

JPA(Java Persistence API)는 자바의 ORM(Object-Relational Mapping) 기술을 쉽게 구현하도록 도와주는 API이다.
JpaRepository를 상속하는 인터페이스에 메서드 이름만 작성하면, JPA가 구현체를 생성하고 필요한 쿼리문을 자동으로 처리한다. 따라서 개발자는 SQL을 작성할 필요 없이 간단한 메서드 명칭만으로도 데이터베이스를 조작할 수 있다.
JPA는 엔티티(Entity)라는 클래스를 이용하여 객체를 데이터베이스에 매핑한다. 엔티티는 개발자에게 테이블 또는 레코드와 유사한 개념이다. 객체를 이용하여 매핑을 처리하므로, 개발자는 객체지향적인 코드를 작성할 수 있다.
JPA를 사용하면 CRUD(Create, Read, Update, Delete) 작업을 간편하게 수행할 수 있으며, 객체와 관계형 데이터베이스 간의 매핑을 손쉽게 처리할 수 있다.
💡JPA란?
JPA(Java Persistence API)는 자바 진영에서 ORM기술의 표준으로 사용되는 인터페이스 모음이다. 즉, 실제적으로 구현된 것이 아니라 구현된 클래스와 매핑을 해주기 위해 사용된다. JPA를 구현한 대표적인 오픈소스로는 Hibernate가 있다.
ORM(Object-Relational Mapping)은 객체와 관계형 데이터베이스 간의 매핑을 의미하며, 이를 통해 객체 지향 프로그래밍과 관계형 데이터베이스 간의 불일치를 해결할 수 있다.
JPA는 이러한 ORM 개념을 자바 애플리케이션에 적용할 수 있도록 인터페이스를 제공하여 개발자가 데이터베이스를 객체로 다룰 수 있게 한다.
JPA, Hibernate, Spring Data JPA

위 사진은 JPA, Hibernate, 그리고 Spring Data JPA의 전반적인 개념을 그림으로 표현한 것이다.
JPA, Spring Data JPA, Hibernate는 모두 Java 기반의 ORM(Object-Relational Mapping) 기술이지만 각각의 역할과 특징이 다르다.
JPA는 인터페이스 명세이며, Hibernate는 이를 구현한 구현체이고, Spring Data JPA는 Spring 프레임워크에서 JPA를 쉽게 사용할 수 있도록 지원하는 모듈이다. JPA와 Hibernate는 데이터베이스와의 매핑을 위한 기술이며, Spring Data JPA는 Spring 애플리케이션에서 JPA를 사용할 때 발생할 수 있는 반복적인 코드를 줄여주는 기술이다.
JPA(Java Persistence API)
자바에서 관계형 데이터베이스를 다루기 위한 인터페이스이며, ORM 기술에 대한 명세서이다.
JPA는 인터페이스이므로 구현체가 필요하다. 이를 위해 Hibernate, EclipseLink, OpenJPA 등이 있다.
엔티티 매니저(Entity Manager)를 통해 영속성 컨텍스트를 관리하고, 엔티티를 데이터베이스에 저장하고 조회하는 등의 기능을 제공한다.
SQL을 직접 작성하지 않고 객체지향적인 코드로 데이터베이스를 다룰 수 있도록 지원한다.
Hibernate
Hibernate는 JPA의 구현체 중 하나로, JPA의 인터페이스를 구현하여 객체와 데이터베이스 간의 매핑을 담당한다.
Hibernate는 요약하면 JPA 명세를 구현한 ORM 프레임워크이며, 객체와 데이터베이스 간의 매핑 및 영속성 컨텍스트를 관리하는 기능을 제공한다.
JPA가 명세이고, Hibernate는 이를 구현한 구현체다. 따라서 Hibernate를 사용하여 JPA 스펙을 구현할 수 있다.
Hibernate. Everything data.
More than an ORM, discover the Hibernate galaxy.
hibernate.org
Hibernate에 대한 자세한 내용은 위 글을 참고한다.
Spring Data JPA
Spring Data JPA는 Spring 프레임워크에서 JPA를 쉽게 사용할 수 있도록 지원하는 모듈이다.
Spring Data 프로젝트의 일부로, 데이터 액세스 계층의 개발을 단순화하고 표준화하기 위해 만들어졌다.
Repository 인터페이스를 통해 CRUD 기능을 제공하며, 쿼리 메서드를 정의하여 간편하게 데이터베이스에 접근할 수 있도록 한다.
Spring Data JPA는 JPA를 사용하여 데이터 액세스 계층을 개발할 때 반복적이고 지루한 코드를 줄여준다.
https://spring.io/projects/spring-data-jpa#overview
Spring Data JPA
Spring Data JPA, part of the larger Spring Data family, makes it easy to easily implement JPA-based (Java Persistence API) repositories. It makes it easier to build Spring-powered applications that use data access technologies. Implementing a data access l
spring.io
Spring Data JPA에 대해서는 위 글을 참고한다.
ORM
ORM(Object-Relational Mapping)은 객체지향적인 구조와 관계형 데이터베이스의 데이터를 자동으로 매핑(연결)해주는 프레임워크이다. 이를 통해 객체지향 프로그래밍 언어인 Java, Python 등과 관계형 데이터베이스 간의 불일치를 해결할 수 있다.
객체지향적 구조와 SQL 구조의 차이
객체지향적 구조는 모든 데이터는 객체이며, 각 객체는 독립된 데이터와 독립된 함수를 지닌다.
SQL 구조는 데이터는 테이블 단위로 관리되며, 객체를 조회하기 위한 명령어를 사용한다.
ORM의 동작 방식
1. 각 테이블 또는 데이터 단위로 객체를 구현하고, 데이터 간의 관계를 형성한다.
2. 객체를 통해 데이터베이스 데이터를 다루며, SQL을 직접 작성하지 않아도 된다.
3. Persistence Layer라는 중간 계층을 통해 객체와 데이터베이스 간의 상호작용을 관리한다.
사용 예제
public class Person {
private String name;
private String height;
private String weight;
private String ssn;
// Implement getter & setter methods
}<hibernate-mapping>
<class name="net.agilejava.person.domain.Person" table="person">
<id name="name" column="name"/>
<property name="height" column="height"/>
<property name="weight" column="weight"/>
<property name="ssn" column="ssn"/>
<class>
</hibernate-mapping>
객체-관계 간의 불일치
1. 세분성(Granularity): 객체는 테이블보다 세분화된 클래스로 구현될 수 있다.
2. 상속성(Inheritance): 객체지향 언어의 상속 개념과 관계형 데이터베이스의 불일치가 발생한다.
3. 일치(Identity): 객체 식별과 데이터베이스의 기본키 개념이 다를 수 있다.
4. 연관성(Associations): 객체 참조와 외래키의 차이가 있다.
5. 탐색(Navigation): 객체는 그래프 형태로 탐색되지만, 데이터베이스는 일반적으로 JOIN을 사용한다.
JPA의 장단점
장점
1. SQL 작성이 감소한다.
JPA를 사용하면 SQL을 직접 작성할 필요가 없다. JPA는 개발자가 객체를 통해 데이터베이스를 조작할 수 있도록 도와주므로, SQL 쿼리를 작성하는 시간과 노력을 절약할 수 있다.
2. 객체지향적인 코드를 작성할 수 있다.
JPA는 객체 지향적인 접근 방식을 지원하여 데이터베이스를 조작할 수 있으며, 더 직관적이고 유연한 코드를 작성할 수 있다.
3. 유지보수성과 생산성이 향상된다.
JPA를 사용하면 매핑 정보가 클래스에 명시되어 있어 데이터베이스 구조에 대한 의존도가 낮아진다. 이로써 SQL에 의존하지 않기 때문에 유지보수성이 향상되고, 개발 생산성도 증가한다.
4. ERD 관리에 용이하다.
매핑 정보가 클래스로 명시되어 있기 때문에 ERD(Entity-Relationship Diagram)를 관리하는 데 용이하다. 변경이 필요한 경우 클래스를 수정함으로써 데이터베이스와의 매핑을 쉽게 업데이트할 수 있다.
5. 복잡한 쿼리 작성을 대체할 수 있다.
JPA는 객체를 통해 데이터베이스를 조작하는 데 집중할 수 있도록 해준다. 이를 통해 복잡한 SQL 쿼리 작성을 줄여 코드가 짧아지고, 코드의 가독성이 향상된다.
JPA의 장점으로 볼 때 JPA를 사용하는 이유는 다음과 같다!🖊️
1. SQL을 직접 작성하지 않아도 되므로 개발 시간을 단축할 수 있다.
2. 객체지향적인 코드를 작성할 수 있어 유지보수성이 향상된다.
3. 매핑 정보가 클래스로 명시되어 있기 때문에 데이터베이스의 변경에 유연하게 대처할 수 있다.
단점
1. 프로젝트 규모와 설계에 대해 신경을 써야 한다.
프로젝트가 커질수록 JPA를 사용하는데 필요한 설계 과정이 더 복잡해진다. 또한, 올바른 설계를 위해 더 많은 시간과 노력이 필요해진다.
2. 성능이 저하되고 일관성에 문제가 발생할 수 있다.
JPA를 사용할 경우 성능 저하나 일관성 문제가 발생할 수 있다. 복잡한 쿼리나 대량의 데이터를 다룰 때 성능 문제가 발생할 수 있으며, 일관성을 유지하기 위한 추가적인 관리가 필요할 수 있다.
3. 사용하기에 학습이 필요하다.
JPA를 제대로 활용하기 위해서는 ORM(Object-Relational Mapping)에 대한 이해가 필요하다. 따라서 학습 비용이 비싸고 초기 학습 곡선이 높을 수 있다.
객체와 데이터베이스 간의 매핑
JPA가 객체지향적인 코드를 작성할 수 있게 해주는 핵심적인 이유는 객체와 데이터베이스 간의 매핑을 지원하기 때문이다. 이를 통해 객체를 데이터베이스에 저장하고 관리할 때 객체 지향적인 개념을 그대로 유지할 수 있다.
1. 객체와 테이블 매핑
JPA를 사용하면 엔티티 클래스와 데이터베이스의 테이블을 매핑할 수 있다. 예를 들어, Java의 클래스를 통해 데이터베이스의 테이블을 정의하고 해당 테이블의 열과 데이터를 객체의 속성으로 표현할 수 있다.
2. 객체 그래프 탐색
객체 간의 관계를 매핑하여 객체 그래프를 구성할 수 있다. 이를 통해 객체 간의 연관 관계를 객체 지향적으로 표현할 수 있다. 예를 들어, 부모 객체와 자식 객체 간의 일대다 또는 다대일 관계를 매핑할 수 있다.
3. 상속 관계 매핑
JPA는 상속 관계를 매핑할 수 있다. 객체지향 프로그래밍에서 자주 사용되는 상속 관계를 데이터베이스의 테이블 간의 관계로 매핑할 수 있다. 이를 통해 객체지향적인 코드를 작성할 수 있다.
4. 객체 지향 쿼리 언어(JPQL) 지원
JPA는 객체 지향 쿼리 언어(JPQL)를 제공한다. JPQL은 엔티티 객체를 대상으로 쿼리를 작성할 수 있으며, SQL과 유사하지만 객체 지향적인 접근 방식을 제공한다. 이를 통해 객체지향적인 코드를 작성할 수 있다.
영속성 컨텍스트

영속성 컨텍스트는 JPA에서 사용되는 개념으로, 엔티티를 영구 저장하고 관리하는 환경으로, 애플리케이션과 데이터베이스 간의 중간 계층 역할을 한다. 엔티티 매니저를 통해 엔티티를 저장하거나 조회하면, 엔티티 매니저는 이를 영속성 컨텍스트에 보관하고 관리한다.
영속성 컨텍스트는 여러 가지 이점을 제공한다. 예를 들어, 1차 캐시를 통해 엔티티를 저장하여 조회 시 데이터베이스를 불러오지 않고도 빠르게 엔티티를 반환할 수 있다. 또한, 영속 엔티티의 동일성을 보장하여 애플리케이션 차원에서 일관된 데이터를 유지할 수 있다.
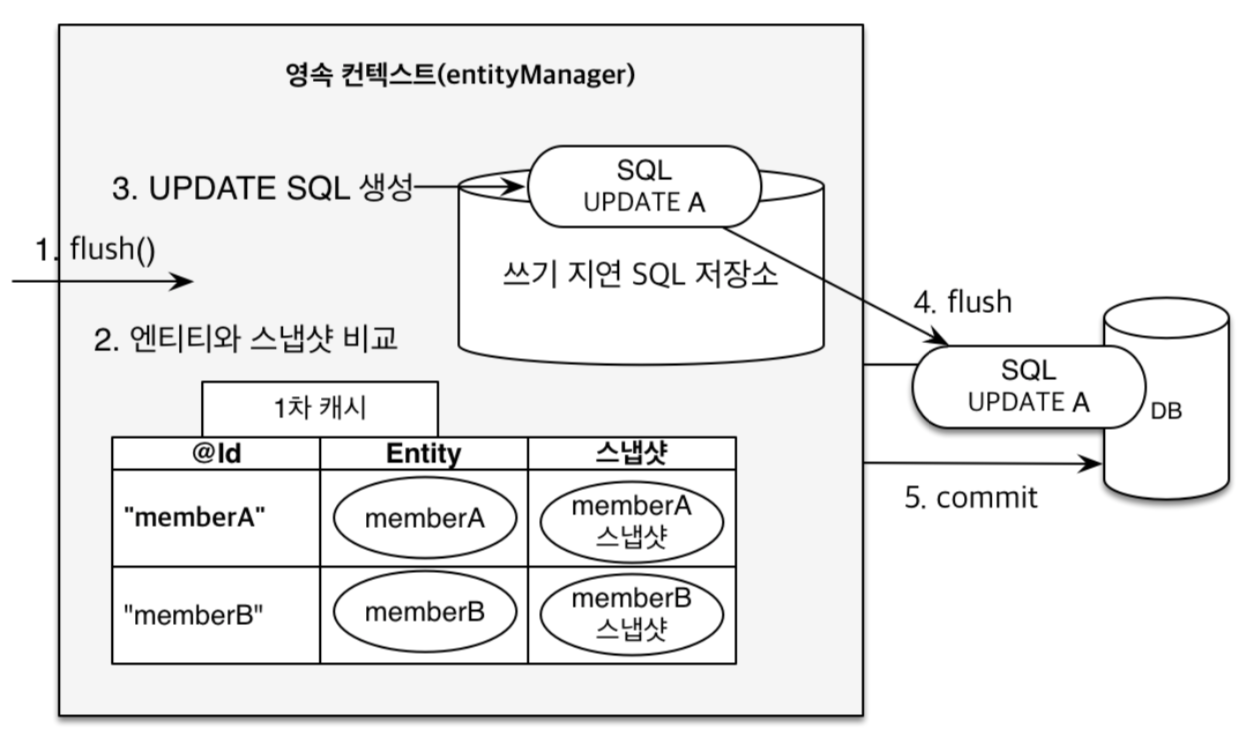
또한, 영속성 컨텍스트는 쓰기 지연, 변경 감지, 지연 로딩 등의 기능을 제공하여 효율적인 데이터베이스 액세스를 가능하게 한다. 쓰기 지연은 데이터베이스에 대한 변경 사항을 일괄적으로 처리하여 성능을 향상시킨다. 변경 감지는 엔티티의 상태 변화를 감지하여 자동으로 적절한 SQL을 생성한다. 지연 로딩은 연관된 엔티티를 필요할 때까지 불러오지 않고, 실제로 필요한 시점에만 데이터를 가져온다.
flush()
플러시는 영속성 컨텍스트의 변경 내용을 데이터베이스에 반영하는 과정을 말한다.
플러시가 발생하면 다음과 같은 일이 일어난다.
1. 변경 감지: 영속성 컨텍스트는 변경된 엔티티를 감지한다.
2. 수정된 엔티티 쓰기 지연 SQL 저장소에 등록: 변경된 엔티티에 대한 SQL 쿼리를 쓰기 지연 SQL 저장소에 등록한다.
3. 쓰기 지연 SQL 저장소의 쿼리를 데이터베이스에 전송: 등록된 SQL 쿼리를 데이터베이스에 전송하여 변경을 반영한다. 이러한 쿼리는 주로 등록, 수정, 삭제와 같은 데이터 조작 작업을 수행한다.
영속성 컨텍스트를 플러시하는 방법
1. em.flush(): EntityManager 객체의 flush() 메서드를 호출하여 수동으로 플러시를 실행한다.
2. 트랜잭션 커밋: 트랜잭션을 커밋할 때 자동으로 플러시가 발생한다.
3. JPQL 쿼리 실행: JPQL(Query)을 실행할 때도 플러시가 발생할 수 있다.
영속성이란?
앞서 계속 JPA의 영속성에 대해 언급했다. 그렇다면 영속성이란 무엇일까?
영속성 컨텍스트가 엔티티를 영구 저장하는 역할을 하는 것처럼, JPA에서의 영속성은 객체가 데이터베이스에 저장되는 것을 의미한다. 즉, 객체의 상태가 영구적으로 유지되는 것을 말한다.
객체가 영속성을 가지려면, 해당 객체는 영속성 컨텍스트(persistence context)에 관리되어야 한다. 이를 통해 객체의 상태 변경이 자동으로 데이터베이스에 반영되고, 객체의 식별과 관리가 용이해진다.
엔티티 간의 영속성

엔티티간의 영속성은 JPA에서 여러 개의 엔티티가 함께 영속성 컨텍스트에서 관리되는 것을 의미한다.
예를 들어, 하나의 엔티티 A가 다른 엔티티 B를 참조하는 경우, A와 B는 모두 같은 영속성 컨텍스트에서 관리될 수 있다. 이러한 경우에는 영속성 컨텍스트가 모든 관련된 엔티티의 변경을 추적하고, 트랜잭션이 커밋될 때 모든 변경을 데이터베이스에 반영한다. 따라서 영속성은 객체 간의 관계를 관리하고, 데이터베이스와의 일관성을 유지하는 데 중요한 역할을 한다.
비영속 상태와 영속 상태
// 비영속 상태
Member member = new Member();
member.setId("member1");
member.setUsername("회원1");
// 아직 영속성 컨텍스트와 관련이 없음
// 영속 상태
Member member = new Member();
member.setId("member1");
member.setUsername("회원1");
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
// 영속성 컨텍스트에 저장됨
em.persist(member);비영속 상태는 영속성 컨텍스트와 관련이 없는 상태이다. 이는 단순히 객체를 생성하고 초기화한 상태를 의미한다.
영속 상태는 영속성 컨텍스트에 저장된 상태이다. 객체가 생성된 후 영속성 컨텍스트에 저장되어, 엔티티 매니저를 통해 데이터베이스와 상호작용할 수 있는 상태를 말한다.
이외에도 영속성 컨텍스트에 저장되었다가 분리된 상태인 준영속 상태가 있다.
엔티티 예시 코드
간단한 블로그 시스템을 가정해 보도록 하자. 블로그 시스템에는 두 가지 주요 엔티티인 "게시글(Post)"과 "댓글(Comment)"이 있다. 이 두 엔티티 간의 관계를 코드로 나타내면 다음과 같다.
@Data
@Entity
public class Post {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
@OneToMany(mappedBy = "post", cascade = CascadeType.ALL)
private List<Comment> comments = new ArrayList<>();
// 게시글에 댓글을 추가하는 메서드
public void addComment(Comment comment) {
comments.add(comment);
comment.setPost(this);
}
}@Data
@Entity
public class Comment {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String content;
@ManyToOne
private Post post;
}위 코드에서 게시글(Post) 엔티티는 여러 개의 댓글(Comment) 엔티티를 가질 수 있으며, Comment 엔티티는 한 개의 Post 엔티티에만 속할 수 있다.
이 관계에서 영속성은 다음과 같이 작용한다.
1. 게시글을 저장할 때 해당 게시글에 연결된 모든 댓글도 자동으로 저장된다. 이것은 cascade = CascadeType.ALL로 인해 가능하다.
2. 댓글이 새로 추가될 때는 addComment 메서드를 사용하여 댓글을 게시글에 추가하고, 동시에 댓글의 post 속성에 게시글을 설정한다.
이렇게 함으로써 영속성은 게시글과 댓글 간의 관계를 유지하고, 한 번에 모든 변경을 영속성 컨텍스트에 반영하여 데이터베이스에 일관된 상태를 유지할 수 있다.
💡JPQL
JPQL은 Java Persistence API(JPA)의 일부로, 객체지향적인 접근 방식을 통해 데이터베이스에 저장된 엔티티를 조회하기 위한 쿼리 언어이다.
SQL과 유사한 문법을 가지고 있으나, 엔티티 객체를 대상으로 쿼리를 작성하며 특정 데이터베이스에 의존하지 않는다는 특징이 있다. 이를 통해 개발자는 엔티티 객체를 중심으로 개발하면서도 데이터베이스와 효과적으로 상호작용할 수 있다.
JPQL의 문법
- SELECT: 조회할 엔티티나 엔티티 속성을 지정한다.
- FROM: 조회 대상이 되는 엔티티를 지정한다.
- WHERE: 조회할 엔티티를 필터링하는 조건을 지정한다.
- GROUP BY: 그룹화할 엔티티 속성을 지정한다.
- HAVING: 그룹화된 결과를 필터링하는 조건을 지정한다.
- ORDER BY: 조회 결과를 정렬하는 기준을 지정한다.
SELECT
String jpql = "SELECT m FROM Member m";
List<Member> result = em.createQuery(jpql, Member.class).getResultList();조회할 엔티티나 엔티티 속성을 지정한다. 엔티티를 조회할 때 사용된다.
FROM
String jpql = "SELECT m FROM Member m WHERE m.age > 18";
List<Member> result = em.createQuery(jpql, Member.class).getResultList();조회 대상이 되는 엔티티를 지정한다. FROM 절 다음에는 엔티티의 별칭을 사용하여 해당 엔티티에 대한 참조를 만들 수 있다.
WHERE
String jpql = "SELECT m FROM Member m WHERE m.age > 18";
List<Member> result = em.createQuery(jpql, Member.class).getResultList();조회할 엔티티를 필터링하는 조건을 지정한다. WHERE 절을 사용하여 필터링 조건을 지정할 수 있다.
GROUP BY
String jpql = "SELECT m.age, COUNT(m) FROM Member m GROUP BY m.age";
List<Object[]> result = em.createQuery(jpql).getResultList();그룹화할 엔티티 속성을 지정한다. 그룹화된 결과를 생성하고 그룹별로 집계 함수를 적용할 수 있다.
HAVING
String jpql = "SELECT m.age, COUNT(m) FROM Member m GROUP BY m.age HAVING COUNT(m) > 1";
List<Object[]> result = em.createQuery(jpql).getResultList();그룹화된 결과를 필터링하는 조건을 지정한다. HAVING 절은 GROUP BY 절 다음에 사용되며 그룹화된 결과에 대한 조건을 지정할 때 사용된다.
ORDER BY
String jpql = "SELECT m FROM Member m ORDER BY m.age DESC";
List<Member> result = em.createQuery(jpql, Member.class).getResultList();조회 결과를 정렬하는 기준을 지정한다. ORDER BY 절을 사용하여 정렬 기준을 지정할 수 있다.
Sub Query
String jpql = "SELECT m FROM Member m WHERE m.age > (SELECT AVG(m2.age) FROM Member m2)";
List<Member> result = em.createQuery(jpql, Member.class).getResultList();서브쿼리를 사용하여 더 복잡한 쿼리를 작성할 수 있다.
이 쿼리는 회원의 나이가 평균 나이보다 많은 회원을 조회하는 쿼리이다. 위 예시에서는 서브쿼리를 사용하여 평균 나이를 계산하고 이를 메인 쿼리의 조건으로 사용하고 있다.
💡Spring Data JPA CRUD 메서드
Spring Data JPA는 JpaRepository 인터페이스를 통해 공통적인 CRUD(Create, Read, Update, Delete) 기능을 제공하다. 이러한 CRUD는 몇 가지 간단한 메서드 호출로 데이터베이스 조작이 가능하다.
save(S)
새로운 엔티티를 저장하거나 이미 있는 엔티티를 병합한다. 새로운 엔티티를 저장할 때는 새로운 레코드가 데이터베이스에 삽입되고, 이미 존재하는 엔티티를 저장할 때는 해당 엔티티의 상태를 데이터베이스에 업데이트한다.
delete(T)
주어진 엔티티를 삭제한다. 내부적으로는 EntityManager의 remove() 메서드를 호출하여 데이터베이스에서 해당 엔티티를 삭제한다.
findById(ID)
주어진 식별자(ID)에 해당하는 엔티티를 조회한다. 내부적으로는 EntityManager의 find() 메서드를 사용하여 데이터베이스에서 엔티티를 검색한다.
getOne(ID)
주어진 식별자(ID)에 해당하는 엔티티를 프록시로 조회한다. 이 메서드는 엔티티가 실제로 사용될 때까지 데이터베이스에서 데이터를 로딩하지 않고, 프록시 객체를 반환한다.
findAll(…)
모든 엔티티를 조회한다. 이 메서드는 정렬(Sort)이나 페이징(Pageable) 조건을 파라미터로 받아와서 해당 조건에 맞게 데이터를 조회한다.
쿼리 작성 방법
Query Method 방식
public interface MemberRepository extends JpaRepository<Member, Long> {
// Spring Data JPA는 메소드 이름을 분석하여 JPQL을 생성 및 실행한다.
// 회원명이 username이며 나이가 age보다 큰 회원을 조회
List<Member> findByUsernameAndAgeGreaterThan(String username, int age);
}Query Method 방식은 메서드의 이름 자체를 이용하여 JPQL 쿼리를 생성하는 방식이다. 이를 통해 별도의 JPQL 쿼리를 작성하지 않고도 메서드명만으로 데이터를 조회할 수 있다.
이 메서드를 실행하면 다음과 같은 JPQL 쿼리가 실행된다.
select member0_.member_id as member_i1_0_, member0_.age as age2_0_, member0_.team_id as team_id4_0_, member0_.username as username3_0_
from member member0_
where member0_.username='AAA' and member0_.age > 15;위의 코드는 findByUsernameAndAgeGreaterThan 메서드를 정의하고 있다. 이 메서드는 메서드 이름을 분석하여 JPQL을 생성하고 실행한다. 메서드 이름에 따라 username과 age 필드를 이용하여 쿼리가 생성된다. 이 메서드를 호출하면 회원명이 주어진 username이며 나이가 주어진 age보다 큰 회원들을 조회하는 쿼리가 실행된다.
Query Method 방식은 메서드 이름에 규칙을 따라 JPQL을 생성하기 때문에 메서드명을 통해 어떤 동작을 하는지 쉽게 파악할 수 있다. 하지만 이 방식은 엔티티의 필드명에 의존하므로 필드명이 변경되면 메서드명도 변경해야 한다. 또한, 복잡한 쿼리를 작성하기 어려울 수 있다.
NamedQuery 방식
@Entity
@NamedQuery(
name = "Member.findByUsername",
query = "select m from Member m where m.username = :username"
)
public class Member {
private String username;
}NamedQuery 방식은 엔티티 클래스에 쿼리를 직접 정의하여 사용하는 방식이다.
위의 코드는 Member 엔티티 클래스에 @NamedQuery를 사용하여 이름이 "Member.findByUsername"인 쿼리를 정의하고 있다. 이 쿼리는 username 필드를 이용하여 회원을 조회하는 쿼리이다.
public interface MemberRepository extends JpaRepository<Member, Long> {
@Query(name = "Member.findByUsername")
List<Member> findByUsername(@Param("username") String username);
}MemberRepository 인터페이스에는 @Query 애노테이션을 사용하여 이 @NamedQuery를 호출하는 메서드가 선언되어 있다.
@Query repository 직접 정의 방식
public interface MemberRepository extends JpaRepository<Member, Long> {
// Query repository 직접 정의 방식
@Query("select m from Member m where m.username= :username and m.age = :age")
List<Member> findMember(@Param("username") String username, @Param("age") int age);
}위의 코드는 @Query 애노테이션을 사용하여 직접 쿼리를 정의하는 방식이다. 여기서는 메서드의 파라미터에 username과 age를 사용하여 쿼리를 작성하고 있다.
@Query 결괏값 DTO객체 바인딩하기
@Data
@AllArgsConstructor // DTO에 바인딩할 필드는 생성자 작업이 필수
public class MemberDto {
private Long id;
private String username;
private String teamName;
}실무에서는 가장 많이 사용되는 방식 중 하나는 결괏값을 DTO 객체에 바인딩하여 반환하는 방식이다. 이를 통해 엔티티와 DTO 사이의 변환 작업을 간소화할 수 있다.
위의 코드는 조회 결과를 바인딩할 DTO 객체인 MemberDto를 정의하고 있다.
public interface MemberRepository extends JpaRepository<Member, Long> {
// 객체DTO에 조회값 바인딩 하기
@Query("select new com.study.datajpa.dto.MemberDto(m.id, m.username, t.name) from Member m join m.team t")
List<MemberDto> findMemberDto();
}그리고 MemberRepository 인터페이스에는 @Query 애노테이션을 사용하여 쿼리를 정의하는데, 여기서는 조회 결과를 MemberDto 객체에 바인딩하여 반환한다. 이를 통해 엔티티와 DTO 사이의 변환 작업을 수행한다.
💡JPA 계층과 어노테이션
JPA (Java Persistence API)를 사용할 때는 전형적으로 엔티티 계층, 리포지토리 계층, 서비스 계층 세 가지 계층을 사용한다.
이러한 계층 구조는 애플리케이션의 데이터 관리와 비즈니스 로직을 분리하여 코드를 보다 모듈화 하고 관리하기 쉽게 만들어준다. 각 계층은 단일 책임 원칙을 따르며, 각각의 역할을 수행하여 애플리케이션의 유지보수성을 향상한다.
엔티티 계층 (Entity Layer)
엔티티 클래스는 애플리케이션의 데이터 모델을 정의하고, 이를 데이터베이스 테이블과 매핑한다. 이러한 클래스들은 주로 관련된 데이터를 저장하고 검색하기 위해 사용된다.
각 엔티티 클래스는 주로 @Entity 어노테이션을 사용하여 JPA가 해당 클래스를 엔티티로 인식하도록 표시된다.
엔티티 클래스는 데이터베이스 테이블과 매핑되는 필드를 포함하고, 관계를 설정하기 위해 @ManyToOne, @OneToMany, @OneToOne, @ManyToMany와 같은 관계 어노테이션을 사용할 수 있다.
@Entity
이 어노테이션은 JPA에게 해당 클래스가 엔티티임을 나타낸다.
이 어노테이션이 붙은 클래스는 데이터베이스의 테이블과 매핑된다.
즉, 데이터베이스의 데이터를 객체로 표현한 것이라고 할 수 있다.
@Table
이 어노테이션은 엔티티와 매핑될 테이블의 정보를 지정한다.
주로 테이블의 이름을 명시하기 위해 사용된다.
예를 들어, @Table(name = "users")와 같이 사용하여 엔티티를 "users"라는 테이블에 매핑할 수 있다.
@Id
이 어노테이션은 엔티티의 주요 식별자(primary key)를 나타낸다.
엔티티 클래스의 필드 중 하나를 주요 식별자로 지정할 때 사용된다.
주요 식별자는 해당 엔티티를 고유하게 식별하기 위해 사용된다.
@GeneratedValue
이 어노테이션은 주요 식별자 값의 생성 전략을 지정한다.
즉, 엔티티의 주요 식별자 값을 자동으로 생성하는 방법을 설정할 때 사용된다.
주로 자동으로 증가하는 값을 생성하는 방법을 선택한다.
@Column
이 어노테이션은 엔티티 클래스의 필드와 데이터베이스 테이블의 칼럼을 매핑한다.
칼럼의 이름, 널 허용 여부, 고유 여부, 길이 등의 속성을 설정할 수 있다.
예를 들어, @Column(name = "username", nullable = false, unique = true, length = 50)와 같이 사용할 수 있다.
@ManyToOne, @OneToMany, @OneToOne, @ManyToMany
이러한 관계형 어노테이션들은 엔티티 클래스 간의 관계를 설정한다.
@ManyToOne은 다대일 관계를, @OneToMany는 일대다 관계를, @OneToOne은 일대일 관계를, @ManyToMany는 다대다 관계를 설정한다.
이러한 관계 설정을 통해 엔티티 간의 관계를 표현하고 조작할 수 있다.
@JoinColumn
이 어노테이션은 관계형 데이터베이스의 외래 키를 매핑하는 데 사용된다.
부모 엔티티와 자식 엔티티 간의 관계를 설정하고 외래 키의 이름을 지정할 때 사용된다.
@Transient
이 어노테이션은 엔티티 클래스의 필드 중 데이터베이스에 저장되지 않을 필드를 나타낸다.
데이터베이스에 저장되지 않아야 할 일시적인 데이터나 계산된 값을 나타낼 때 사용된다.
리포지토리 계층 (Repository Layer)
리포지토리 계층은 엔티티에 대한 데이터 액세스를 캡슐화한다. 이 계층은 데이터베이스와의 상호 작용을 담당하며, 엔티티의 CRUD(Create, Read, Update, Delete) 작업을 처리한다.
주로 JpaRepository 인터페이스를 상속한 인터페이스를 사용하여 구현된다. JpaRepository는 Spring Data JPA에서 제공하는 인터페이스로, 일반적인 데이터 액세스 기능을 제공한다.
예시 코드
@Repository
public interface MemberRepository extends JpaRepository<Member, Long> {
List<Member> findByUsername(String username);
}Spring Data JPA를 사용하여 Member 엔티티에 대한 리포지토리를 정의했다.
JpaRepository는 Spring Data JPA에서 제공하는 인터페이스로, JpaRepository를 상속하여 사용한다. 이를 통해 기본적인 CRUD(Create, Read, Update, Delete) 작업을 지원한다. Member는 엔티티 타입을 나타내며, Long은 엔티티의 기본 키 타입이다.
findByUsername(String username) 메서드는 Spring Data JPA에서 제공하는 Query Creation 기능을 사용하여 메서드 이름을 분석하여 해당 필드를 기반으로 쿼리를 자동 생성한다. 이 경우, username 필드를 기반으로 Member 엔티티를 검색하는 메서드가 생성된다. 따라서 이 메서드를 호출하면 username 필드 값이 일치하는 모든 Member 엔티티가 반환된다.
JpaRepository 인터페이스
JpaRepository 인터페이스는 Spring Data JPA에서 제공하는 인터페이스로서, 데이터베이스와의 상호작용을 단순화하고 공통 CRUD(Create, Read, Update, Delete) 기능을 제공한다.
JpaRepository는 제네릭으로 엔티티 타입과 해당 엔티티의 식별자 타입을 받는다. 이를 통해 어떤 엔티티에 대해서든 CRUD 작업을 수행할 수 있다.
Spring Data JPA가 스스로 JpaRepository 인터페이스를 구현한 Proxy 객체(구현 클래스)를 생성한다. 따라서 개발자는 인터페이스만 정의하고, 구현체를 별도로 작성할 필요가 없다.
Spring Data JPA가 적용된 인터페이스는 Component-Scan의 대상이므로 @Repository 애노테이션을 생략할 수 있다. 즉, JpaRepository 인터페이스를 구현한 인터페이스는 자동으로 빈으로 등록된다.
@Repository
이 어노테이션은 Spring에서 데이터 액세스 예외를 처리하기 위해 사용된다.
해당 클래스가 데이터 액세스 계층의 구성 요소임을 나타내며, 이 어노테이션이 붙은 클래스는 Spring Bean으로 등록된다.
@JpaRepository
Spring Data JPA에서 제공하는 인터페이스로, JpaRepository 인터페이스를 상속하여 사용된다.
JpaRepository는 기본적인 CRUD 작업을 지원하며, 자동으로 구현체를 생성하여 사용할 수 있도록 도와준다.
JpaRepository를 상속한 인터페이스를 선언하면, 해당 리포지토리에 대한 CRUD 메서드를 자동으로 생성할 수 있다.
@Query
이 어노테이션은 사용자가 직접 쿼리를 정의하여 메서드에 매핑할 때 사용된다.
JPQL(Java Persistence Query Language) 또는 네이티브 SQL 쿼리를 사용할 수 있다.
메서드 이름만으로 쿼리를 생성하기 어려운 복잡한 쿼리를 작성할 때 유용하다.
public interface UserRepository extends JpaRepository<User, Long> {
@Query("SELECT u FROM User u WHERE u.username = :name")
List<User> findByUsername(@Param("name") String username);
}위의 예시에서 :name은 JPQL 쿼리에서 사용되는 바인딩 변수이다. @Param("name") 어노테이션은 메서드의 파라미터인 username을 JPQL 쿼리에서 사용할 수 있도록 지정한다. 이렇게 하면 메서드를 호출할 때 파라미터로 전달된 값이 JPQL 쿼리에 바인딩되어 실행된다.
@Param
@Query 어노테이션과 함께 사용되며, 메서드 파라미터를 JPQL 쿼리의 바인딩 변수에 매핑할 때 사용된다.
메서드의 파라미터 이름을 JPQL 쿼리에서 사용할 수 있도록 지정한다.
쿼리를 작성할 때 파라미터를 통한 구체적인 조건을 줘야 하는 경우가 있는데, 그럴 때 @Param 어노테이션을 통해 파라미터를 바인딩할 수 있다.
서비스 계층 (Service Layer)
서비스 계층은 비즈니스 로직을 처리하고 트랜잭션을 관리하는 데 사용된다.
이 계층은 여러 리포지토리를 조합하여 하나의 트랜잭션 안에서 여러 데이터 액세스 작업을 수행할 수 있다.
주로 비즈니스 로직의 구현과 트랜잭션 관리를 담당하는 서비스 클래스를 포함한다.
예시 코드
@Service
@Transactional
public class MemberService {
private final MemberRepository memberRepository;
public MemberService(MemberRepository memberRepository) {
this.memberRepository = memberRepository;
}
public List<Member> findMembersByUsername(String username) {
return memberRepository.findByUsername(username);
}
}@Service 어노테이션은 이 클래스가 서비스 역할을 하며, 스프링에 의해 빈으로 등록되어야 함을 나타낸다. 이 어노테이션을 통해 스프링이 해당 클래스를 찾아서 인스턴스를 생성하고 관리한다.
@Transactional 어노테이션은 이 클래스의 메서드가 트랜잭션 안에서 실행되어야 함을 나타낸다. 이 어노테이션이 붙은 클래스 내의 모든 메서드는 트랜잭션 범위 내에서 실행되며, 메서드 실행 중에 예외가 발생하면 롤백된다.
MemberRepository 인터페이스를 이 클래스의 생성자를 통해 주입받는다. 이는 의존성 주입(Dependency Injection)을 통해 해당 서비스 클래스가 데이터 액세스를 위해 필요로 하는 리포지토리를 사용할 수 있도록 한다.
findMembersByUsername() 메서드는 주어진 사용자 이름(username)에 해당하는 멤버를 조회하는 기능을 수행한다. 해당 메서드는 MemberRepository 인터페이스의 findByUsername() 메서드를 호출하여 데이터베이스에서 멤버를 검색하고, 그 결과를 반환한다.
@Service
이 어노테이션은 해당 클래스가 서비스 역할을 한다는 것을 표시한다.
Spring에게 해당 클래스가 비즈니스 로직을 수행하는 컴포넌트임을 알려준다. 또한, 해당 클래스를 Spring의 컨테이너에 빈으로 등록하여 의존성 주입을 편리하게 처리할 수 있도록 한다.
@Transactional
이 어노테이션은 해당 메서드에서 트랜잭션을 처리한다는 것을 나타낸다.
Spring에서 제공하는 트랜잭션 관리 기능을 사용하여 메서드 내의 데이터 액세스 작업을 단일 트랜잭션으로 묶어준다. 이를 통해 데이터베이스 작업 중에 예외가 발생하면 롤백되어 데이터의 일관성을 보장할 수 있다.
@Autowired
스프링에서는 빈으로 등록된 클래스들 간의 의존성을 주입하기 위해 @Autowired 어노테이션을 사용한다.
서비스 클래스에서 리포지토리 인터페이스를 주입받아야 할 때 사용될 수 있다.
@Qualifier
여러 개의 빈이 같은 타입으로 등록되어 있을 때, 어떤 빈을 주입할지를 지정해 줄 때 사용된다.
@Autowired와 함께 사용되며, 특정 빈을 지정할 때 사용된다.
@PostConstruct
이 어노테이션은 해당 메서드가 빈의 초기화 작업이 완료된 후에 호출되어야 함을 나타낸다. 따라서 서비스 클래스에서 초기화 작업을 수행하는 메서드에 사용될 수 있다.
@PreDestroy
이 어노테이션은 빈의 소멸 과정에서 특정 메서드가 호출되어야 함을 나타낸다.
빈이 소멸되기 직전에 실행되는 메서드에 사용된다.
💡JPA 데이터베이스 조작
JPA를 사용하여 간단한 멤버 엔티티를 만들고 데이터베이스 조작을 위한 Repository를 생성해 보도록 하자.
Team 엔티티
package com.example.demo.team;
import lombok.*;
import javax.persistence.*;
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
@Entity
public class Team {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false, length = 100)
private String name;
}Team 엔티티는 팀 정보를 담고 있는 객체이다.
id는 팀의 고유 식별자로, 자동으로 생성되며, name은 팀의 이름을 나타낸다.
TeamRepository 인터페이스
package com.example.demo.team;
import org.springframework.data.jpa.repository.JpaRepository;
public interface TeamRepository extends JpaRepository<Team, Long> {
}TeamRepository 인터페이스는 Team 엔티티의 CRUD 작업을 수행하기 위한 레포지토리이다.
Spring Data JPA를 사용하여 JpaRepository를 확장하며, Team 엔티티와 Long 타입의 id를 인자로 받는다.
Member 엔티티
package com.example.demo.member;
import com.example.demo.team.Team;
import lombok.*;
import javax.persistence.*;
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
@Entity
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false, length = 100)
private String name;
@ManyToOne(fetch = FetchType.LAZY)
private Team team;
public Member(String name) {
this.name = name;
}
}Member 엔티티는 회원 정보를 담고 있는 객체이다.
id는 회원의 고유 식별자로, 자동으로 생성되며, name은 회원의 이름을 나타낸다.
team은 회원이 속한 팀을 나타내며, ManyToOne 관계로 설정되어 있다.
MemberRepository 인터페이스
package com.example.demo.member;
import org.springframework.data.jpa.repository.JpaRepository;
public interface MemberRepository extends JpaRepository<Member, Long> {
}MemberRepository 인터페이스는 Member 엔티티의 CRUD 작업을 수행하기 위한 레포지토리이다.
Spring Data JPA를 사용하여 JpaRepository를 확장하며, Member 엔티티와 Long 타입의 id를 인자로 받는다.
MemberService 클래스
package com.example.demo.member;
import com.example.demo.team.Team;
import com.example.demo.team.TeamRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class MemberService {
private final MemberRepository memberRepository;
private final TeamRepository teamRepository;
@Autowired
public MemberService(MemberRepository memberRepository, TeamRepository teamRepository) {
this.memberRepository = memberRepository;
this.teamRepository = teamRepository;
}
public Member saveMember(String name, Long teamId) {
Team team = teamRepository.findById(teamId)
.orElseThrow(() -> new IllegalArgumentException("Invalid team Id:" + teamId));
Member member = new Member(name);
member.setTeam(team);
return memberRepository.save(member);
}
public Member getMember(Long id) {
return memberRepository.findById(id)
.orElseThrow(() -> new IllegalArgumentException("Invalid member Id:" + id));
}
public List<Member> getAllMembers() {
return memberRepository.findAll();
}
public Member updateMember(Long id, String name) {
Member member = memberRepository.findById(id)
.orElseThrow(() -> new IllegalArgumentException("Invalid member Id:" + id));
member.setName(name);
return memberRepository.save(member);
}
public void deleteMember(Long id) {
memberRepository.deleteById(id);
}
}MemberService 클래스는 회원 관리 비즈니스 로직을 처리하는 서비스이다.
saveMember 메서드는 회원을 저장하고, getMember 메서드는 회원을 조회한다. getAllMembers 메서드는 모든 회원 목록을 조회하고, updateMember 메서드는 회원 정보를 업데이트하며, deleteMember 메서드는 회원을 삭제한다.
MemberController 클래스
package com.example.demo.member;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
@RestController
@RequestMapping("/members")
public class MemberController {
private final MemberService memberService;
@Autowired
public MemberController(MemberService memberService) {
this.memberService = memberService;
}
@PostMapping
public Member addMember(@RequestBody String name, @RequestParam Long teamId) {
return memberService.saveMember(name, teamId);
}
@GetMapping
public List<Member> getAllMembers() {
return memberService.getAllMembers();
}
@GetMapping("/{id}")
public Member getMember(@PathVariable Long id) {
return memberService.getMember(id);
}
@PutMapping("/{id}")
public Member updateMember(@PathVariable Long id, @RequestBody String name) {
return memberService.updateMember(id, name);
}
@DeleteMapping("/{id}")
public void deleteMember(@PathVariable Long id) {
memberService.deleteMember(id);
}
}MemberController 클래스는 회원 관리에 대한 HTTP 요청을 처리하는 컨트롤러이다.
addMember 메서드는 회원을 추가하고, getAllMembers 메서드는 모든 회원 목록을 조회한다. getMember 메서드는 특정 회원을 조회하고, updateMember 메서드는 회원 정보를 업데이트하며, deleteMember 메서드는 회원을 삭제한다.
참고 자료
<JPA> 객체지향 쿼리 언어1 - 기본 문법, 라모스, 2022.02.04.
<JPA> 객체지향 쿼리 언어2 - 중급 문법, 라모스, 2022.02.11.
JPA로 데이터베이스 사용하기, wikidocs, 2024.01.21.
[JPA] JPA란 ? 그리고 Spring Data JPA, Hyeon0208, 2023.04.24.
[JPA] JPQL이란? 사용방법, 기본 문법 총 정리, Hyeon0208, 2023.06.09.
[JPA] 사용자 정의 쿼리 작성과 파라미터 바인딩(@Query, @Param), Hyeon0208, 2023.06.09.
[JPA] 영속성 컨텍스트란?,
[JAVA] - JPA란? 간단하고 쉽게 이해하기(예제코드 완벽정리), 꼼코더, 2023.03.21.
[DB] ORM (Object Relational Mapping) 사용 이유, 장단점, Rachel, 2020.10.01.
