
인공지능(AI) 기술이 급속히 발전하면서 자연어 처리(NLP) 분야에서도 새로운 혁신이 등장하고 있다. 특히 RAG(Retrieval-Augmented Generation)는 정보 검색(IR)과 자연어 생성(NLG)을 결합한 기술로, AI가 더 정확하고 풍부한 정보를 제공할 수 있도록 돕는다.
💡RAG란?
RAG는 Retrieval-Augmented Generation의 약자로, '검색 증강 생성 기술'이라고 할 수 있다.
이 기술은 대규모 언어 모델(LLM, Large Language Model)과 정보 검색 시스템을 결합하여, AI가 사용자의 질문에 대해 더욱 신뢰할 수 있고 정보가 풍부한 답변을 제공할 수 있도록 한다.
LLM은 GPT-3와 같은 모델을 말하며, 방대한 데이터를 학습해 자연스러운 언어 생성 능력을 가지고 있다.
RAG는 이 LLM의 능력을 한 단계 더 발전시켜, 단순히 학습된 정보만을 기반으로 답변을 제공하는 것이 아니라, 실시간으로 외부 데이터를 검색하여 보다 정확하고 최신의 정보를 포함한 답변을 생성한다. 이는 마치 거대한 도서관에서 필요한 책을 찾아 정보를 얻고, 그 정보를 바탕으로 이야기를 만들어내는 것과 비슷하다.
LLM (Large Language Model)
LLM은 대규모 언어 모델을 의미한다. 이러한 모델은 대규모 데이터셋에서 학습하여 자연어 처리(NLP) 작업을 수행하는 인공지능(AI) 기술의 핵심이다. LLM은 방대한 양의 텍스트 데이터를 학습하여, 인간처럼 이해하고 생성할 수 있는 능력을 갖추게 된다.
2024.03.11 - [Programming/AI] - [LLM] AI 모델 최적화 방법 Fine-Tuning과 Prompt-Tuning
[LLM] AI 모델 최적화 방법 Fine-Tuning과 Prompt-Tuning
언어 모델(LM)은 텍스트 데이터를 이해하고 생성하는 인공지능(AI) 모델이다. 최근에는 대규모 언어 모델(LLM)이 뜨거운 주제 중 하나로, 원하는 태스크에 맞춰 튜닝하는 방식으로 발전하고 있다.Fi
isaac-christian.tistory.com
LLM에 대해서는 위 글을 참고한다.
LLM과 RAG의 구조
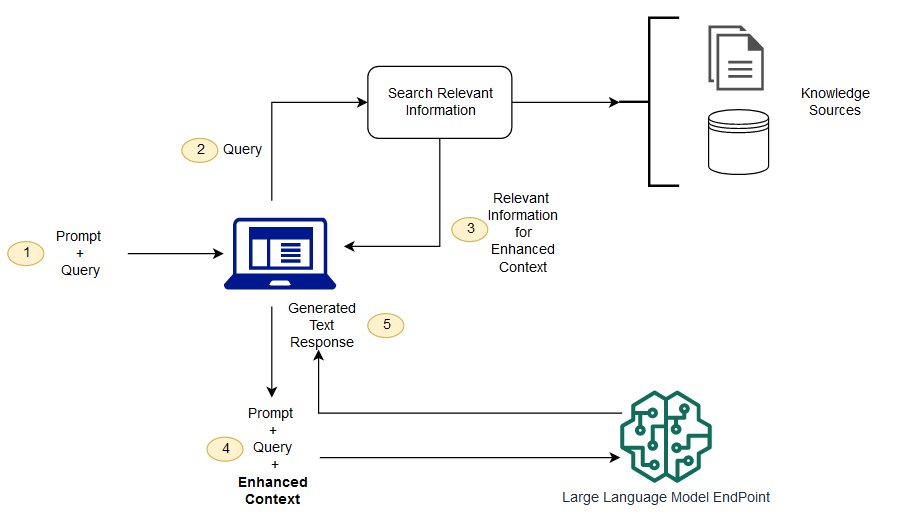
LLM과 RAG의 상호작용은 두 기술의 강점을 결합하여 더 나은 결과를 도출하는 방식으로 이루어진다.
- 질문 입력: 사용자가 질문을 입력하면, 이 질문은 먼저 RAG 시스템으로 전달된다.
- 검색: RAG의 검색 부분은 질문에 관련된 정보를 외부 데이터베이스에서 실시간으로 검색한다. 이는 최신 정보와 특정 도메인 지식을 포함한다.
- 결합 및 생성: 검색된 정보를 바탕으로 LLM이 답변을 생성한다. 이 과정에서 LLM은 검색된 문서의 내용을 이해하고 이를 바탕으로 자연스럽고 정확한 답변을 제공한다.
- 출력: 최종 답변은 사용자가 이해하기 쉽게 후처리 과정을 거쳐 출력된다.
RAG의 작동 원리
RAG 기술은 크게 다음의 두 가지 주요 구성 요소로 이루어져 있다.
1. 검색 부분 (Retrieval Component)
검색 부분은 사용자의 질문이나 입력을 받아 관련된 정보를 대규모 데이터베이스나 문서 집합에서 찾아내는 과정이다.
- 질문 이해: 사용자의 질문이나 요청을 이해하고, 이를 바탕으로 필요한 정보를 결정한다.
- 정보 검색: 고도화된 검색 엔진이나 데이터베이스 관리 시스템을 사용하여 방대한 양의 데이터 속에서 질문에 적합한 정보를 빠르게 찾아낸다.
- 최적화된 검색 알고리즘: 검색 엔진은 주로 TF-IDF(Term Frequency-Inverse Document Frequency), BM25, 혹은 최신 딥러닝 기반의 검색 알고리즘을 사용하여, 질문과 가장 관련성이 높은 문서를 선택한다.
2. 생성 부분 (Generation Component)
생성 부분은 검색된 정보를 바탕으로 자연스럽고 정확한 언어로 답변을 생성하는 과정이다.
- 정보 통합: 검색된 여러 문서나 정보 조각을 통합하고, 이를 바탕으로 질문에 대한 전반적인 이해를 도모한다.
- 언어 모델 적용: GPT-3와 같은 전이 학습(transformer-based) 모델을 사용하여, 통합된 정보를 바탕으로 자연스럽고 일관된 답변을 생성한다.
- 응답 생성: 최종적으로 사용자의 질문에 가장 적합하고, 정확한 답변을 생성한다.
RAG의 장점
1. 실시간으로 외부 데이터를 검색하여 최신 정보를 반영할 수 있다.
- 실시간 업데이트: RAG는 최신 기사, 연구 논문, 데이터베이스 등을 실시간으로 검색하여 사용자의 질문에 가장 최신의 정보를 제공한다.
- 적응력 향상: 빠르게 변하는 상황에서도 최신 데이터를 반영하여 적응력을 높인다.
2. 검색된 데이터를 기반으로 답변을 생성하므로, 답변의 정확성과 신뢰성이 높아진다.
- 신뢰성 강화: 신뢰할 수 있는 출처에서 데이터를 검색하여, 답변의 정확성을 높인다.
- 정확한 답변: 검색된 정보를 바탕으로 생성된 답변은 더욱 정확하고 세밀하다.
3. 다양한 분야에서 활용될 수 있다.
- 교육: 학생의 질문에 대해 최신 연구 결과를 반영한 답변을 제공할 수 있다.
- 고객 서비스: 고객 문의에 대한 신속하고 정확한 답변을 제공하여 만족도를 높일 수 있다.
- 콘텐츠 제작: 풍부한 정보를 바탕으로 양질의 콘텐츠를 대량으로 생성할 수 있다.
💡RAG의 구조와 세부 작동 방식
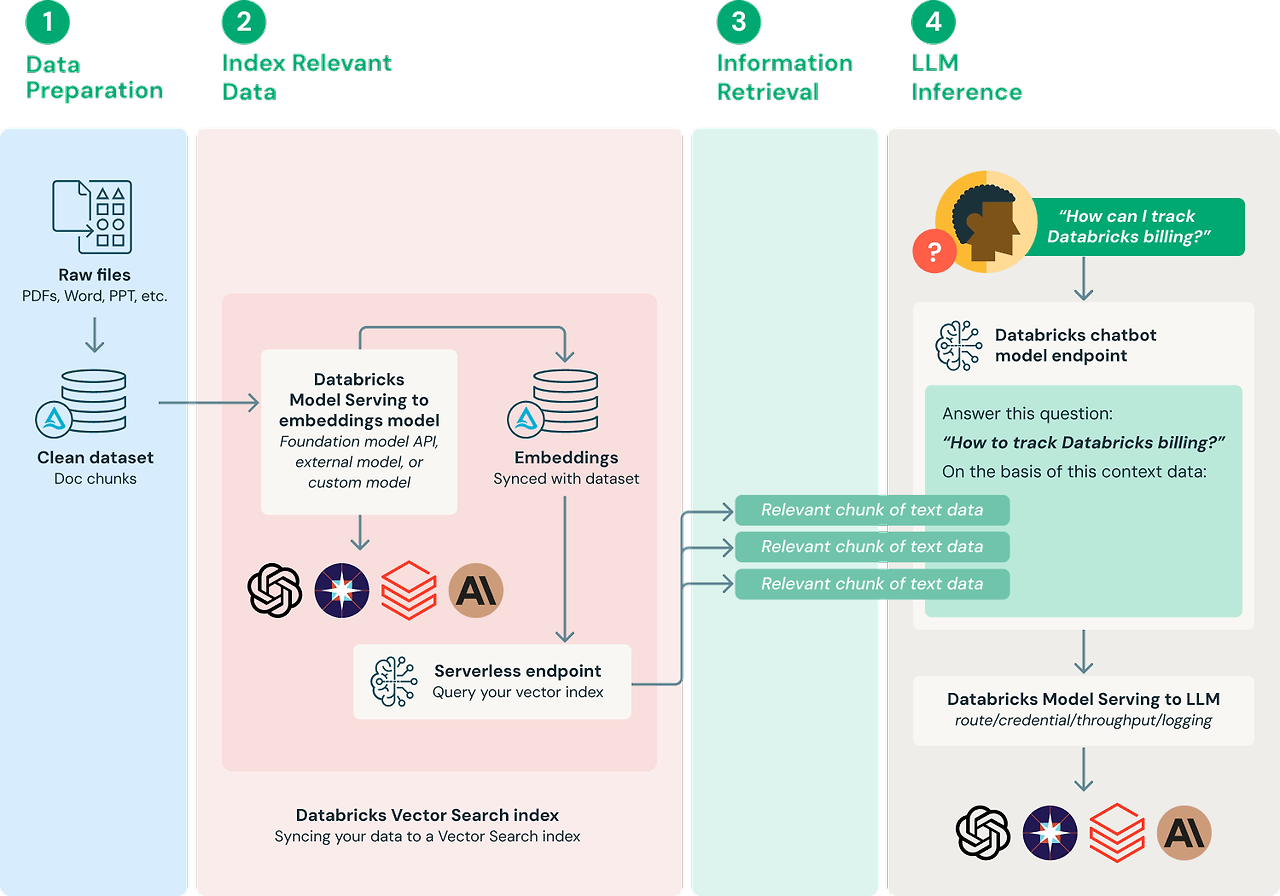
RAG 시스템의 구현은 다음과 같은 단계로 이루어진다.
RAG 시스템 구현 과정
1. 데이터 준비
데이터 준비는 RAG 시스템에서 사용할 문서 데이터를 수집하고 이를 처리하는 단계이다.
- 데이터 수집: 다양한 출처에서 문서 데이터를 수집한다. 예를 들어, 뉴스 기사, 학술 논문, 웹페이지, 데이터베이스 등이 포함될 수 있다.
- 데이터 전처리: 수집된 데이터를 적절한 길이로 나눈다. 긴 문서는 여러 개의 짧은 문서로 분할하여 처리한다.
- 개인 식별 정보(PII) 처리: 개인정보 보호를 위해 문서에서 개인 식별 정보를 제거하거나 익명화하는 작업을 수행한다.
- 토큰화 및 정규화: 텍스트 데이터를 토큰화하고, 소문자 변환, 구두점 제거 등 정규화 과정을 거친다.
2. 인덱싱
인덱싱은 문서 데이터를 검색 가능하도록 하는 단계이다.
- 임베딩 생성: 각 문서의 의미를 벡터로 표현하는 임베딩을 생성한다. 이 작업에는 BERT, RoBERTa와 같은 사전 학습된 언어 모델이 사용된다.
- 벡터 저장: 생성된 임베딩 벡터를 벡터 공간에 저장한다. 이를 통해 문서 간의 유사도를 계산할 수 있다.
- 효율적인 검색을 위한 구조화: 빠른 검색을 위해 임베딩 벡터를 효율적으로 관리한다. 예를 들어, ANN(Approximate Nearest Neighbor) 알고리즘을 사용하여 검색 속도를 향상시킨다.
3. 검색
검색은 사용자의 질문에 대해 관련된 문서 임베딩을 하는 단계이다.
- 질문 임베딩 생성: 사용자의 질문을 임베딩 벡터로 변환한다.
- 유사도 계산: 질문 임베딩과 문서 임베딩 간의 유사도를 계산한다. 이때 자주 사용되는 알고리즘은 최대 내적 탐색(MIPS, Maximum Inner Product Search)이다.
- 관련 문서 선택: 유사도가 높은 문서들을 선택하여 다음 단계로 넘긴다.
4. 생성
생성은 선택된 문서를 바탕으로 자연스러운 답변을 하는 단계이다.
- 문서 결합: 검색된 관련 문서들을 통합하여, 질문에 가장 적합한 정보를 포함하도록 한다.
- 답변 생성: GPT-3와 같은 전이 학습(transformer-based) 모델을 사용하여, 통합된 문서를 바탕으로 답변을 생성한다.
- 후처리: 생성된 답변을 검토하고, 문법 오류 수정, 적절한 문장 구조 형성 등 후처리 작업을 수행한다.
RAG의 실제 작동 예시
예를 들어, 사용자가 "현재 지구 온난화의 영향은 무엇인가요?"라는 질문을 한다고 가정해 보도록 하자.
1. 데이터 준비: 다양한 최신 연구 논문, 뉴스 기사, 환경 보고서 등을 수집하여 데이터베이스를 구축한다.
2. 인덱싱: 각 문서에서 지구 온난화 관련 부분을 추출하고 임베딩을 생성하여 벡터 공간에 저장한다.
3. 검색: 질문 "현재 지구 온난화의 영향은 무엇인가요?"를 임베딩 벡터로 변환하고, 관련 문서 임베딩을 검색하여 가장 유사한 문서를 선택한다.
4. 생성: 선택된 문서들을 바탕으로 GPT-3가 답변을 생성한다. 예를 들어, "현재 지구 온난화는 극지방의 빙하를 녹이고 해수면 상승을 유발하고 있으며, 이는 해안 도시의 침수 위험을 증가시키고 있습니다."라는 답변을 생성한다.
참고 자료
What Is Retrieval Augmented Generation, or RAG?, databricks, 2024.07.28.
검색 증강 생성(RAG)이란 무엇인가요?, aws, 2024.07.28.
RAG (검색증강생성)이란?, GAI.T, 2024.02.04.
RAG와 LLM 결합 : 자연어 처리의 새로운 지평(Retrieval-Augmented Generation), 테크씬, 2023.10.27.
