
🌿Elasticsearch의 특징
active(running) 확인
$ sudo systemctl start 패키지명
$ sudo systemctl stop 패키지명
$ sudo systemctl status 패키지명
$ sudo systemctl restart 패키지명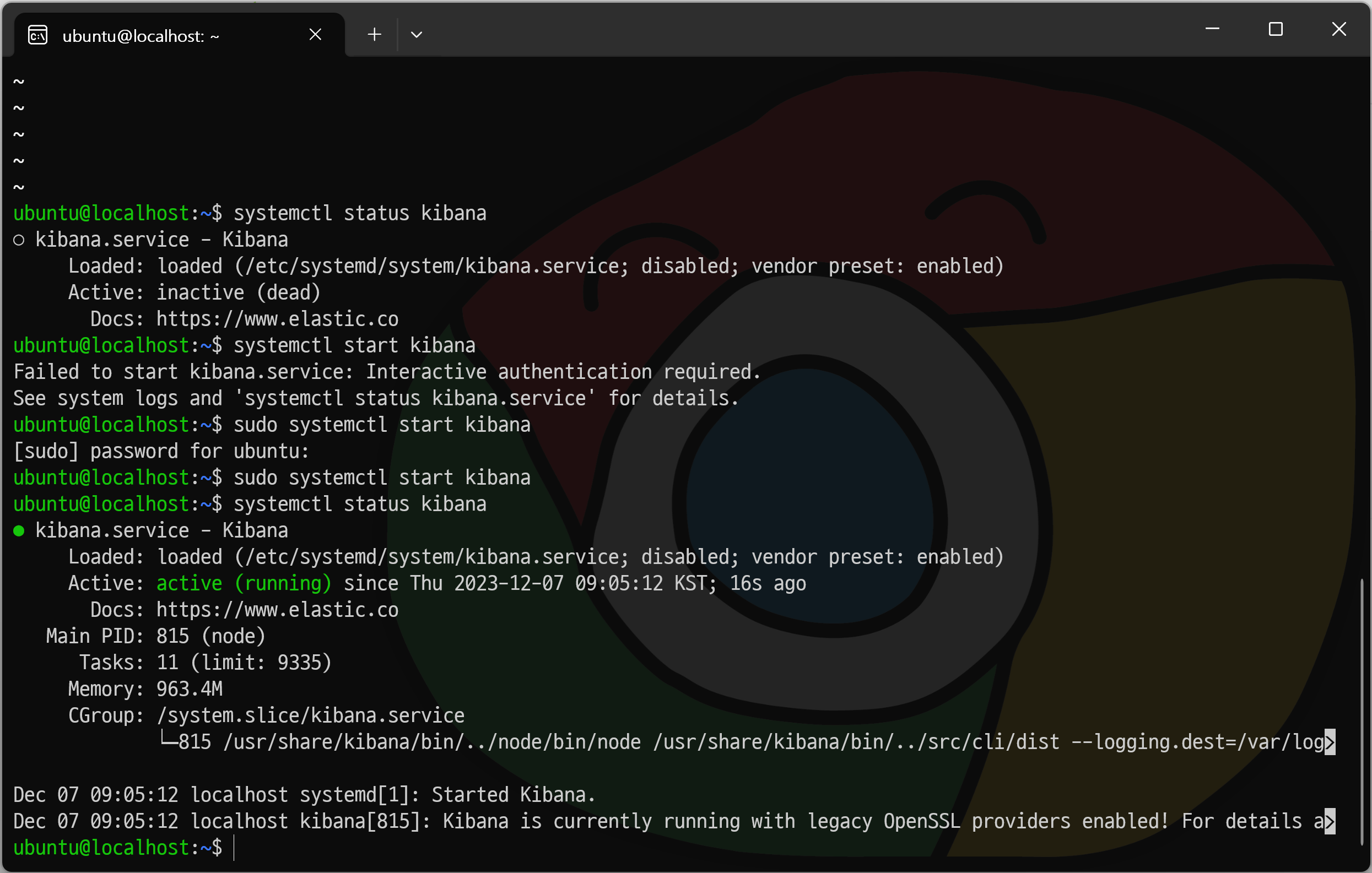
elasticsearch와 kibana가 active(running) 중인지 확인한다.
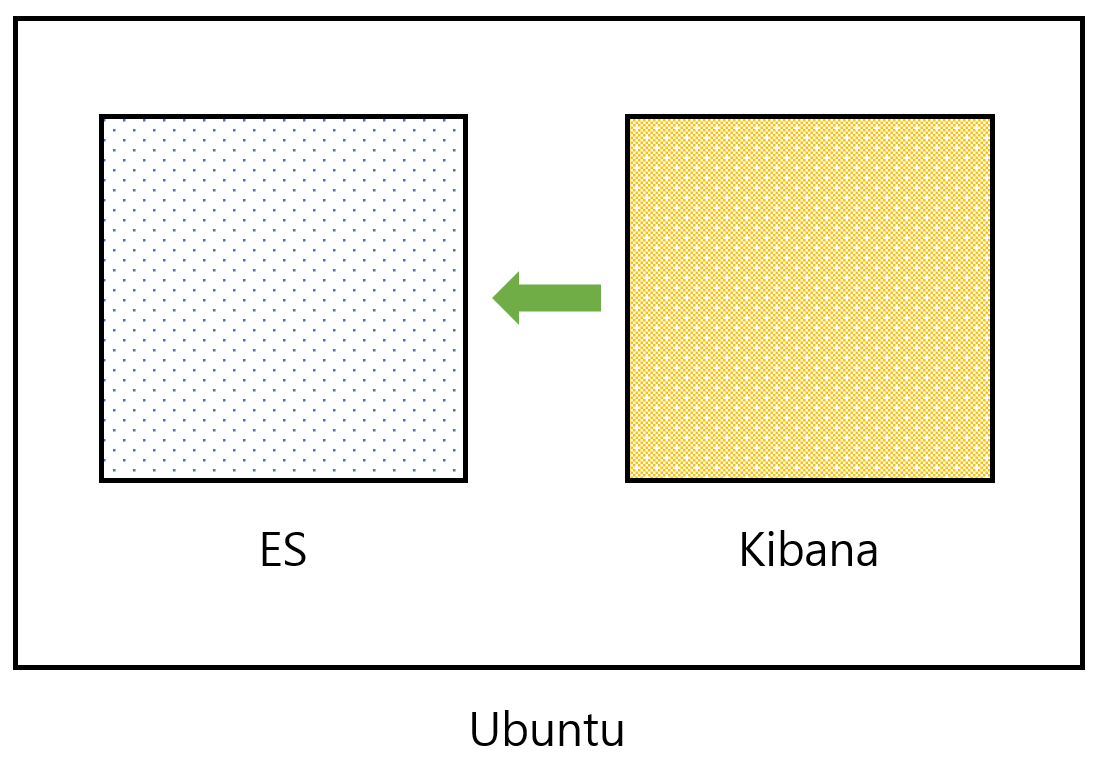
이제 Ubuntu라는 환경에서 Elasticsearch와 kibana가 돌고 있는 상태이다.
elasticsearch.host가 http://localhost:9200으로 되어 있다. kibana가 기본적으로 연결해야 하는 주소를 이미 알고 있기 때문에 두 프로그램을 연결해주지 않아도 실행하는 것만으로 kibana가 elasticsearch에 접속하게 된다.
이때 다른 컴퓨터에 있는 elasticsearch를 접속해야 한다면 해당 호스트 설정을 통해 수정하면 된다.
브라우저
- http://localhost:9200 > elasticsearch
- http://localhost:5601 > kibana
REST full 작업은 kibana에서 진행하도록 한다.
Oracle과 Elasticsearch의 차이
Oracle
1. 테이블선언
- 컬럼 정의 (이름(varchar2), 나이(number), 주소(varchar2))
2. insert
- 레코드 추가
Elasticsearch
1. Index(Type) 선언
- 저장 규칙에 강제성이 없다.
2. 데이터 추가(JSON)
{
"name": "Isaac",
"age": 24,
"address": "서울시"
}
{
"name": "Sopia",
"age": 25,
"address": "서울시"
}
{
"name": "Paul",
"gender": "m"
}기존에 들어 있는 데이터와 나중에 들어온 데이터의 구조가 달라도 상관없다. 그래서 이런 문서 상태의 저장소는 Oracle처럼 규칙을 따지지 않는다.
규칙을 따지지 않기 때문에 데이터 무결성과 정규화에 상관이 없다. Oracle과 Elasticsearch의 이런 차이는 관계형 DB와 비관계형 DB의 목적이 다르기 때문이다.
오라클은 데이터를 집어넣을 때마다 까다롭게 올바른 데이터만을 넣도록 검사한다. 이게 Oracle의 관계형 DB의 목표라면 비관계형 DB는 속도를 우선시하므로 입출력 절차가 간소화되어 있는 것이다. 천만 단위로 넘어가면 Oracle은 속도가 느려지는데, Elasticsearch는 조 단위로 넘어가도 검색 속도가 굉장히 빠르다.
Elasticsearch의 구조는 REST API로 구현한 JSON을 저장하는 프로그램이라고 생각하면 되며, 이처럼 검색이 필요한 컬럼만 따로 Elasticsearch로 넘겨 검색 엔진으로 사용한다.
JSON 데이터를 저장하는 프로그램이기 때문에 데이터베이스와 유사하지만 DB는 아니다. 이때 데이터 저장 단위는 JSON 형태의 Document로 되어 있다.
🌿데이터 삽입
인덱스 확인
indicies
GET _cat/indices
GET _cat/indices/member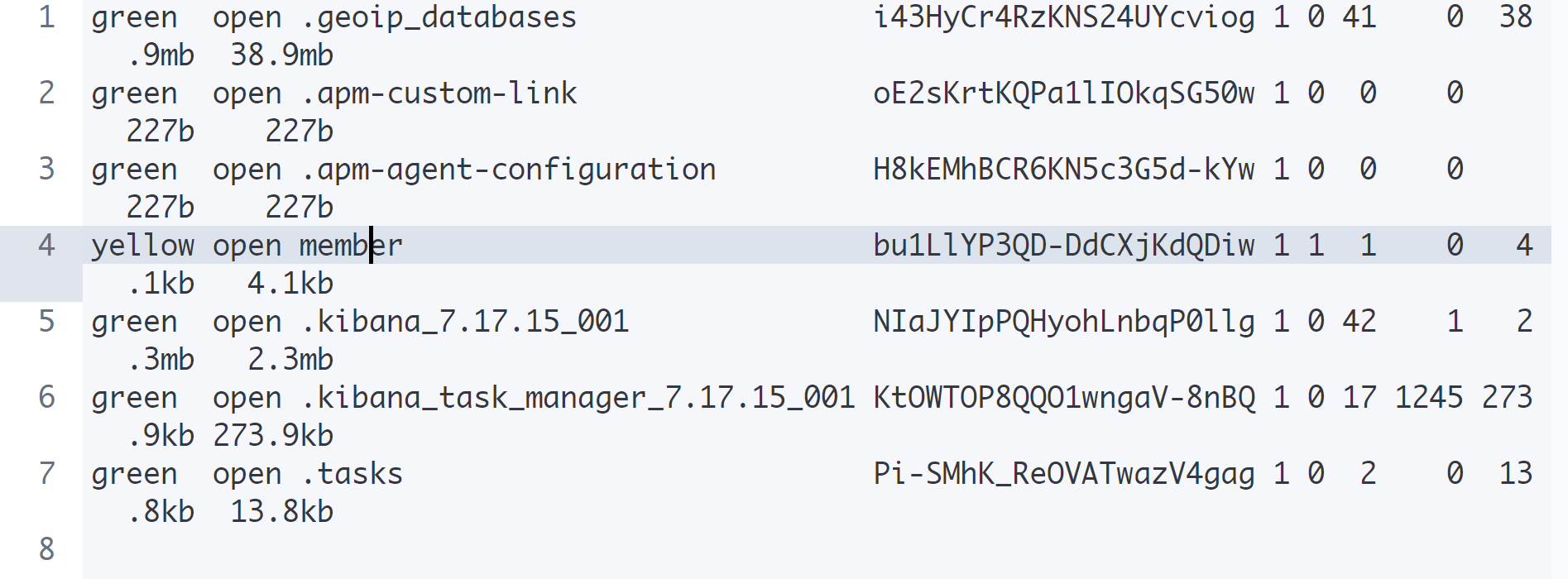
인덱스 이름이 '.'으로 시작하면 시스템 인덱스를 의미한다.
elasticsearch나 kibana를 돌리기 위해서 내부적으로 인덱스를 사용하는데, 눈에 띄지 않도록 구분 짓기 위해서 '.'으로 시작한다.
반대로 말하면 직접 만드는 인덱스는 '.'으로 시작하면 안 된다.
PUT을 이용한 데이터 삽입
# Document > JSON 형태의 데이터
GET member
PUT member/_doc/1
{
"name": "Isaac",
"age": 24
}
PUT member/_doc/2
{
"name": "Sopia",
"age": 25
}PUT으로 인덱스와 _doc, 도큐먼트 아이디를 넣고 데이터를 삽입한다.
데이터 덮어쓰기
PUT member/_doc/1
{
"name": "Isaac",
"age": 25
}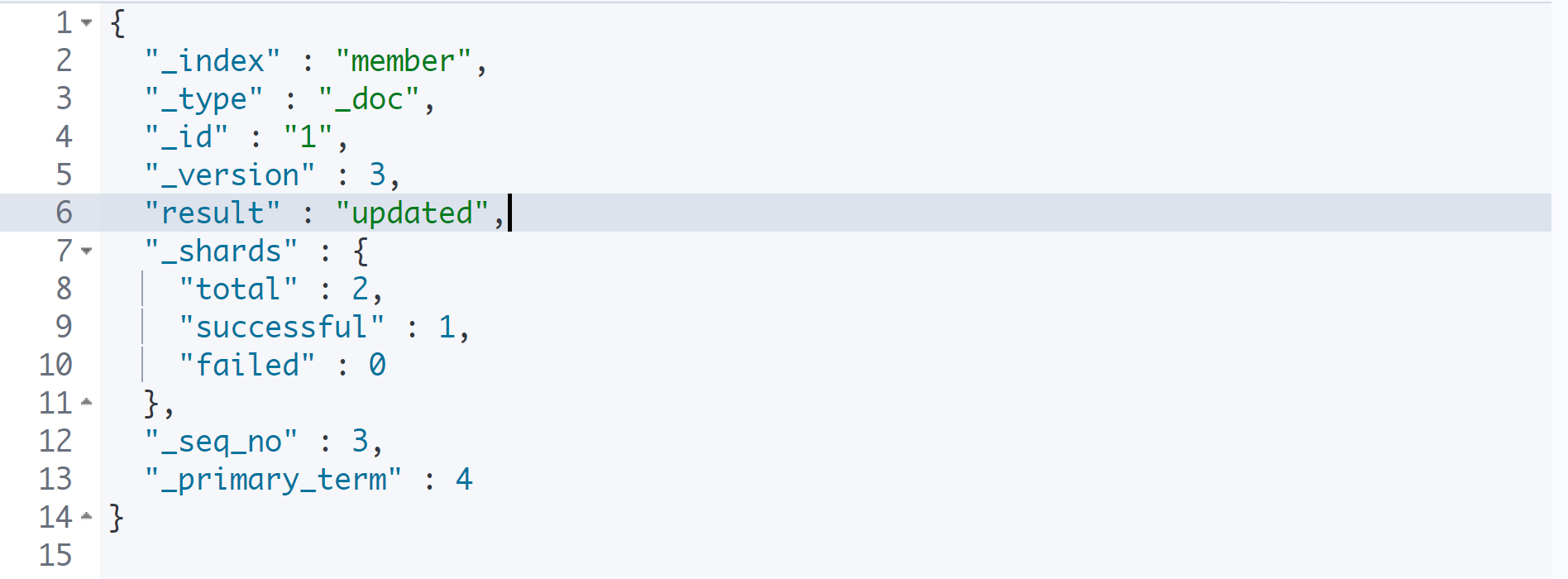
이미 존재하는 1번 아이디로 똑같은 구성으로 나이만 바꾸었다.
그러자 version이 올라가면서 result가 updated 되었다. 즉, 데이터 추가가 아닌 데이터 덮어쓰기가 발생한 것이다. document id가 같은 경우에는 추가가 아닌 덮어쓰기가 발생하게 된다.
PUT member/_doc/1
{
"age": 25
}
GET member/_doc/1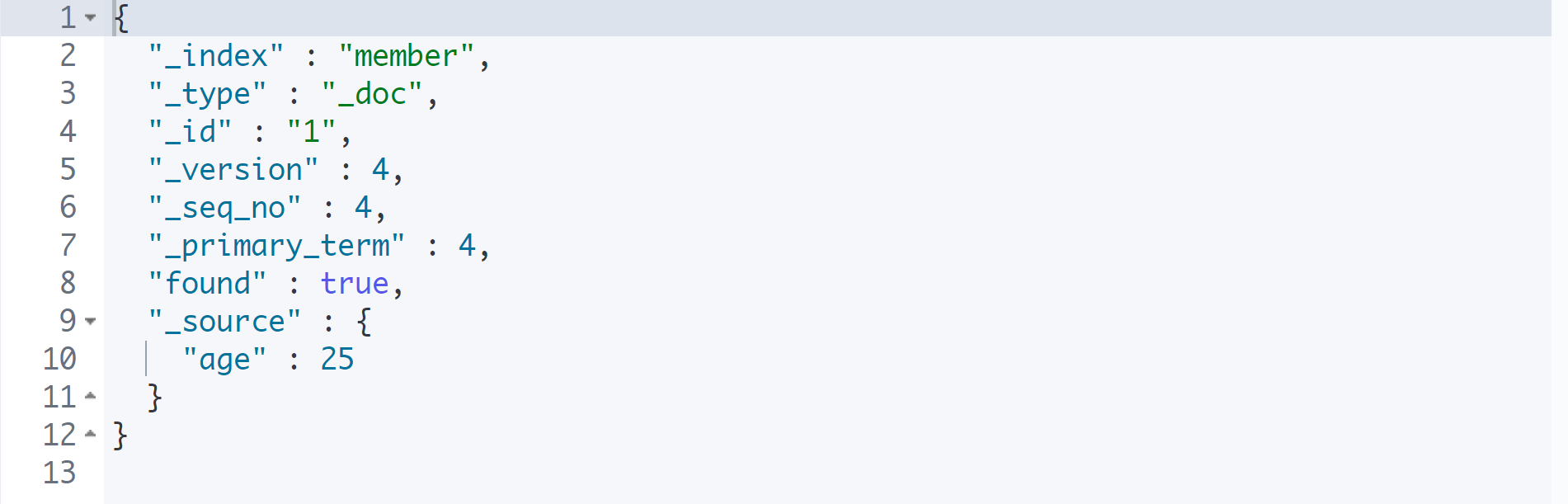
PUT은 기존의 Document를 삭제하고, 새로운 Document를 추가한다.
그래서 PUT으로 위와 같이 수정하면 name이 사라지고 age만 남게 된다.
이때 _update라는 고정자로 조합하면 일부 필드만 수정할 수 있다.
Bulk API를 이용한 다량의 데이터 삽입
POST _bulk
{ "index" : { "_index" : "address", "_type" : "_doc", "_id" : "1" } }
{"name" : "Isaac", "age": 20, "gender": "m"}
{ "index" : { "_index" : "address", "_type" : "_doc", "_id" : "2" } }
{"name" : "Sopia", "age": 20, "gender": "f"}
{ "index" : { "_index" : "address", "_type" : "_doc", "_id" : "3" } }
{"name" : "Itsy", "age": 22, "gender": "m"}
{ "index" : { "_index" : "address", "_type" : "_doc", "_id" : "4" } }
{"name" : "Itsha", "age": 24, "gender": "m"}위 코드는 Elasticsearch에서 다량의 데이터를 넣을 때의 형식이다.
첫 번째는 index라는 키가 있고, 하위에 _index, _type, _doc, _id가 있다. 그리고 평범한 JSON 형태의 데이터가 온다.
위에 있는 게 header이고, 아래에 있는 게 body이며, 이는 한 줄로 작성되어야 한다. 또한 빈 줄이 있으면 안 된다.
이를 Bulk API라고 하며, 다량의 데이터를 한 번에 입력하는 API이다.
특정 Index의 모든 Document 조회
_search
GET address/_doc/1
GET address/_search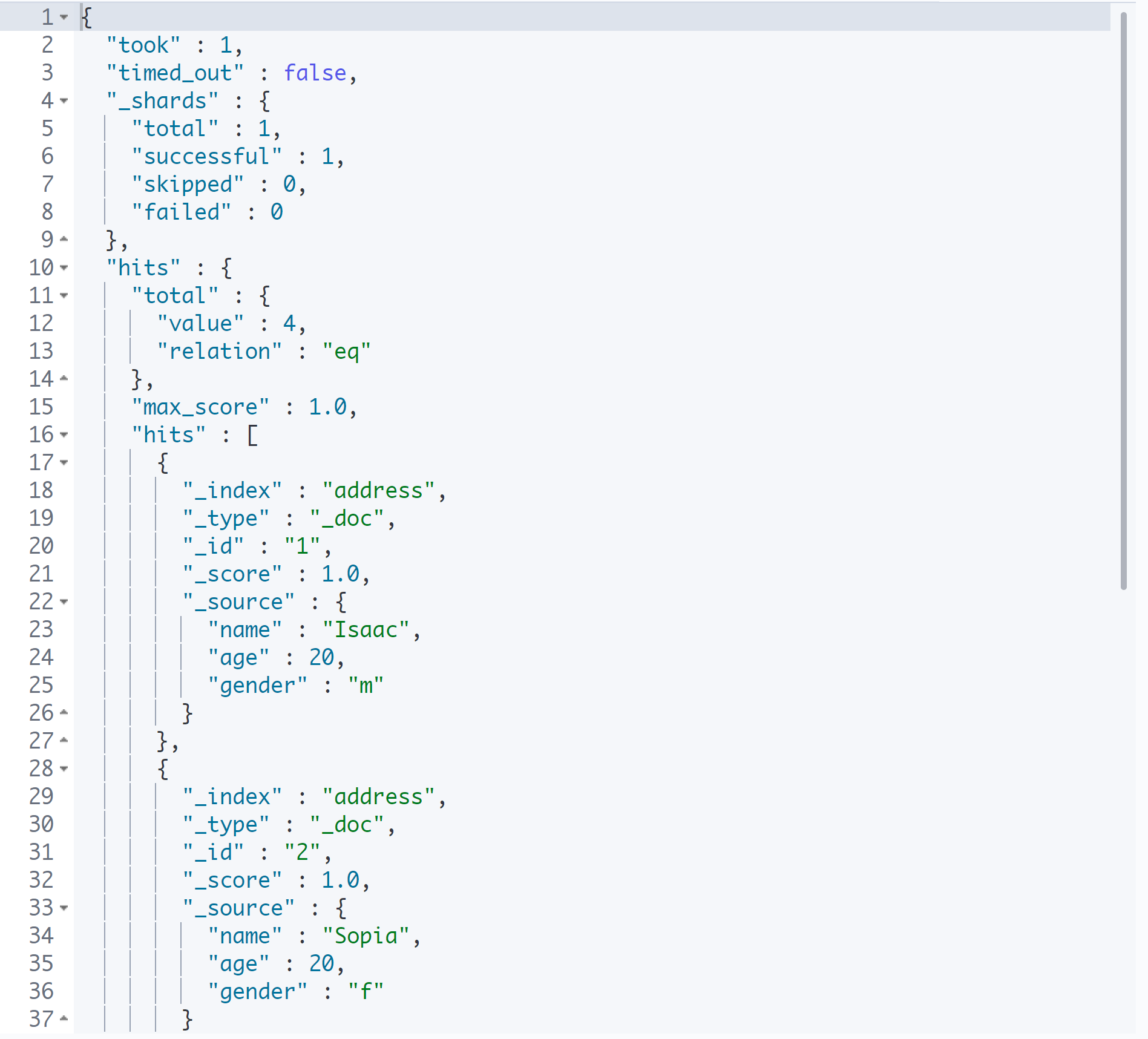
search를 이용하여 특정 인덱스의 모든 Document를 확인할 수 있다.
🌿Documnet 삭제
DELETE를 이용한 데이터 삭제
DELETE member/_doc/1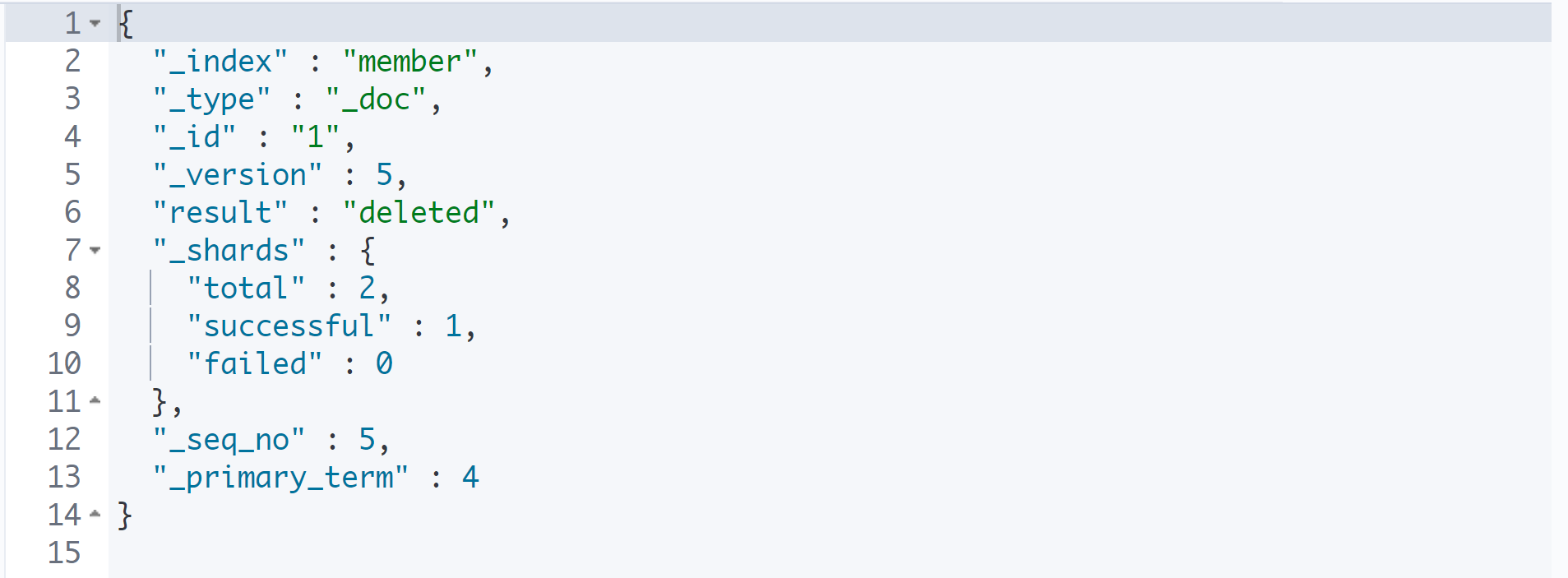
데이터 확인
GET member/_doc/1
데이터를 삭제한 뒤에 데이터를 찾으면 found가 false로 출력된다.
🌿Documnet 수정
POST를 이용한 데이터 수정
GET member/_doc/2
POST member/_update/2
{
"doc": {
"age": 26
}
}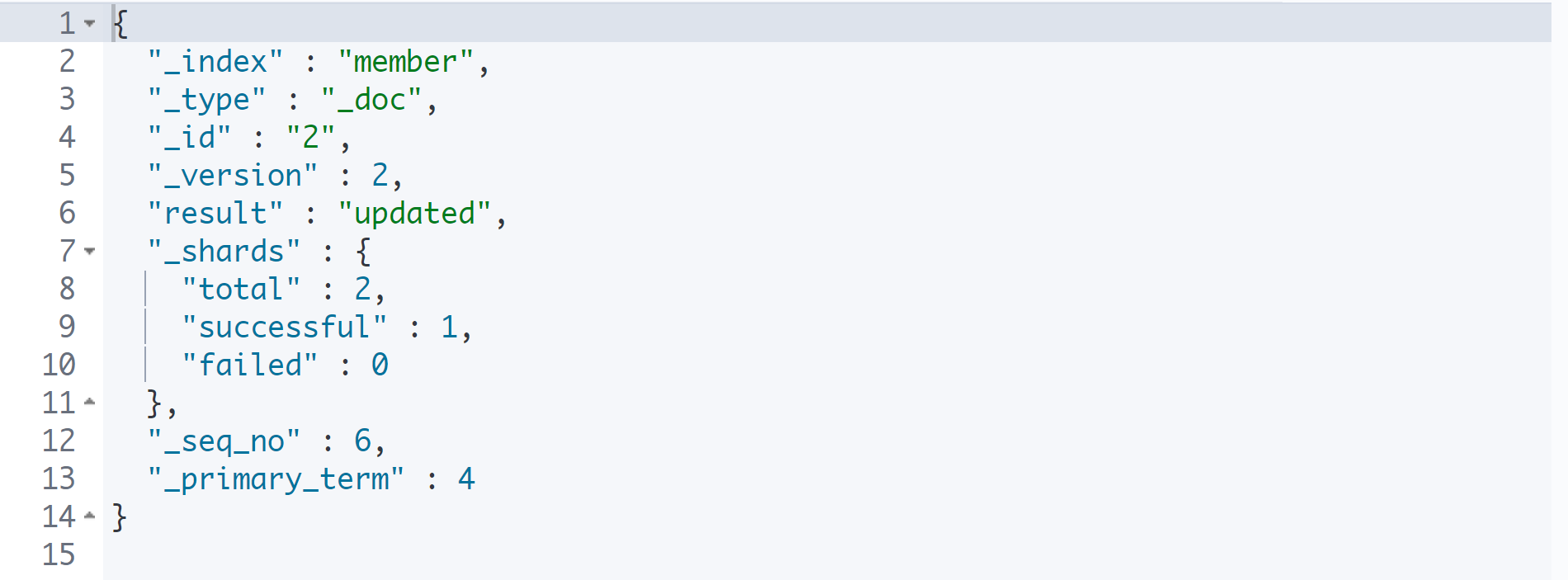
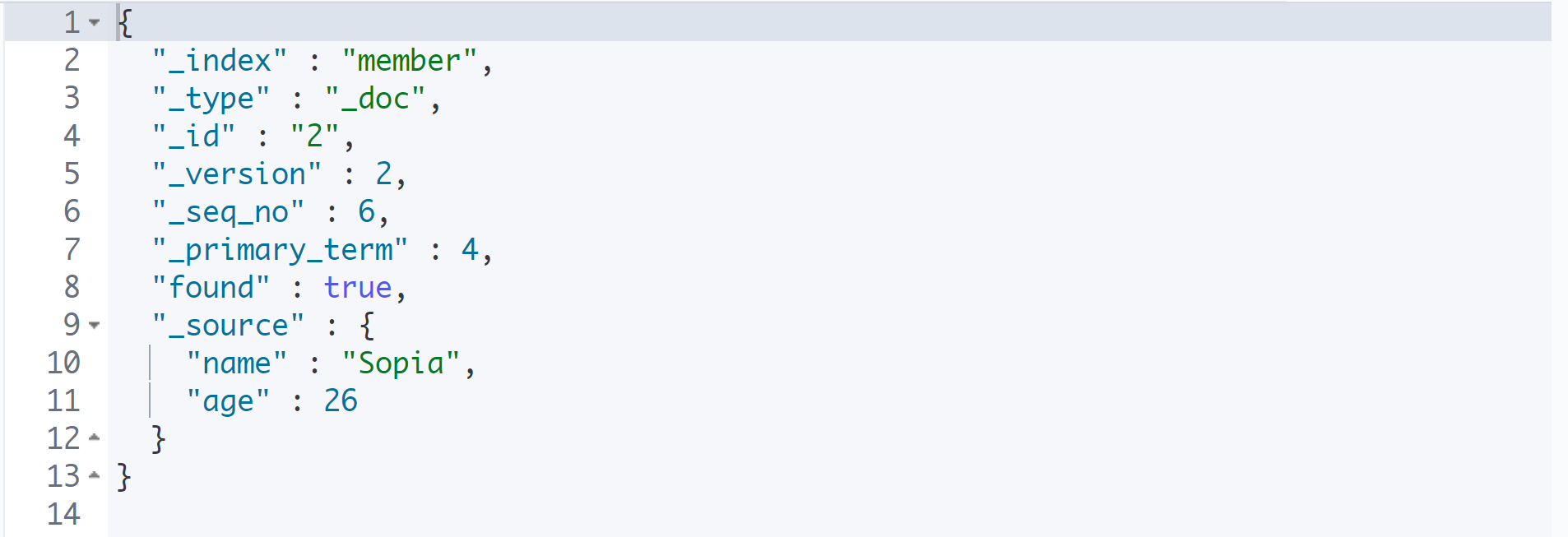
나이만 수정하고 싶을 때에도 반드시 doc라는 필드를 적고, 그 안에 수정할 내용을 적도록 한다.
이 방식으로 수정하면 기존 필드가 유지된 채로 수정하고자 하는 필드만 수정된다.
_update 고정자를 사용할 수 있는 건 POST 밖에 없다. 따라서 PUT은 전체 필드를 수정할 때 사용하고, POST는 일부 필드를 수정할 때 사용한다.
Elasticsearch는 다량의 데이터를 넣는 것을 목적으로 하기 때문에 애초에 수정이 발생할 만한 데이터를 넣지 않는다. 그래서 수정할 일이 빈번하게 발생하지 않는다.
🌿문서의 기본적인 CRUD 요약
# 전체 목록 읽기
GET address/_search
# 특정 문서 읽기
GET address/_doc/1
# 문서 추가하기
PUT address/_doc/5
{
"name": "Paul",
"age": 28,
"gender": "m"
}
# 문서 수정하기
POST address/update/5
{
"doc": {
"gender": "f"
}
}
# 문서 삭제하기
DELETE address/_doc/5지금은 REST full API로 작업을 하고 있지만, 이 작업을 나중에는 Spring에서 연동하여 하게 된다.

🌿Elasticsearch의 특징
active(running) 확인
$ sudo systemctl start 패키지명
$ sudo systemctl stop 패키지명
$ sudo systemctl status 패키지명
$ sudo systemctl restart 패키지명elasticsearch와 kibana가 active(running) 중인지 확인한다.
이제 Ubuntu라는 환경에서 Elasticsearch와 kibana가 돌고 있는 상태이다.
elasticsearch.host가 http://localhost:9200으로 되어 있다. kibana가 기본적으로 연결해야 하는 주소를 이미 알고 있기 때문에 두 프로그램을 연결해주지 않아도 실행하는 것만으로 kibana가 elasticsearch에 접속하게 된다.
이때 다른 컴퓨터에 있는 elasticsearch를 접속해야 한다면 해당 호스트 설정을 통해 수정하면 된다.
브라우저
- http://localhost:9200 > elasticsearch
- http://localhost:5601 > kibana
REST full 작업은 kibana에서 진행하도록 한다.
Oracle과 Elasticsearch의 차이
Oracle
1. 테이블선언
- 컬럼 정의 (이름(varchar2), 나이(number), 주소(varchar2))
2. insert
- 레코드 추가
Elasticsearch
1. Index(Type) 선언
- 저장 규칙에 강제성이 없다.
2. 데이터 추가(JSON)
{
"name": "Isaac",
"age": 24,
"address": "서울시"
}
{
"name": "Sopia",
"age": 25,
"address": "서울시"
}
{
"name": "Paul",
"gender": "m"
}기존에 들어 있는 데이터와 나중에 들어온 데이터의 구조가 달라도 상관없다. 그래서 이런 문서 상태의 저장소는 Oracle처럼 규칙을 따지지 않는다.
규칙을 따지지 않기 때문에 데이터 무결성과 정규화에 상관이 없다. Oracle과 Elasticsearch의 이런 차이는 관계형 DB와 비관계형 DB의 목적이 다르기 때문이다.
오라클은 데이터를 집어넣을 때마다 까다롭게 올바른 데이터만을 넣도록 검사한다. 이게 Oracle의 관계형 DB의 목표라면 비관계형 DB는 속도를 우선시하므로 입출력 절차가 간소화되어 있는 것이다. 천만 단위로 넘어가면 Oracle은 속도가 느려지는데, Elasticsearch는 조 단위로 넘어가도 검색 속도가 굉장히 빠르다.
Elasticsearch의 구조는 REST API로 구현한 JSON을 저장하는 프로그램이라고 생각하면 되며, 이처럼 검색이 필요한 컬럼만 따로 Elasticsearch로 넘겨 검색 엔진으로 사용한다.
JSON 데이터를 저장하는 프로그램이기 때문에 데이터베이스와 유사하지만 DB는 아니다. 이때 데이터 저장 단위는 JSON 형태의 Document로 되어 있다.
🌿데이터 삽입
인덱스 확인
indicies
GET _cat/indices
GET _cat/indices/member인덱스 이름이 '.'으로 시작하면 시스템 인덱스를 의미한다.
elasticsearch나 kibana를 돌리기 위해서 내부적으로 인덱스를 사용하는데, 눈에 띄지 않도록 구분 짓기 위해서 '.'으로 시작한다.
반대로 말하면 직접 만드는 인덱스는 '.'으로 시작하면 안 된다.
PUT을 이용한 데이터 삽입
# Document > JSON 형태의 데이터
GET member
PUT member/_doc/1
{
"name": "Isaac",
"age": 24
}
PUT member/_doc/2
{
"name": "Sopia",
"age": 25
}PUT으로 인덱스와 _doc, 도큐먼트 아이디를 넣고 데이터를 삽입한다.
데이터 덮어쓰기
PUT member/_doc/1
{
"name": "Isaac",
"age": 25
}이미 존재하는 1번 아이디로 똑같은 구성으로 나이만 바꾸었다.
그러자 version이 올라가면서 result가 updated 되었다. 즉, 데이터 추가가 아닌 데이터 덮어쓰기가 발생한 것이다. document id가 같은 경우에는 추가가 아닌 덮어쓰기가 발생하게 된다.
PUT member/_doc/1
{
"age": 25
}
GET member/_doc/1PUT은 기존의 Document를 삭제하고, 새로운 Document를 추가한다.
그래서 PUT으로 위와 같이 수정하면 name이 사라지고 age만 남게 된다.
이때 _update라는 고정자로 조합하면 일부 필드만 수정할 수 있다.
Bulk API를 이용한 다량의 데이터 삽입
POST _bulk
{ "index" : { "_index" : "address", "_type" : "_doc", "_id" : "1" } }
{"name" : "Isaac", "age": 20, "gender": "m"}
{ "index" : { "_index" : "address", "_type" : "_doc", "_id" : "2" } }
{"name" : "Sopia", "age": 20, "gender": "f"}
{ "index" : { "_index" : "address", "_type" : "_doc", "_id" : "3" } }
{"name" : "Itsy", "age": 22, "gender": "m"}
{ "index" : { "_index" : "address", "_type" : "_doc", "_id" : "4" } }
{"name" : "Itsha", "age": 24, "gender": "m"}위 코드는 Elasticsearch에서 다량의 데이터를 넣을 때의 형식이다.
첫 번째는 index라는 키가 있고, 하위에 _index, _type, _doc, _id가 있다. 그리고 평범한 JSON 형태의 데이터가 온다.
위에 있는 게 header이고, 아래에 있는 게 body이며, 이는 한 줄로 작성되어야 한다. 또한 빈 줄이 있으면 안 된다.
이를 Bulk API라고 하며, 다량의 데이터를 한 번에 입력하는 API이다.
특정 Index의 모든 Document 조회
_search
GET address/_doc/1
GET address/_searchsearch를 이용하여 특정 인덱스의 모든 Document를 확인할 수 있다.
🌿Documnet 삭제
DELETE를 이용한 데이터 삭제
DELETE member/_doc/1
데이터 확인
GET member/_doc/1데이터를 삭제한 뒤에 데이터를 찾으면 found가 false로 출력된다.
🌿Documnet 수정
POST를 이용한 데이터 수정
GET member/_doc/2
POST member/_update/2
{
"doc": {
"age": 26
}
}나이만 수정하고 싶을 때에도 반드시 doc라는 필드를 적고, 그 안에 수정할 내용을 적도록 한다.
이 방식으로 수정하면 기존 필드가 유지된 채로 수정하고자 하는 필드만 수정된다.
_update 고정자를 사용할 수 있는 건 POST 밖에 없다. 따라서 PUT은 전체 필드를 수정할 때 사용하고, POST는 일부 필드를 수정할 때 사용한다.
Elasticsearch는 다량의 데이터를 넣는 것을 목적으로 하기 때문에 애초에 수정이 발생할 만한 데이터를 넣지 않는다. 그래서 수정할 일이 빈번하게 발생하지 않는다.
🌿문서의 기본적인 CRUD 요약
# 전체 목록 읽기
GET address/_search
# 특정 문서 읽기
GET address/_doc/1
# 문서 추가하기
PUT address/_doc/5
{
"name": "Paul",
"age": 28,
"gender": "m"
}
# 문서 수정하기
POST address/update/5
{
"doc": {
"gender": "f"
}
}
# 문서 삭제하기
DELETE address/_doc/5지금은 REST full API로 작업을 하고 있지만, 이 작업을 나중에는 Spring에서 연동하여 하게 된다.