색 닭 그리고 밑에 검은색 강아지"}
{"index":{"_id":3}}
{"message":"지붕 위의 갈색 우는 닭 그리고 밑에 갈색 게으른 강아지"}
{"index":{"_id":4}}
{"message":"갈색 게으른 바보 강아지 옆에 빨간색 닭"}
{"index":{"_id":5}}
{"message":"졸고 있는 갈색 강아지"}
message 필드(컬럼)을 정의하고, 문장을 데이터로 삽입하였다.
기존 인덱스 확인
# 기존 인덱스 확인
GET _cat/indices
GET _cat/indices?v
indicies?v로 검색하면 헤더를 검색 결과와 함께 출력한다.
도큐먼트(데이터) 확인
# 도큐먼트(데이터) 확인
# 인덱스 정보
GET address
# 검색 API > 모든 도큐먼트 정보
GET address/_search
# 특정 도큐먼트
GET address/_doc/1
# 특정 도큐먼트의 순수 데이터
GET address/_source/1도큐먼트를 검색할 때 _doc 고정자를 붙이면 document에 대한 모든 정보를 다 가져온다.
특정 도큐먼트의 순수 데이터를 가져오고 싶다면 _doc가 아닌 _source를 붙이면 된다. 하지만 데이터를 검색할 때에는 순수 데이터뿐만 아니라 데이터 구조를 함께 확인할 때가 많기 때문에 _doc를 더 많이 사용한다.
GET address/_search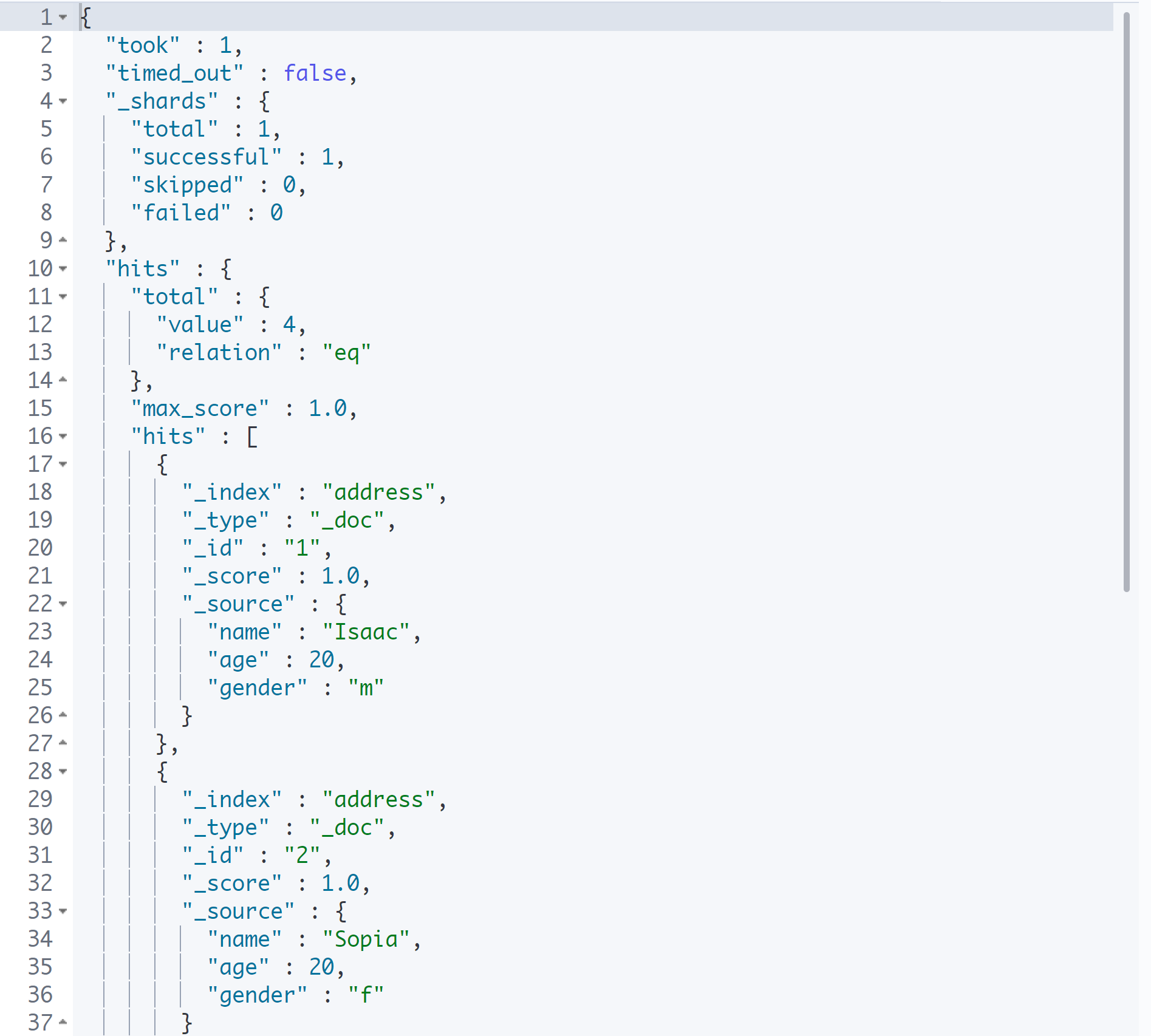
hits의 total value가 검색한 결과의 개수이고, 실제 데이터는 그 아래의 hits 안에 오브젝트 형태로 들어 있다.
다시 말하면 각각은 JSON 객체 하나이며, DB로 치면 레코드 한 줄을 의미한다.
match_all
# match all
GET member/_search
{
"query": {
"match_all": {}
}
}match_all은 조건 없이 해당 Index의 모든 Document를 검색하고 반환한다.
검색 시 _search 쿼리를 넣지 않으면 자동으로 match_all을 적용한다.
만약 match_all을 명시적으로 하고 싶다면 Data Body를 만들고 match_all로 검색하면 된다.
조건 검색
OR 조건 검색
# OR 조건
GET my_english/_search
{
"query": {
"match": {
"message": "quick dog"
}
}
}
GET my_korean/_search
{
"query": {
"match": {
"message": "갈색 강아지"
}
}
}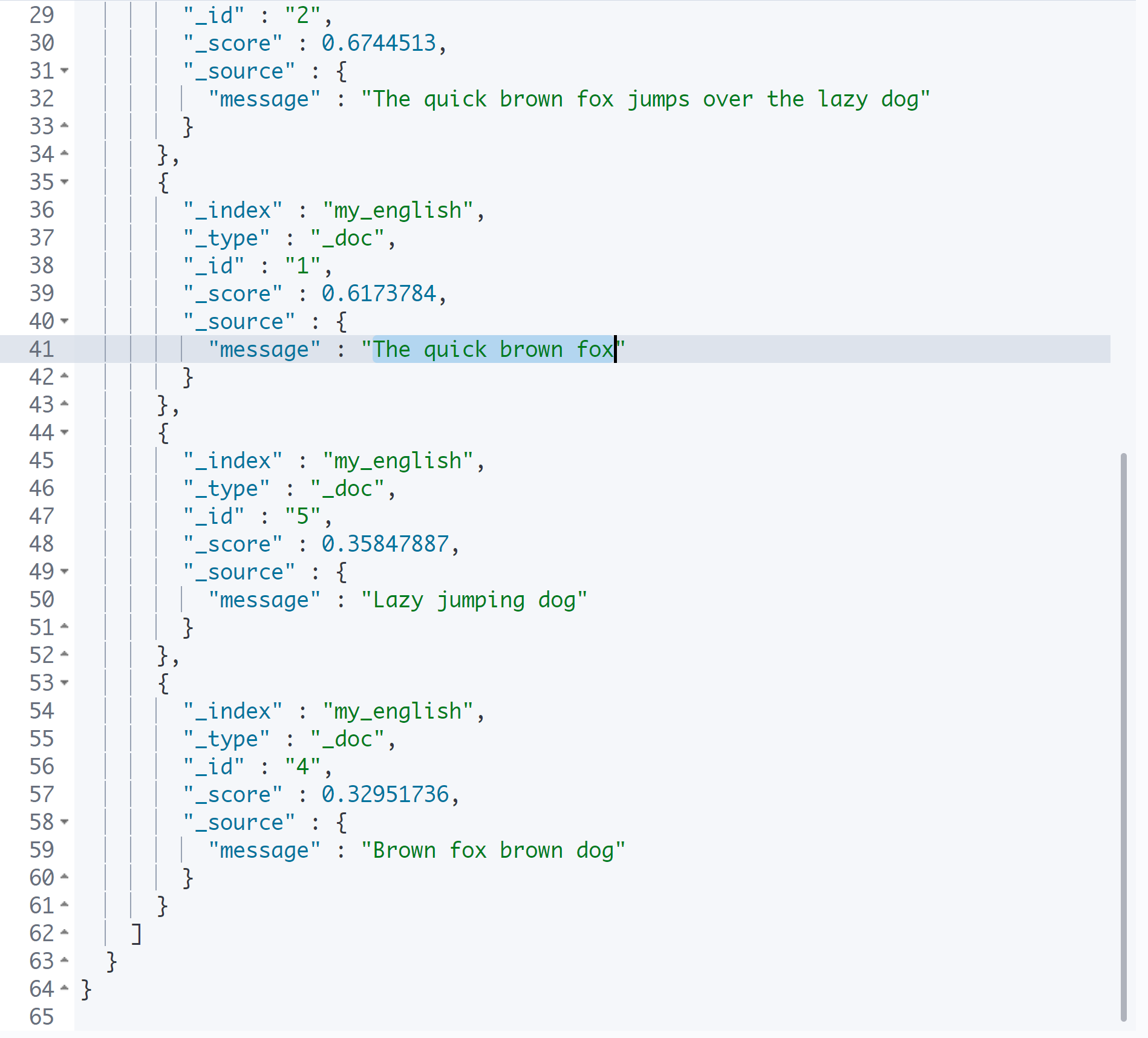
두 개 이상의 term을 검색하면 자동으로 OR 연산을 한다.
즉, 위 검색은 my_english에서 quick이 들어 있거나 dog이 들어 있는 것을 찾아달라는 의미가 되며, my_korean에서 갈색이 들어 있거나 강아지가 들어 있는 것을 찾아달라는 의미가 된다.
이때 검색하는 순서도 굉장히 중요하다. 검색 결과가 검색 순서에 따라서 달라지기 때문이다.
AND 조건 검색
# AND 조건
GET my_english/_search
{
"query": {
"match": {
"message": {
"query": "quick dog",
"operator": "or"
}
}
}
}
GET my_korean/_search
{
"query": {
"match": {
"message": {
"query": "갈색 강아지",
"operator": "and"
}
}
}
}
AND 조건 검색을 할 때에는 바로 데이터를 검색하지 않고, 또 하나의 블럭을 잡아서 query를 하나 더 적는다. 그리고 여기에 검색어를 넣는다.
보이지 않는 속성으로 opeator가 존재한다. operator를 or 또는 and로 지정하여 검색 조건으로 지정할 수 있다.
match_phrase
phrase(구)는 동사 이외의 낱말을 2개 이상으로 구성된 문장을 의미한다.
"갈색 강아지"와 "갈색강아지"는 다르다. 전자는 '구'이고, 후자는 '텀'으로 책정한다.
match_phrase는 구만 따로 검색을 하는 방식으로, 검색어를 온전한 그대로 검색한다.
# match_phrase
GET my_english/_search
{
"query": {
"match_phrase": {
"필드명": "검색어"
}
}
}
GET my_english/_search
{
"query": {
"match_phrase": {
"message": "lazy dog"
}
}
}
GET my_korean/_search
{
"query": {
"match_phrase": {
"message": "갈색 강아지"
}
}
}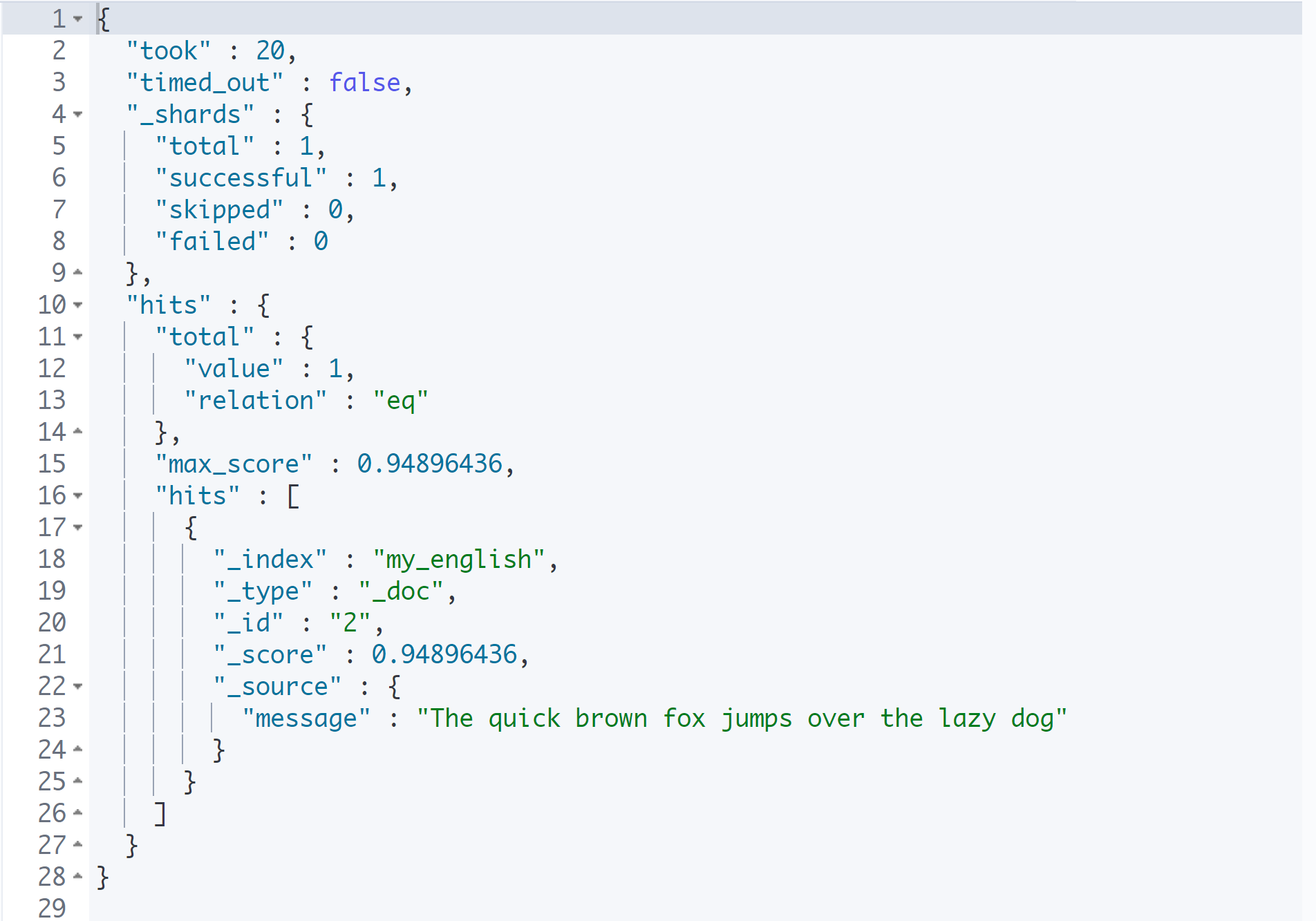
검색 결과로 "lazy dog"이 온전하게 있는 문장을 찾는다.
보다 특정하고 정확한 검색 결과를 얻고 싶을 때 match_phrase를 사용한다.
slop
GET my_english/_search
{
"query": {
"match_phrase": {
"message": {
"query": "lazy dog",
"slop": 1
}
}
}
}
GET my_korean/_search
{
"query": {
"match_phrase": {
"message": {
"query": "갈색 강아지",
"slop": 1
}
}
}
}
match_phrase에서만 사용할 수 있는 slop 옵션이 있다.
slop은 뭔가 비우거나 덜어낸다는 뜻이며, 텀의 개수로 사용된다 된다.
slop 옵션을 주면 저장된 숫자 만큼 단어 사이에 다른 단어가 끼어드는 것을 허용한다는 뜻이다. 이를 사용하면 검색할 수 있는 범위가 굉장히 늘어나게 된다.
- where item lick '%아이폰 케이스%'
- where item lisk '%아이폰%' or itme like '%케이스%'
- where item lisk '%아이폰%케이스%'
slop 옵션으로 검색하는 건 3번째 방법으로 검색하는 방법과 같다.
Bool Query
#Bool Query
GET <인덱스명>/_search
{
"query": {
"bool": {
"must": [
{쿼리}, {쿼리}, ..
]
"must_not": [
{쿼리}, {쿼리}, ..
]
"should": [
{쿼리}, {쿼리}, ..
]
"filter": [
{쿼리}, {쿼리}, ..
]
}
}
}Bool Query는 Bool 복합 쿼리라고도 한다.
여러 쿼리를 조합하는 용도로 사용한다.
상위에서는 bool 쿼리를 작성하고, 하위에서는 다른 쿼리를 작성하여 조합하는 방식으로 많이 사용한다.
인자
- must: 쿼리가 참인 문서를 반환한다.
- must_not: 쿼리가 거짓인 문서를 반환한다.
- should: 검색 결과 중 해당 쿼리 결과 점수를 높인다.
- filter: 쿼리가 참인 문서를 반환, 점수를 계산하지 않기 때문에 must보다 속도가 빠르다.
Bool Query 자체는 4개의 인자를 가지고 있어서 인자들을 가지고 조합해 나간다.
'quick' + 'lazy dog'
# 'quick' + 'lazy dog'
GET my_english/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"message": "quick"
}
},
{
"match_phrase": {
"message": "lazy dog"
}
}
]
}
}
}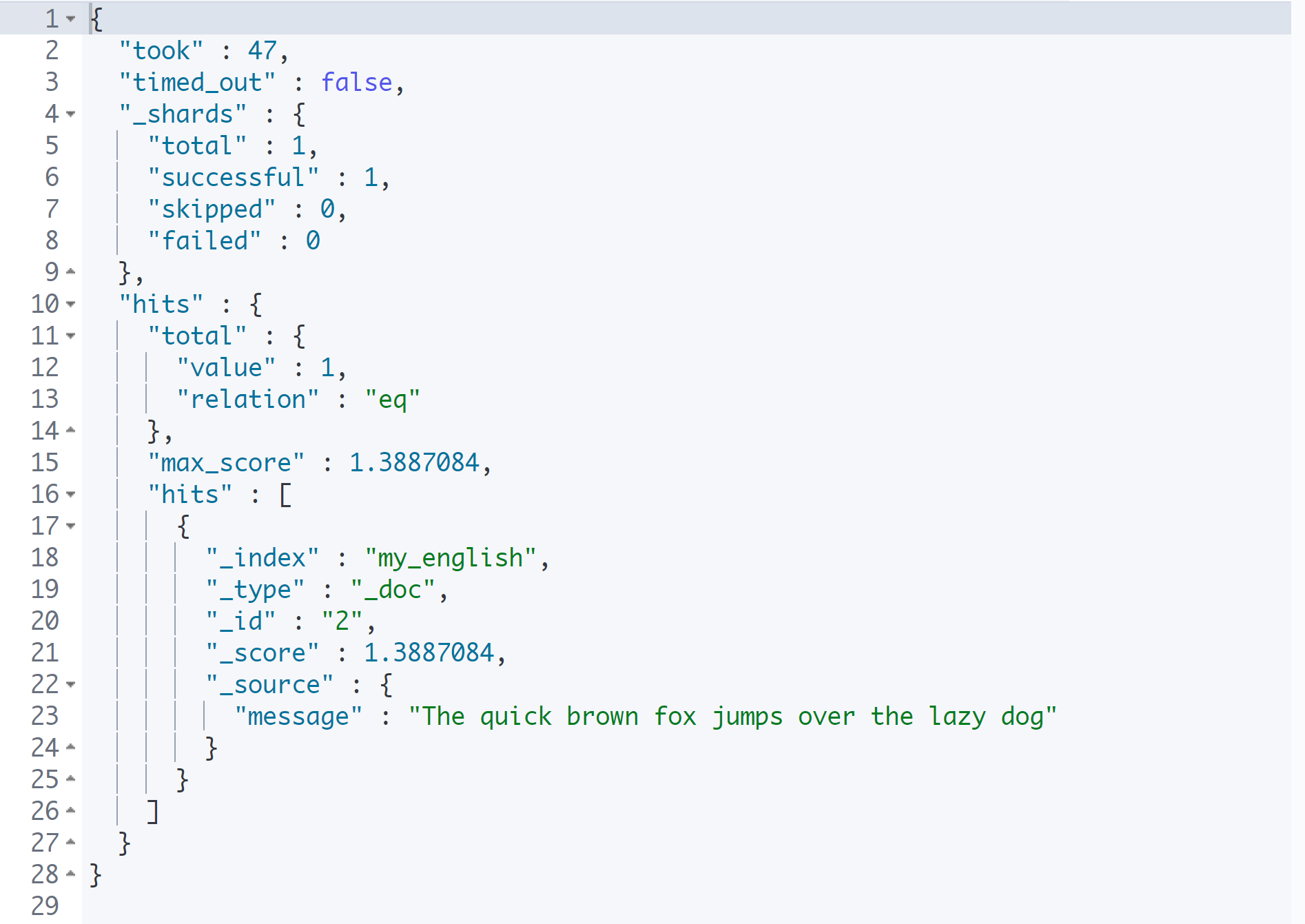
'quick', 'lazy dog' 둘 다 포함된 문서를 검색하려고 한다.
'quick'은 단어로 찾고, 'lazy dog'은 구로 찾고 싶다. 그러면 'quick'은 match로 찾으면 되고, 'lazy dog'은 match_phrase로 검색해야 한다.
현재 찾고자 하는 검색이 종류가 다른 검색을 동시에 해야 하는 상황이다. 이때 Bool Query를 사용한다.
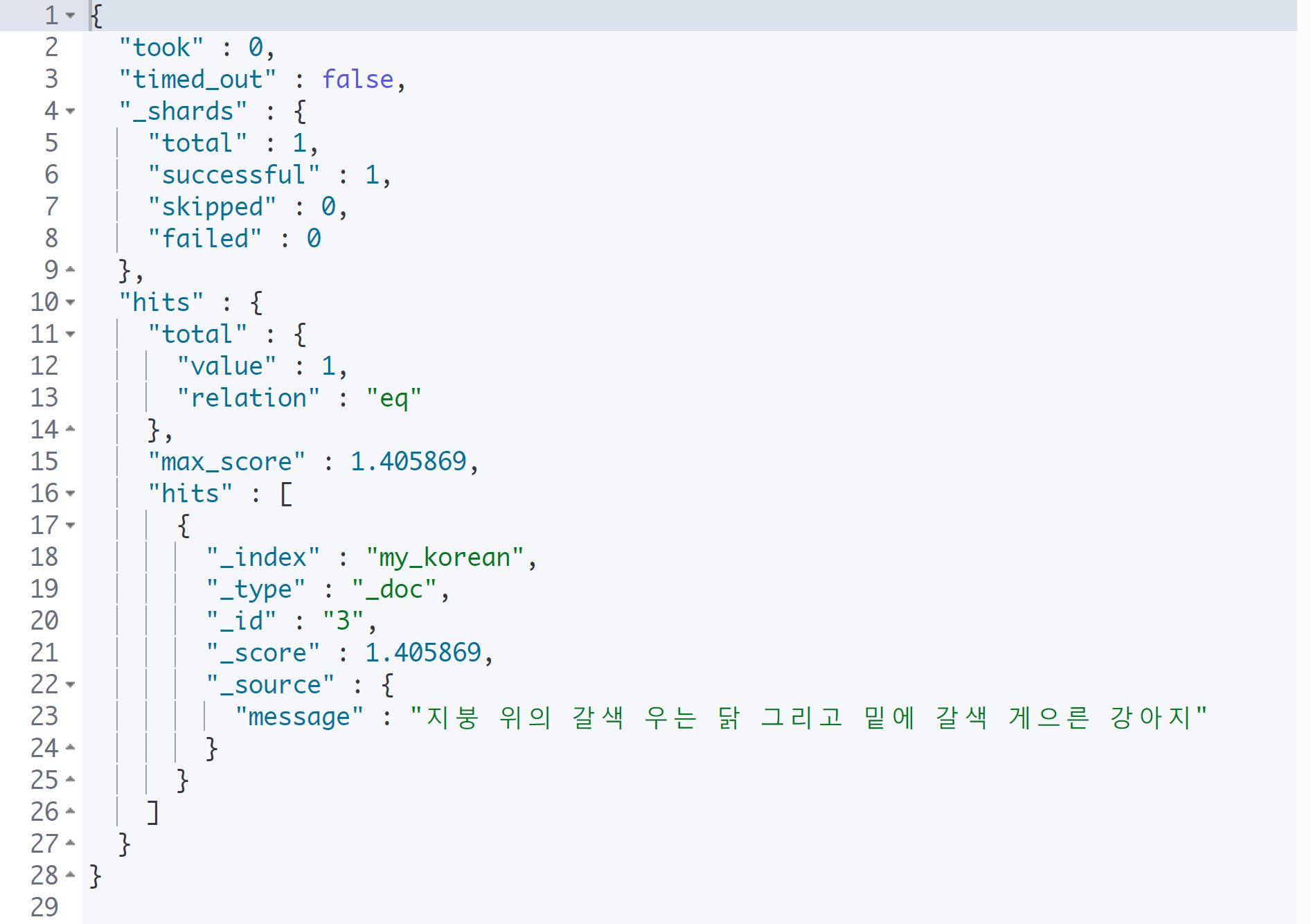
'지붕 + '게으른 강아지'
# '지붕' + '게으른 강아지'
GET my_korean/_search
{
"query": {
"match": {
"message": {
"query": "지붕 게으른 강아지",
"operator": "and"
}
}
}
}
GET my_korean/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"message": "지붕"
}
},
{
"match_phrase": {
"message": "게으른 강아지"
}
}
]
}
}
}
slop 옵션 사용
GET my_korean/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"message": "지붕"
}
},
{
"match_phrase": {
"message": {
"query": "갈색 닭",
"slop": 1
}
}
}
]
}
}
}
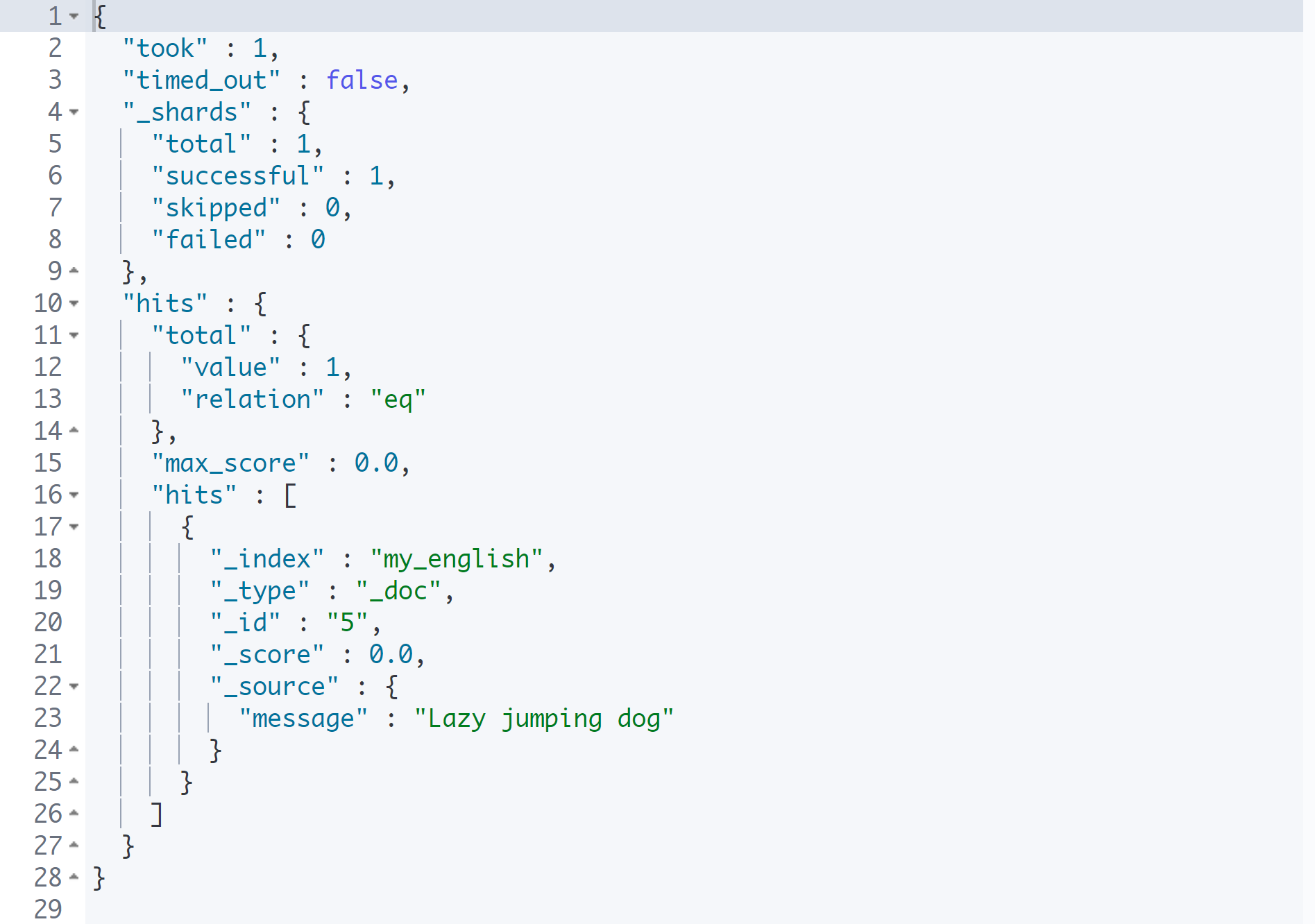
must_not
'quick'과 'brown dog'이 모두 포함되지 않은 문서를 검색해 보도록 하자.
GET my_english/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"message": "quick"
}
},
{
"match_phrase": {
"message": "brown dog"
}
}
]
}
}
}
여러 개의 배열
GET my_english/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"message": "quick"
}
}
],
"must": [
{
"match": {
"message": "dog"
}
}
]
}
}
}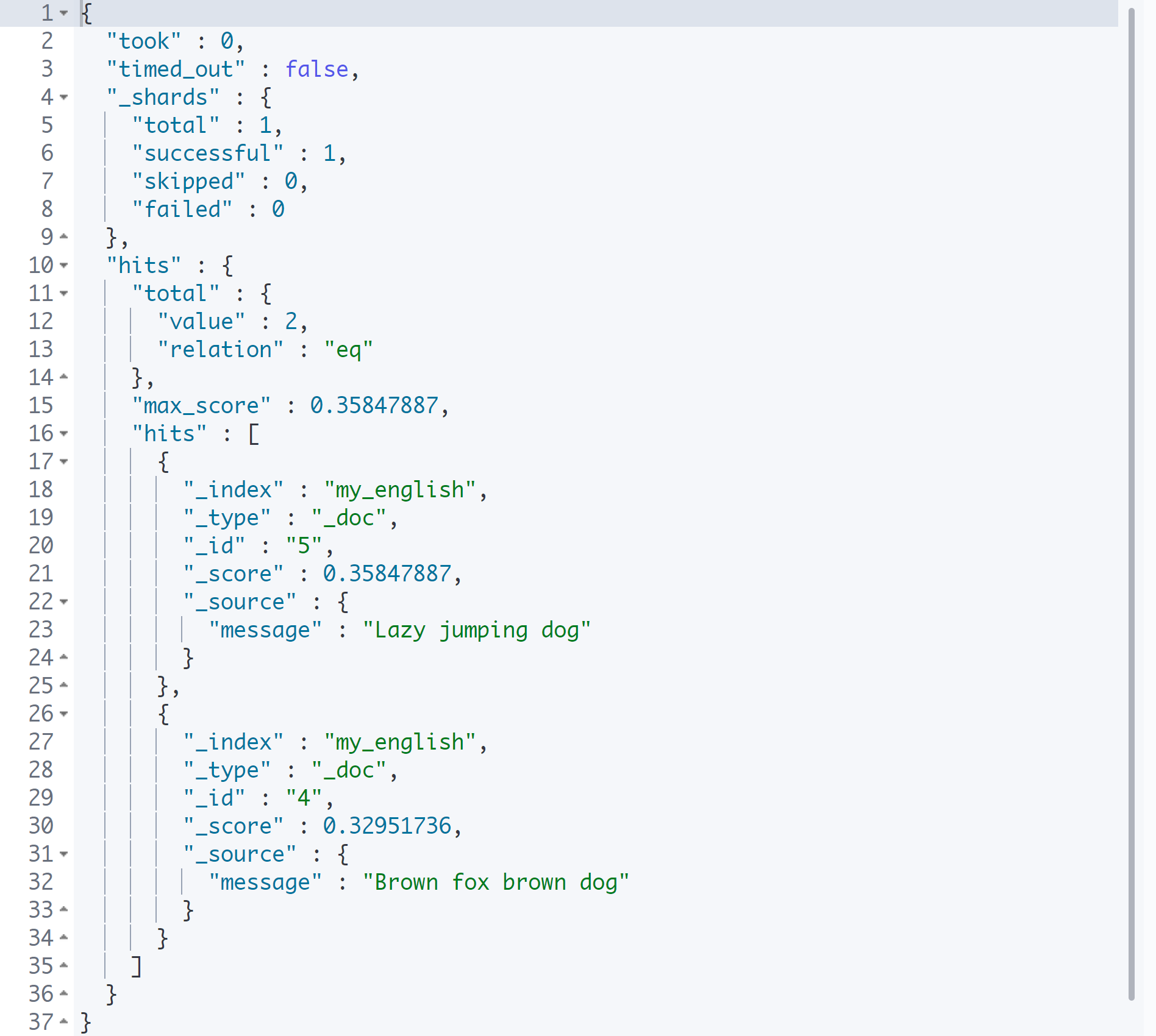
Bool 쿼리 안에 여러 개의 배열로 검색할 수도 있다.
'남자' + '강남' 이외의 거주
# '남자' + '강남' 이외의 거주
GET member/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"gender": "m"
}
}
],
"must_not": [
{
"match": {
"address": "강남구"
}
}
]
}
}
}

🌿Elasticsearch 검색
Elasticsearch는 관계형 데이터베이스에 비해 다양하고 효과적인 검색 기능을 제공한다.
가장 주된 특징은 풀 텍스트 검색(Full Text Search)을 지원한다는 점이다.
누군가 Elasticsearch가 뭔지를 물어보면 풀 텍스트 검색을 지원하는 검색 엔진이라고 대답하면 된다.
QueryDSL
검색을 할 때에는 QueryDSL(Query Domain Specifin Language)을 사용한다. 이는 검색을 할 때 표현을 위한 언어로, 검색하는 환경에서 조건을 만드는 표현식 중 하나이다.
검색 대상
match_all 검색
GET <인덱스명>/_search검색은 Index를 대상으로 수행된다. 즉, Index가 다르면 검색을 따로 해야 한다.
match_all은 검색 방식 중에 하나로, 전체 Document를 찾아달라는 의미의 검색이다.
Multitenancy
멀티테넌시는 여러 개의 Index를 한 번에 묶어서 검색할 수 있는 기능이다.
Oracle로 치면 물리적으로 테이블이 분리되어 있지만, 합쳐서 결과 셋을 만들 때 사용하는 Union 같은 느낌이다.
여러 개의 분산되어 있는 인덱스를 묶어서 검색해야 할 때 사용할 수 있다.
Elasticsearch로 많이 하는 행동 중에 하나가 프로그램의 로그 파일을 분석하는 업무이다. 그런데 로그 파일의 특성상 logs-2023-01, logs-2023-02, logs-2023-03와 같이 날짜나 시간으로 파일을 만드는 게 일반적이다. 이때 인덱스가 분리되어 있기 때문에 합쳐야 하는 상황에서 다음의 방법을 사용한다.
1. 인덱스명을 연결하여 검색
GET logs-2023-01,logs-2023-02,logs-2023-03/_search
GET member,address/_search
2. 와일드카드로 검색
GET logs-*/_search공통적인 부분을 와일드카드로 처리하여 검색할 수 있다.
3. 모든 데이터를 검색
GET _all/_search모든 Index를 대상으로 검색하기 때문에 이 방법은 작업의 부하가 심하다.
멀티테넌시는 로그같이 시간 순으로 쌓이는 데이터에 적용하기 좋다.
🌿Full Text Search
Bulk API로 데이터 삽입
POST member/_bulk
{ "index" : { "_index" : "member", "_type" : "_doc", "_id" : 1 } }
{ "name" : "Isaac", "age": 22, "gender": "m", "address": "서울시 강남구 역삼동", "height": 171, "weight": 58}
{ "index" : { "_index" : "member", "_type" : "_doc", "_id" : 2 } }
{ "name" : "Sopia", "age": 25, "gender": "f", "address": "서울시 강남구 대치동", "height": 157, "weight": 45}
{ "index" : { "_index" : "member", "_type" : "_doc", "_id" : 3 } }
{ "name" : "Itsh", "age": 30, "gender": "m", "address": "서울시 강남구 압구정동", "height": 180, "weight": 77}
{ "index" : { "_index" : "member", "_type" : "_doc", "_id" : 4 } }
{ "name" : "Itsha", "age": 45, "gender": "m", "address": "서울시 강남구 청담동", "height": 184, "weight": 95}
{ "index" : { "_index" : "member", "_type" : "_doc", "_id" : 5 } }
{ "name" : "Paul", "age": 40, "gender": "m", "address": "서울시 강남구 신사동", "height": 178, "weight": 62}
{ "index" : { "_index" : "member", "_type" : "_doc", "_id" : 6 } }
{ "name" : "Noah", "age": 33, "gender": "m", "address": "서울시 강동구 명일동", "height": 176, "weight": 68}
{ "index" : { "_index" : "member", "_type" : "_doc", "_id" : 7 } }
{ "name" : "Abraham", "age": 27, "gender": "f", "address": "서울시 강동구 고덕동", "height": 152, "weight": 53}
{ "index" : { "_index" : "member", "_type" : "_doc", "_id" : 8 } }
{ "name" : "Jacob", "age": 32, "gender": "m", "address": "서울시 강동구 천호동", "height": 158, "weight": 66}
{ "index" : { "_index" : "member", "_type" : "_doc", "_id" : 9 } }
{ "name" : "Joseph", "age": 37, "gender": "m", "address": "서울시 강서구 등촌동", "height": 192, "weight": 78}
{ "index" : { "_index" : "member", "_type" : "_doc", "_id" : 10 } }
{ "name" : "Moses", "age": 28, "gender": "f", "address": "서울시 강서구 가양동", "height": 179, "weight": 71}
검색 방식
- URI 검색
- JSON Data Body 검색
URI 검색은 단순한 검색만 가능하므로 주된 검색으로는 JSON Data Body 검색 방식을 사용한다.
URI 검색
필드명을 표시하지 않고 검색
GET <도큐먼트>/_search?q=조건
GET member/_search
GET member/_search?q=m
GET member/_search?q=f
GET member/_search?q=강서구URI 검색은 _search 뒤에 쿼리 스트링을 넘긴다.
search를 하게 되면 결괏값 중에 hits가 있다. 그리고 hits 안에 또 다른 hits가 있다. 2번째 hits에서 배열인 Document를 보여주게 된다.
value는 검색하여 얻은 결과 개수이다. 10명을 넣었기 때문에 value는 10이다.
다중 조건 검색
GET member/_search?q=강서구 AND m
GET member/_search?q=강서구 OR f
GET member/_search?q=강서구 NOT f
GET member/_search?q=강서구 AND m OR Sopia기본 URI에서는 띄어쓰기를 하면 안 되는데 검색을 할 때에는 띄어쓰기를 한다.
AND 혹은 OR로 조건을 묶을 수 있으며, 부정 연산자를 사용할 수도 있다.
필드가 정해져 있지 않기 때문에 현재 원하지 않는 검색 결과도 얻을 수 있는 상태이다.
필드명을 표시하여 검색
GET member/_search?q=address:강서구
GET member/_search?q=address:강서구 AND gender:m필드명을 표시하여 검색하면 데이터가 복잡할 때 검색에 용이하게 사용할 수 있다.
URI 검색은 이와 같이 간단하게 키워드로 검색할 때 사용한다.
JSON Data Body 검색
데이터 본문 검색을 의미하며, 검색한 쿼리를 전송할 데이터 본문에 넣어서 입력하는 방식이다.
Elasticsearch로 검색하는 방법으로 URI로 검색하는 방법과 JSON Body Data로 검색하는 방법이 있다.
URI로 검색하는 방법은 q라는 이름의 파라미터로 필드명을 이용해서 검색하며, 간단한 검색만 가능하므로 잘 사용하지 않고, JSON Body Data로 검색을 많이 하게 된다.
Body Search
GET <도큐먼트>/_search
{
"query": {
"쿼리의 종류": {
세부사항
}
}
}
match 쿼리
GET <도큐먼트>/_search
{
"query": {
"match": {
"<필드명>": "<검색어>"
}
}
}
GET member/_search
{
"query": {
"match": {
"gender": "f"
}
}
}검색에 가장 많이 사용하는 쿼리 중 하나가 match 쿼리이다.
match 쿼리는 부분 검색을 할 수 있게 해 주며, 사용하기 위해서는 match 쿼리를 쿼리의 종류에 작성하면 된다.
실제로는 부분 검색이라고 부르지 않고, Full Text Search 혹은 Full Test Query라고 부른다. 이는 전체 내용이 아닌 키워드로 검색하더라도 검색을 할 수 있는 방법이다.
이때, 숫자와 날짜는 정확히 일치하는 값만을 검색하게 된다. 따라서 나이가 24인 사람을 검색한다고 해서 240살인 사람이 검색되진 않는다.
relation은 검색 방식을 의미한다. 현재는 equal 즉, 같은 값을 찾는 방식을 사용하여 검색한 것이다.
토큰 검색
- 토큰 == 텀(Term)
Full Text Search는 토큰(공백으로 구분된 단어) 검색을 지원한다.
즉, Elasticsearch는 텀 검색을 지원한다.
Bulk API로 데이터 삽입
# 영문 데이터
POST my_english/_bulk
{"index":{"_id":1}}
{"message":"The quick brown fox"}
{"index":{"_id":2}}
{"message":"The quick brown fox jumps over the lazy dog"}
{"index":{"_id":3}}
{"message":"The quick brown fox jumps over the quick dog"}
{"index":{"_id":4}}
{"message":"Brown fox brown dog"}
{"index":{"_id":5}}
{"message":"Lazy jumping dog"}
# 한글 데이터
POST my_korean/_bulk
{"index":{"_id":1}}
{"message":"지붕 위의 갈색 닭"}
{"index":{"_id":2}}
{"message":"지붕 위의 갈색 닭 그리고 밑에 검은색 강아지"}
{"index":{"_id":3}}
{"message":"지붕 위의 갈색 우는 닭 그리고 밑에 갈색 게으른 강아지"}
{"index":{"_id":4}}
{"message":"갈색 게으른 바보 강아지 옆에 빨간색 닭"}
{"index":{"_id":5}}
{"message":"졸고 있는 갈색 강아지"}message 필드(컬럼)을 정의하고, 문장을 데이터로 삽입하였다.
기존 인덱스 확인
# 기존 인덱스 확인
GET _cat/indices
GET _cat/indices?vindicies?v로 검색하면 헤더를 검색 결과와 함께 출력한다.
도큐먼트(데이터) 확인
# 도큐먼트(데이터) 확인
# 인덱스 정보
GET address
# 검색 API > 모든 도큐먼트 정보
GET address/_search
# 특정 도큐먼트
GET address/_doc/1
# 특정 도큐먼트의 순수 데이터
GET address/_source/1도큐먼트를 검색할 때 _doc 고정자를 붙이면 document에 대한 모든 정보를 다 가져온다.
특정 도큐먼트의 순수 데이터를 가져오고 싶다면 _doc가 아닌 _source를 붙이면 된다. 하지만 데이터를 검색할 때에는 순수 데이터뿐만 아니라 데이터 구조를 함께 확인할 때가 많기 때문에 _doc를 더 많이 사용한다.
GET address/_searchhits의 total value가 검색한 결과의 개수이고, 실제 데이터는 그 아래의 hits 안에 오브젝트 형태로 들어 있다.
다시 말하면 각각은 JSON 객체 하나이며, DB로 치면 레코드 한 줄을 의미한다.
match_all
# match all
GET member/_search
{
"query": {
"match_all": {}
}
}match_all은 조건 없이 해당 Index의 모든 Document를 검색하고 반환한다.
검색 시 _search 쿼리를 넣지 않으면 자동으로 match_all을 적용한다.
만약 match_all을 명시적으로 하고 싶다면 Data Body를 만들고 match_all로 검색하면 된다.
조건 검색
OR 조건 검색
# OR 조건
GET my_english/_search
{
"query": {
"match": {
"message": "quick dog"
}
}
}
GET my_korean/_search
{
"query": {
"match": {
"message": "갈색 강아지"
}
}
}두 개 이상의 term을 검색하면 자동으로 OR 연산을 한다.
즉, 위 검색은 my_english에서 quick이 들어 있거나 dog이 들어 있는 것을 찾아달라는 의미가 되며, my_korean에서 갈색이 들어 있거나 강아지가 들어 있는 것을 찾아달라는 의미가 된다.
이때 검색하는 순서도 굉장히 중요하다. 검색 결과가 검색 순서에 따라서 달라지기 때문이다.
AND 조건 검색
# AND 조건
GET my_english/_search
{
"query": {
"match": {
"message": {
"query": "quick dog",
"operator": "or"
}
}
}
}
GET my_korean/_search
{
"query": {
"match": {
"message": {
"query": "갈색 강아지",
"operator": "and"
}
}
}
}AND 조건 검색을 할 때에는 바로 데이터를 검색하지 않고, 또 하나의 블럭을 잡아서 query를 하나 더 적는다. 그리고 여기에 검색어를 넣는다.
보이지 않는 속성으로 opeator가 존재한다. operator를 or 또는 and로 지정하여 검색 조건으로 지정할 수 있다.
match_phrase
phrase(구)는 동사 이외의 낱말을 2개 이상으로 구성된 문장을 의미한다.
"갈색 강아지"와 "갈색강아지"는 다르다. 전자는 '구'이고, 후자는 '텀'으로 책정한다.
match_phrase는 구만 따로 검색을 하는 방식으로, 검색어를 온전한 그대로 검색한다.
# match_phrase
GET my_english/_search
{
"query": {
"match_phrase": {
"필드명": "검색어"
}
}
}
GET my_english/_search
{
"query": {
"match_phrase": {
"message": "lazy dog"
}
}
}
GET my_korean/_search
{
"query": {
"match_phrase": {
"message": "갈색 강아지"
}
}
}검색 결과로 "lazy dog"이 온전하게 있는 문장을 찾는다.
보다 특정하고 정확한 검색 결과를 얻고 싶을 때 match_phrase를 사용한다.
slop
GET my_english/_search
{
"query": {
"match_phrase": {
"message": {
"query": "lazy dog",
"slop": 1
}
}
}
}
GET my_korean/_search
{
"query": {
"match_phrase": {
"message": {
"query": "갈색 강아지",
"slop": 1
}
}
}
}match_phrase에서만 사용할 수 있는 slop 옵션이 있다.
slop은 뭔가 비우거나 덜어낸다는 뜻이며, 텀의 개수로 사용된다 된다.
slop 옵션을 주면 저장된 숫자 만큼 단어 사이에 다른 단어가 끼어드는 것을 허용한다는 뜻이다. 이를 사용하면 검색할 수 있는 범위가 굉장히 늘어나게 된다.
- where item lick '%아이폰 케이스%'
- where item lisk '%아이폰%' or itme like '%케이스%'
- where item lisk '%아이폰%케이스%'
slop 옵션으로 검색하는 건 3번째 방법으로 검색하는 방법과 같다.
Bool Query
#Bool Query
GET <인덱스명>/_search
{
"query": {
"bool": {
"must": [
{쿼리}, {쿼리}, ..
]
"must_not": [
{쿼리}, {쿼리}, ..
]
"should": [
{쿼리}, {쿼리}, ..
]
"filter": [
{쿼리}, {쿼리}, ..
]
}
}
}Bool Query는 Bool 복합 쿼리라고도 한다.
여러 쿼리를 조합하는 용도로 사용한다.
상위에서는 bool 쿼리를 작성하고, 하위에서는 다른 쿼리를 작성하여 조합하는 방식으로 많이 사용한다.
인자
- must: 쿼리가 참인 문서를 반환한다.
- must_not: 쿼리가 거짓인 문서를 반환한다.
- should: 검색 결과 중 해당 쿼리 결과 점수를 높인다.
- filter: 쿼리가 참인 문서를 반환, 점수를 계산하지 않기 때문에 must보다 속도가 빠르다.
Bool Query 자체는 4개의 인자를 가지고 있어서 인자들을 가지고 조합해 나간다.
'quick' + 'lazy dog'
# 'quick' + 'lazy dog'
GET my_english/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"message": "quick"
}
},
{
"match_phrase": {
"message": "lazy dog"
}
}
]
}
}
}'quick', 'lazy dog' 둘 다 포함된 문서를 검색하려고 한다.
'quick'은 단어로 찾고, 'lazy dog'은 구로 찾고 싶다. 그러면 'quick'은 match로 찾으면 되고, 'lazy dog'은 match_phrase로 검색해야 한다.
현재 찾고자 하는 검색이 종류가 다른 검색을 동시에 해야 하는 상황이다. 이때 Bool Query를 사용한다.
'지붕 + '게으른 강아지'
# '지붕' + '게으른 강아지'
GET my_korean/_search
{
"query": {
"match": {
"message": {
"query": "지붕 게으른 강아지",
"operator": "and"
}
}
}
}
GET my_korean/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"message": "지붕"
}
},
{
"match_phrase": {
"message": "게으른 강아지"
}
}
]
}
}
}
slop 옵션 사용
GET my_korean/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"message": "지붕"
}
},
{
"match_phrase": {
"message": {
"query": "갈색 닭",
"slop": 1
}
}
}
]
}
}
}
must_not
'quick'과 'brown dog'이 모두 포함되지 않은 문서를 검색해 보도록 하자.
GET my_english/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"message": "quick"
}
},
{
"match_phrase": {
"message": "brown dog"
}
}
]
}
}
}
여러 개의 배열
GET my_english/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"message": "quick"
}
}
],
"must": [
{
"match": {
"message": "dog"
}
}
]
}
}
}Bool 쿼리 안에 여러 개의 배열로 검색할 수도 있다.
'남자' + '강남' 이외의 거주
# '남자' + '강남' 이외의 거주
GET member/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"gender": "m"
}
}
],
"must_not": [
{
"match": {
"address": "강남구"
}
}
]
}
}
}