
언어 모델(LM)은 텍스트 데이터를 이해하고 생성하는 인공지능(AI) 모델이다. 최근에는 대규모 언어 모델(LLM)이 뜨거운 주제 중 하나로, 원하는 태스크에 맞춰 튜닝하는 방식으로 발전하고 있다.
Fine-Tuning과 Prompt-Tuning은 인공지능(AI) 출력을 최적화하는 데 사용되는 기술이다. 먼저 요약으로 각 기술에 대한 설명을 한눈에 확인해 보도록 하자.
🔎한눈에 보기
LLM(대규모 언어 모델)은 많은 양의 텍스트 데이터를 사용하여 학습된 인공지능 모델을 의미한다. 이 모델들은 자연어 이해 및 생성 작업에 탁월한 성능을 보이며, 예측, 번역, 요약 등 다양한 자연어 처리 작업에 사용된다.
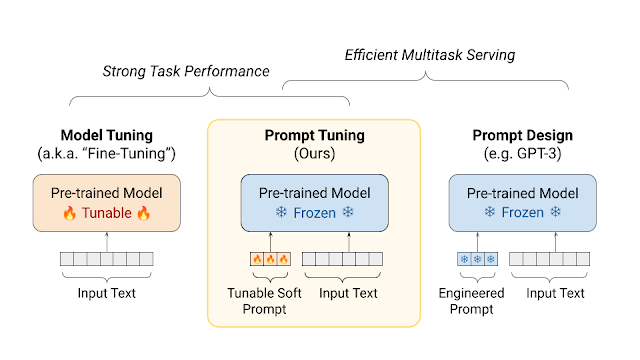
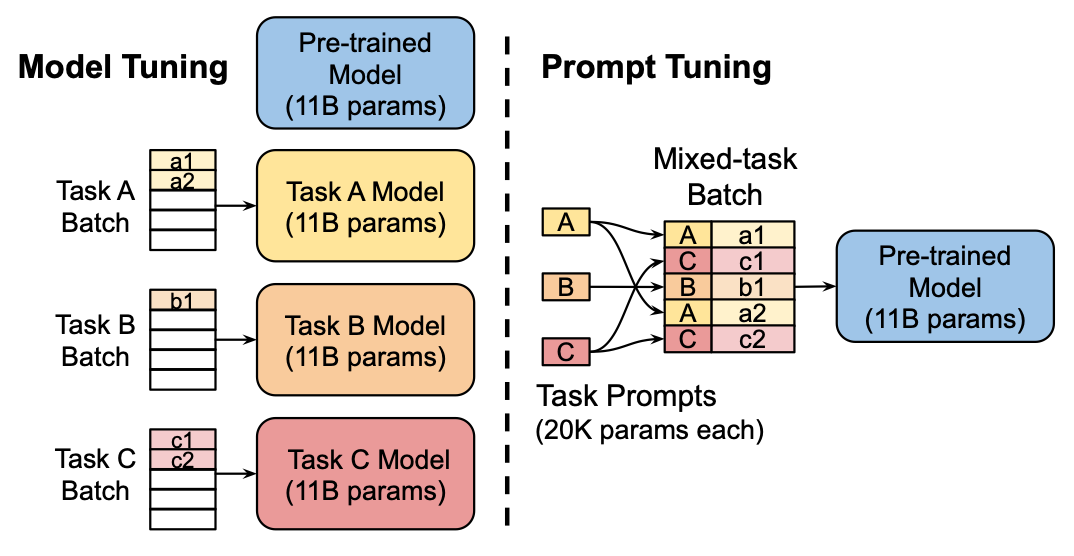
Fine-Tuning은 미리 학습된 모델을 특정 작업이나 데이터셋에 맞게 재학습시키는 과정을 의미한다. 이를 통해 기존 모델을 새로운 작업에 적용할 수 있으며, 작업에 특화된 성능을 높일 수 있다.
Prompt-Tuning은 모델의 출력을 조절하기 위해 사용되는 텍스트 입력 방식을 의미한다. 이 방법은 모델에 입력되는 텍스트에 특정 지시사항이나 조건을 추가하여 모델의 출력을 원하는 방향으로 유도한다.
Fine-Tuning과 Prompt-Tuning은 언어 모델을 최적화하는 방법이다. 즉, 특정 작업에 AI를 적용하기 위해 사용되는 기술이라고 할 수 있다. 이는 모델의 성능과 출력을 개선하고, 원하는 결과를 도출하는 데 사용된다. 하지만 이 두 기술은 서로 다른 기술을 사용하며 모델 훈련에서 각각 다른 역할을 한다.
💡LLM
Fine-Tuning(파인튜닝)과 Prompt-Tuning(프롬프트 튜닝)을 이해하기 위해 먼저 LLM이 무엇인지 알아야 한다.
LLM(Large Language Models)은 대규모 언어 모델을 나타내는데, 이 모델들은 수많은 매개변수와 텍스트 데이터를 기반으로 학습되어 자연어 이해, 생성, 번역 등 다양한 자연어 처리 작업에 사용된다.
이전에는 대규모의 모델을 훈련시키는 데 필요한 데이터와 컴퓨팅 리소스가 제한되어 있었다. 그러나 최근의 발전으로 LLM은 언어 이해와 생성에서 엄청난 진보를 이루어내고 있다. 그러나 모든 작업이나 도메인에 대해 특정한 사전 훈련된 모델이 완벽하게 맞는 것은 아니다. 이때 사용되는 것이 바로 Fine-Tuning이다.
💡Fine-Tuning
Fine-Tuning은 사전 훈련된 언어 모델을 특정 작업에 맞게 조정하는 과정이다. 주어진 작업에 대한 데이터셋을 사용하여 모델의 가중치를 조정하거나 특정 작업에 대한 손실 함수를 최적화하는 방식으로 해당 작업에 더 잘 적응하도록 만든다. 이를 통해 모델은 특정 작업에 더 뛰어난 성능을 발휘할 수 있다.
모델 최적화
Fine-Tuning의 핵심은 풍부한 지식을 가진 모델을 새로운 작업에 맞게 조정하는 것이다. 이를 위해 먼저 목표 작업의 데이터를 사용하여 모델을 재훈련해야 한다. 그러나 전체 모델을 새로 훈련시키는 것이 아니라, 모델의 일부 레이어만을 업데이트한다. 이는 초기에 학습된 일반적인 언어 이해 능력을 유지하면서도 특정 작업에 더 적합하도록 모델을 조정하는 데 도움이 된다.
Model-Tuning
모델 튜닝은 모델의 하이퍼파라미터를 조정하여 최적의 성능을 얻는 과정을 의미한다. 예를 들어, 신경망의 레이어 수, 뉴런의 수, 학습률 등을 조정하여 모델의 성능을 향상하는 작업을 포함한다.
모델 튜닝과 파인 튜닝은 모두 모델의 성능을 향상시키기 위한 과정을 의미하며, 두 용어는 대체로 유사한 맥락에서 사용된다.
지도 학습과 비지도 학습
Fine-Tuning은 지도 학습과 비지도 학습의 형태로 이루어질 수 있다. 지도 학습에서는 작업별 레이블이 지정된 데이터를 사용하여 모델을 조정한다. 반면에, 비지도 학습에서는 레이블이 없는 데이터를 사용하여 모델을 특정 작업에 맞게 조정한다. 지도학습은 목표(target) 또는 결과(outcome) 변수를 예측하는 것을 의미한다. 주로 연속형 또는 범주형 결과변수에 대한 예측을 포함한다. 그리고 비지도학습은 자료를 의미있는 그룹으로 구분하거나 패턴을 찾는 것을 의미한다.
2024.01.05 - [Programming/R] - [R] 데이터마이닝의 이해: BA와 BI, 기계학습, 지도학습과 비지도학습
[R] 데이터마이닝의 이해: BA와 BI, 기계학습, 지도학습과 비지도학습
💡비즈니스 애널리틱스 (Business Analytics, BA) 비즈니스 애널리틱스는 데이터를 분석하는 도구와 기법을 의미하며, 데이터를 분석하여 정량적인 정보를 도출한다. 온라인 분석처리(OLAP), 통계기법,
isaac-christian.tistory.com
지도학습과 비지도 학습에 대해서는 위 글을 참고한다.
Fine-Tuning의 장단점
장점
1. 특화된 작업을 처리한다.
Fine-Tuning은 모델을 특정 작업에 맞게 깊이 최적화할 수 있다. 이는 모델이 해당 작업의 특성을 더 잘 이해하고 반영할 수 있게 돕는다. 예를 들어, 기계 번역 작업에서는 번역에 필요한 문법 규칙이나 어휘 선택과 같은 특수한 요구사항이 있을 수 있다. Fine-Tuning을 통해 모델은 이러한 작업 특성을 더 잘 이해하고, 번역 작업에 보다 적합한 결과를 생성할 수 있게 된다.
2. 정확도가 향상된다.
새로운 데이터에 대한 예측 정확도를 향상할 수 있다. 특히, 전문 용어나 문맥적 뉘앙스가 중요한 작업에서 유용하게 사용될 수 있다. Fine-Tuning을 통해 모델은 해당 작업에 대한 특정한 지식을 습득하고, 이를 기반으로 정확한 예측을 수행할 수 있다. 이는 특히 일반적인 모델이 해당 작업에 대한 지식을 갖고 있지 않을 때 유용하다.
단점
1. 데이터 및 시간이 많이 필요하다.
Fine-Tuning은 많은 양의 레이블링 된 데이터와 학습 시간을 요구한다. 특히, 큰 모델과 복잡한 데이터셋을 다룰 때 많은 자원이 소모된다. 이는 데이터를 수집하고 레이블을 달기 위한 비용과 시간이 추가로 소요되는데, 특히 데이터가 희소하거나 작업이 특정 도메인에 특화되어 있는 경우 더 큰 어려움이 될 수 있다.
2. 과적합의 위험이 있다.
작은 데이터셋으로 Fine-Tuning을 수행할 경우, 모델이 특정 데이터에 지나치게 최적화되어 일반화 능력이 떨어질 수 있다. 특히, 레이블 된 데이터가 부족하거나 작업이 복잡한 경우, 모델은 훈련 데이터의 패턴을 지나치게 외우는 경향이 있어 일반화 능력이 감소할 수 있다. 이는 새로운 데이터나 다른 환경에서 모델의 성능이 저하되는 과적합 문제를 야기할 수 있다.
Fine-Tuning의 과정
1. 기본 모델 선택
파인튜닝을 위해서는 사전에 학습된 기본 모델이 필요하다. 이 모델은 대규모 데이터셋에서 일반적인 언어 이해를 학습한 것이다.
2. 파인튜닝 데이터 수집 및 준비
특정 작업에 관련된 추가 데이터를 수집하고 준비한다. 이 데이터는 모델을 해당 작업에 맞게 조정하는 데 사용된다.
예를 들어, 영화 리뷰 감정 분석을 위한 모델을 만든다면, IMDb나 Rotten Tomatoes 등의 영화 리뷰 데이터를 수집하고 준비한다.
3. 모델 파인튜닝
선택한 기본 모델을 사용하여 수집한 추가 데이터를 통해 모델을 파인튜닝한다. 이 과정에서 모델은 특정 작업에 대한 세부 정보를 학습하게 된다.
파인튜닝 과정에서는 모델의 일부 층을 동결하고 일부 층을 재학습시키는 등의 방법을 사용하여 모델을 해당 작업에 맞게 조정한다.
4. 평가 및 조정
파인튜닝된 모델을 평가하고 필요에 따라 추가적인 조정을 수행한다.
이 단계에서는 주로 검증 데이터셋을 사용하여 모델의 성능을 평가하고 필요한 경우 하이퍼파라미터를 조정하거나 추가적인 학습을 수행하여 모델의 성능을 향상한다.
Fine-Tuning의 활용 예시
Fine-Tuning 기술은 다양한 산업 및 응용 분야에서 사용될 수 있다. 자연어 처리, 이미지 분석, 음성 인식 등 다양한 분야에서 Fine-Tuning을 통해 LLM을 특정 작업에 적용할 수 있다. 더 나아가, Fine-Tuning을 통해 일반적인 사전 훈련된 모델을 사용하여 특정 산업이나 도메인에 맞는 사용자 지정 모델을 만들 수 있다.
의료 이미지 분석
의료 이미지 분석에서는 Fine-Tuning을 사용하여 특정 질병을 감지하는 데 필요한 고도의 정밀도를 갖춘 모델을 개발할 수 있다. 모델을 의료 분야에 맞게 Fine-Tuning 하여 해당 질병의 특징을 정확하게 식별할 수 있다.
감정 분석
감정 분석에서는 특정 도메인이나 언어에 대한 감정을 분석하는 데 Fine-Tuning을 활용할 수 있다. 예를 들어, 특정 브랜드나 제품에 대한 고객 리뷰의 감정을 파악하는 데 Fine-Tuning을 사용하여 모델을 특정 도메인에 맞게 조정할 수 있다.
💡Prompt-Tuning
Prompt-Tuning은 새로운 작업에 적응시키기 위해 가장 적합한 특정 Prompt(입력 텍스트) 매개변수를 찾아 모델을 튜닝하는 과정이다. 이는 LLM이 특정 작업을 수행하도록 유도하는 텍스트나 명령을 의미한다.
Prompt-Tuning은 주어진 작업의 요구사항과 목적에 따라 모델의 입력을 조정하여 성능을 최적화한다. 이를 통해 특정 작업에 대한 성능을 개선하거나 모델이 원하는 방식으로 동작하도록 할 수 있다.
Prompt-Tuning의 장단점
장점
1. 데이터 효율성이 높다.
Prompt-Tuning은 적은 데이터로도 효과적인 결과를 얻을 수 있다. 이미 사전 학습된 모델의 지식을 활용하여 작은 양의 추가 데이터만으로도 모델을 특정 작업에 적용할 수 있다. 이는 데이터를 효율적으로 활용하여 모델을 개선할 수 있는 장점을 제공한다.
2. 빠르게 적용할 수 있다.
전체 모델을 재학습할 필요가 없기 때문에 Prompt-Tuning은 빠르게 적용할 수 있다. 특히 시간에 민감한 프로젝트에 유용하며, 새로운 작업에 대한 모델을 빠르게 구축하고 테스트할 수 있다.
단점
1. 맞춤화가 제한적이다.
Fine-Tuning에 비해 Prompt-Tuning의 맞춤화 정도가 제한적일 수 있다. 특정 작업에 대한 깊은 최적화가 필요한 경우, 이 방법만으로는 한계가 있을 수 있다. 따라서 특정 작업에 더 깊이 맞춤화할 필요가 있는 경우에는 Fine-Tuning을 선택하는 것이 더 적절할 수 있다.
2. 프롬프트 설계가 어렵다.
효과적인 프롬프트를 설계하는 것은 쉽지 않다. 정확하고 효과적인 프롬프트를 개발하기 위해서는 해당 작업의 전문 지식과 언어 모델의 작동 방식을 잘 이해해야 한다. 또한, 프롬프트가 작업을 명확하게 정의하고 모델이 올바른 결과를 생성하도록 유도하는 데 필요한 정보를 제공해야 한다
Prompt-Tuning의 과정
1. 데이터 수집 및 준비
특정 작업에 관련된 데이터를 수집한다. 이 데이터는 모델이 특정 작업을 수행하기 위해 필요한 정보를 포함한다.
예를 들어, 의료 도메인에서의 질문 응답 시스템을 만든다면, 의료 관련 질문과 해당 질문에 대한 정확한 답변으로 구성된 데이터셋을 수집한다.
2. 모델 학습
수집한 데이터를 사용하여 모델을 학습한다.
모델에 입력되는 것은 주로 질문에 해당하는 텍스트인 "프롬프트"이다. 모델은 이 프롬프트를 기반으로 질문에 대한 답변을 생성하는 방식으로 학습된다.
이 과정에서 모델은 주어진 프롬프트와 관련된 문맥을 이해하고, 이를 바탕으로 적절한 답변을 생성하는 방법을 학습한다.
3. 평가 및 튜닝
학습된 모델을 평가하고 필요에 따라 추가적인 튜닝을 수행한다.
평가는 일반적으로 테스트 데이터셋을 사용하여 수행된다. 모델이 주어진 질문에 대해 올바른 답변을 생성하는지 확인하고 성능을 평가한다.
필요한 경우 모델의 하이퍼파라미터를 조정하거나 추가적인 학습을 수행하여 모델의 성능을 향상한다.
Prompt-Tuning의 활용 예시
자연어 처리 작업
자연어 처리 작업에서는 번역, 요약, 질문 응답 등 다양한 작업에 대한 유연한 대응이 필요하다. Prompt-Tuning을 사용하여 모델을 특정 작업에 맞게 조정할 수 있으며, 이는 모델이 다양한 작업에 빠르게 적응할 수 있도록 도와준다.
챗봇 개발
챗봇 개발에서는 다양한 사용자 쿼리에 대응하는 모델이 필요하다. Prompt-Tuning을 사용하여 챗봇 모델을 다양한 대화 시나리오에 빠르게 적응할 수 있도록 조정할 수 있다.
💡Fine-Tuning과 Prompt-Tuning 과정 예시
영화 감정 분석
파인튜닝 과정
- 기본 모델 선택
- BERT라는 사전에 학습된 언어 모델을 선택하였다. BERT는 대규모 데이터셋에서 학습된 일반적인 언어 이해 모델이다.
- 파인튜닝 데이터 수집 및 준비
- IMDb(Internet Movie Database)에서 영화 리뷰 데이터를 수집하고 준비한다. 이 데이터는 영화 리뷰와 해당 리뷰의 감정(긍정 또는 부정)으로 구성되어 있다.
- 모델 파인튜닝
- BERT 모델을 선택하고 수집한 IMDb 영화 리뷰 데이터를 사용하여 모델을 파인튜닝한다.
- 모델 파라미터를 미세 조정하고 영화 리뷰 데이터에 맞게 모델을 학습시킨다. 이 과정에서는 모델의 일부 층을 동결하고 일부 층을 재학습시키는 등의 방법을 사용하여 모델을 해당 작업에 맞게 조정한다.
- 평가 및 조정
- 파인튜닝된 모델을 평가하고 필요에 따라 추가적인 조정을 수행한다.
- 이 과정에서는 주로 검증 데이터셋을 사용하여 모델의 성능을 평가하고, 필요한 경우 하이퍼파라미터를 조정하거나 추가적인 학습을 수행하여 모델의 성능을 향상한다.
프롬프트 튜닝 과정
- 데이터 수집 및 준비
- 영화 리뷰 데이터와 해당 리뷰의 감정(긍정 또는 부정)으로 구성된 데이터셋을 수집하고 준비한다.
- 모델 학습
- 수집한 데이터를 사용하여 모델을 학습한다.
- 모델에 입력되는 것은 주로 질문에 해당하는 텍스트인 "프롬프트"이다. 예를 들어, "이 영화는 긍정적인가요?"와 같은 형식의 프롬프트를 사용하여 모델을 학습시킨다.
- 평가 및 튜닝
- 학습된 모델을 평가하고 필요에 따라 추가적인 튜닝을 수행한다.
- 평가는 일반적으로 테스트 데이터셋을 사용하여 수행된다. 모델이 주어진 프롬프트에 대해 올바른 감정(긍정 또는 부정)을 생성하는지 확인하고 성능을 평가한다.
- 필요한 경우 모델의 하이퍼파라미터를 조정하거나 추가적인 학습을 수행하여 모델의 성능을 향상한다.
텍스트 생성
파인튜닝 과정
- 기본 모델 선택
- GPT-3라는 사전에 학습된 대규모 언어 모델을 선택한다. GPT-3는 다양한 종류의 텍스트 생성 작업에 탁월한 성능을 보인다.
- 파인튜닝 데이터 수집 및 준비
- 글쓰기 연습용 텍스트 데이터를 수집하고 준비한다. 이 데이터는 다양한 주제와 스타일의 텍스트로 구성된다.
- 모델 파인튜닝
- GPT-3 모델을 선택하고 수집한 글쓰기 연습용 텍스트 데이터를 사용하여 모델을 파인튜닝한다.
- 모델 파라미터를 미세 조정하고 텍스트 생성 작업에 맞게 모델을 학습시킨다.
- 평가 및 조정
- 파인튜닝된 모델을 평가하고 필요에 따라 추가적인 조정을 수행한다.
- 이 과정에서는 주로 생성된 텍스트의 품질을 평가하고, 필요한 경우 하이퍼파라미터를 조정하거나 추가적인 학습을 수행하여 모델의 성능을 향상시킨다.
프롬프트 튜닝 과정
- 데이터 수집 및 준비
- 특정 주제에 관련된 텍스트 데이터를 수집하고 준비한다.
- 모델 학습
- 수집한 데이터를 사용하여 모델을 학습한다.
- 모델에 입력되는 것은 주로 질문에 해당하는 텍스트인 "프롬프트"이다. 예를 들어, "프로그래밍에 대해 설명해 주세요."와 같은 형식의 프롬프트를 사용하여 모델을 학습시킨다.
- 평가 및 튜닝
- 학습된 모델을 평가하고 필요에 따라 추가적인 튜닝을 수행한다.
- 평가는 일반적으로 테스트 데이터셋을 사용하여 수행된다. 모델이 주어진 프롬프트에 대해 올바른 텍스트를 생성하는지 확인하고 성능을 평가한다.
- 필요한 경우 모델의 하이퍼파라미터를 조정하거나 추가적인 학습을 수행하여 모델의 성능을 향상한다.
💡Log Parsing
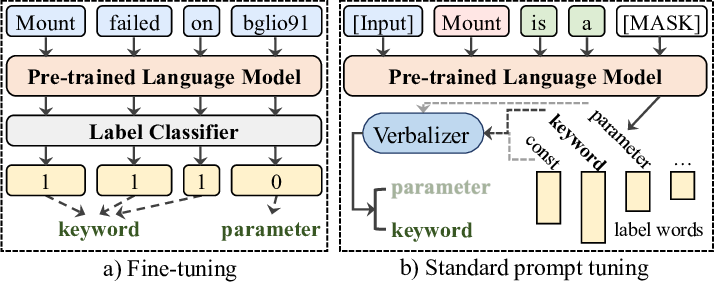
로그 파싱을 위한 Fine-Tuning과 Prompt-Tuning은 로그 데이터를 처리하고 분석하는 데 사용될 수 있는 중요한 기술이다. 로그는 시스템 작동 및 오류 정보를 기록하는 데 사용되며, 이러한 정보를 분석하여 시스템의 동작을 이해하고 문제를 해결하는 데 도움을 준다. 이러한 기술을 Fine-Tuning과 Prompt-Tuning을 통해 로그 데이터에 적용하는 것은 다음과 같은 과정을 포함할 수 있다.
Fine-Tuning for Log Parsing
로그 파싱 작업에 대해 Fine-Tuning을 수행할 때, 먼저 사전 학습된 모델을 가져와서 로그 데이터에 대한 추가 학습을 진행한다. 이를 통해 모델은 로그 메시지의 구조와 패턴을 학습하고, 로그 데이터를 파싱 하는 데 필요한 지식을 습득한다. 예를 들어, 로그 메시지의 유형을 식별하거나 특정 필드를 추출하는 작업을 수행할 수 있다.
Prompt-Tuning for Log Parsing
로그 파싱에 대한 Prompt-Tuning을 수행할 때, 특정 로그 메시지를 처리하기 위한 프롬프트를 설계한다. 이 프롬프트는 모델에게 로그 메시지를 파싱하고 원하는 정보를 추출하도록 지시한다. 예를 들어, "로그 메시지를 파싱 하여 날짜, 시간 및 오류 유형을 추출하라"와 같은 프롬프트를 사용하여 모델을 로그 파싱 작업에 대해 특정하게 지시할 수 있다.
적용 및 성능 평가
Fine-Tuning과 Prompt-Tuning을 통해 로그 파싱에 적용된 모델을 사용하여 실제 로그 데이터를 처리하고 분석한다. 이를 통해 모델이 로그 메시지를 올바르게 파싱하고 필요한 정보를 추출하는 데 얼마나 효과적인지를 평가할 수 있다. 성능 평가는 정확도, 처리 속도 및 리소스 사용량 등을 고려하여 수행될 수 있다.
Fine-Tuning과 Prompt-Tuning의 융합
Fine-Tuning과 Prompt-Tuning 각각의 장점을 결합하여 더욱 강력한 모델을 만들 수 있다. 먼저 Fine-Tuning을 통해 모델을 새로운 작업에 맞게 학습시킨 후, Prompt-Tuning을 사용하여 모델의 출력을 더욱 세밀하게 제어할 수 있다. 이러한 융합은 모델의 예측 성능을 향상하고, 원하는 출력을 보다 정확하게 조절할 수 있는 장점을 제공한다.
참고 자료
파인튜닝(Fine-tuning)이란? – LLM 구축 방법, appen, 2023.12.14.
Prompt engineering vs. fine-tuning: What's the difference?, Stephen J. Bigelow, 2023.08.21.
파인튜닝 VS 프롬프트 튜닝! AI 모델 최적화 방법 비교, Fine tuning, Prompt tuning, Znlsl, 2024.01.14.
프롬프트 튜닝(Prompt Tuning)이해하기! 프롬프트 원리, 장점, 주의점, Znlsl, 2024.01.14.
GPT-3 등장과 그 후: Prompting and Promt Tuning (Prefix-Tuning, P-Tuning), 이지혜, 2023.12.26.
Fine Tuning, Wikipedia, 2024.01.06.
Prompt engineering, Wikipedia, 2024.03.09.
The Art of Prompt Engneering — 1. Prompt Engineering이란 무엇인가?, daewoo kim, 2023.04.26.
An illustration of fine-tuning and prompt tuning for log parsing, Van-Hoang Le, Hongyu Zhang, 2023.02.

언어 모델(LM)은 텍스트 데이터를 이해하고 생성하는 인공지능(AI) 모델이다. 최근에는 대규모 언어 모델(LLM)이 뜨거운 주제 중 하나로, 원하는 태스크에 맞춰 튜닝하는 방식으로 발전하고 있다.
Fine-Tuning과 Prompt-Tuning은 인공지능(AI) 출력을 최적화하는 데 사용되는 기술이다. 먼저 요약으로 각 기술에 대한 설명을 한눈에 확인해 보도록 하자.
🔎한눈에 보기
LLM(대규모 언어 모델)은 많은 양의 텍스트 데이터를 사용하여 학습된 인공지능 모델을 의미한다. 이 모델들은 자연어 이해 및 생성 작업에 탁월한 성능을 보이며, 예측, 번역, 요약 등 다양한 자연어 처리 작업에 사용된다.
Fine-Tuning은 미리 학습된 모델을 특정 작업이나 데이터셋에 맞게 재학습시키는 과정을 의미한다. 이를 통해 기존 모델을 새로운 작업에 적용할 수 있으며, 작업에 특화된 성능을 높일 수 있다.
Prompt-Tuning은 모델의 출력을 조절하기 위해 사용되는 텍스트 입력 방식을 의미한다. 이 방법은 모델에 입력되는 텍스트에 특정 지시사항이나 조건을 추가하여 모델의 출력을 원하는 방향으로 유도한다.
Fine-Tuning과 Prompt-Tuning은 언어 모델을 최적화하는 방법이다. 즉, 특정 작업에 AI를 적용하기 위해 사용되는 기술이라고 할 수 있다. 이는 모델의 성능과 출력을 개선하고, 원하는 결과를 도출하는 데 사용된다. 하지만 이 두 기술은 서로 다른 기술을 사용하며 모델 훈련에서 각각 다른 역할을 한다.
💡LLM
Fine-Tuning(파인튜닝)과 Prompt-Tuning(프롬프트 튜닝)을 이해하기 위해 먼저 LLM이 무엇인지 알아야 한다.
LLM(Large Language Models)은 대규모 언어 모델을 나타내는데, 이 모델들은 수많은 매개변수와 텍스트 데이터를 기반으로 학습되어 자연어 이해, 생성, 번역 등 다양한 자연어 처리 작업에 사용된다.
이전에는 대규모의 모델을 훈련시키는 데 필요한 데이터와 컴퓨팅 리소스가 제한되어 있었다. 그러나 최근의 발전으로 LLM은 언어 이해와 생성에서 엄청난 진보를 이루어내고 있다. 그러나 모든 작업이나 도메인에 대해 특정한 사전 훈련된 모델이 완벽하게 맞는 것은 아니다. 이때 사용되는 것이 바로 Fine-Tuning이다.
💡Fine-Tuning
Fine-Tuning은 사전 훈련된 언어 모델을 특정 작업에 맞게 조정하는 과정이다. 주어진 작업에 대한 데이터셋을 사용하여 모델의 가중치를 조정하거나 특정 작업에 대한 손실 함수를 최적화하는 방식으로 해당 작업에 더 잘 적응하도록 만든다. 이를 통해 모델은 특정 작업에 더 뛰어난 성능을 발휘할 수 있다.
모델 최적화
Fine-Tuning의 핵심은 풍부한 지식을 가진 모델을 새로운 작업에 맞게 조정하는 것이다. 이를 위해 먼저 목표 작업의 데이터를 사용하여 모델을 재훈련해야 한다. 그러나 전체 모델을 새로 훈련시키는 것이 아니라, 모델의 일부 레이어만을 업데이트한다. 이는 초기에 학습된 일반적인 언어 이해 능력을 유지하면서도 특정 작업에 더 적합하도록 모델을 조정하는 데 도움이 된다.
Model-Tuning
모델 튜닝은 모델의 하이퍼파라미터를 조정하여 최적의 성능을 얻는 과정을 의미한다. 예를 들어, 신경망의 레이어 수, 뉴런의 수, 학습률 등을 조정하여 모델의 성능을 향상하는 작업을 포함한다.
모델 튜닝과 파인 튜닝은 모두 모델의 성능을 향상시키기 위한 과정을 의미하며, 두 용어는 대체로 유사한 맥락에서 사용된다.
지도 학습과 비지도 학습
Fine-Tuning은 지도 학습과 비지도 학습의 형태로 이루어질 수 있다. 지도 학습에서는 작업별 레이블이 지정된 데이터를 사용하여 모델을 조정한다. 반면에, 비지도 학습에서는 레이블이 없는 데이터를 사용하여 모델을 특정 작업에 맞게 조정한다. 지도학습은 목표(target) 또는 결과(outcome) 변수를 예측하는 것을 의미한다. 주로 연속형 또는 범주형 결과변수에 대한 예측을 포함한다. 그리고 비지도학습은 자료를 의미있는 그룹으로 구분하거나 패턴을 찾는 것을 의미한다.
2024.01.05 - [Programming/R] - [R] 데이터마이닝의 이해: BA와 BI, 기계학습, 지도학습과 비지도학습
[R] 데이터마이닝의 이해: BA와 BI, 기계학습, 지도학습과 비지도학습
💡비즈니스 애널리틱스 (Business Analytics, BA) 비즈니스 애널리틱스는 데이터를 분석하는 도구와 기법을 의미하며, 데이터를 분석하여 정량적인 정보를 도출한다. 온라인 분석처리(OLAP), 통계기법,
isaac-christian.tistory.com
지도학습과 비지도 학습에 대해서는 위 글을 참고한다.
Fine-Tuning의 장단점
장점
1. 특화된 작업을 처리한다.
Fine-Tuning은 모델을 특정 작업에 맞게 깊이 최적화할 수 있다. 이는 모델이 해당 작업의 특성을 더 잘 이해하고 반영할 수 있게 돕는다. 예를 들어, 기계 번역 작업에서는 번역에 필요한 문법 규칙이나 어휘 선택과 같은 특수한 요구사항이 있을 수 있다. Fine-Tuning을 통해 모델은 이러한 작업 특성을 더 잘 이해하고, 번역 작업에 보다 적합한 결과를 생성할 수 있게 된다.
2. 정확도가 향상된다.
새로운 데이터에 대한 예측 정확도를 향상할 수 있다. 특히, 전문 용어나 문맥적 뉘앙스가 중요한 작업에서 유용하게 사용될 수 있다. Fine-Tuning을 통해 모델은 해당 작업에 대한 특정한 지식을 습득하고, 이를 기반으로 정확한 예측을 수행할 수 있다. 이는 특히 일반적인 모델이 해당 작업에 대한 지식을 갖고 있지 않을 때 유용하다.
단점
1. 데이터 및 시간이 많이 필요하다.
Fine-Tuning은 많은 양의 레이블링 된 데이터와 학습 시간을 요구한다. 특히, 큰 모델과 복잡한 데이터셋을 다룰 때 많은 자원이 소모된다. 이는 데이터를 수집하고 레이블을 달기 위한 비용과 시간이 추가로 소요되는데, 특히 데이터가 희소하거나 작업이 특정 도메인에 특화되어 있는 경우 더 큰 어려움이 될 수 있다.
2. 과적합의 위험이 있다.
작은 데이터셋으로 Fine-Tuning을 수행할 경우, 모델이 특정 데이터에 지나치게 최적화되어 일반화 능력이 떨어질 수 있다. 특히, 레이블 된 데이터가 부족하거나 작업이 복잡한 경우, 모델은 훈련 데이터의 패턴을 지나치게 외우는 경향이 있어 일반화 능력이 감소할 수 있다. 이는 새로운 데이터나 다른 환경에서 모델의 성능이 저하되는 과적합 문제를 야기할 수 있다.
Fine-Tuning의 과정
1. 기본 모델 선택
파인튜닝을 위해서는 사전에 학습된 기본 모델이 필요하다. 이 모델은 대규모 데이터셋에서 일반적인 언어 이해를 학습한 것이다.
2. 파인튜닝 데이터 수집 및 준비
특정 작업에 관련된 추가 데이터를 수집하고 준비한다. 이 데이터는 모델을 해당 작업에 맞게 조정하는 데 사용된다.
예를 들어, 영화 리뷰 감정 분석을 위한 모델을 만든다면, IMDb나 Rotten Tomatoes 등의 영화 리뷰 데이터를 수집하고 준비한다.
3. 모델 파인튜닝
선택한 기본 모델을 사용하여 수집한 추가 데이터를 통해 모델을 파인튜닝한다. 이 과정에서 모델은 특정 작업에 대한 세부 정보를 학습하게 된다.
파인튜닝 과정에서는 모델의 일부 층을 동결하고 일부 층을 재학습시키는 등의 방법을 사용하여 모델을 해당 작업에 맞게 조정한다.
4. 평가 및 조정
파인튜닝된 모델을 평가하고 필요에 따라 추가적인 조정을 수행한다.
이 단계에서는 주로 검증 데이터셋을 사용하여 모델의 성능을 평가하고 필요한 경우 하이퍼파라미터를 조정하거나 추가적인 학습을 수행하여 모델의 성능을 향상한다.
Fine-Tuning의 활용 예시
Fine-Tuning 기술은 다양한 산업 및 응용 분야에서 사용될 수 있다. 자연어 처리, 이미지 분석, 음성 인식 등 다양한 분야에서 Fine-Tuning을 통해 LLM을 특정 작업에 적용할 수 있다. 더 나아가, Fine-Tuning을 통해 일반적인 사전 훈련된 모델을 사용하여 특정 산업이나 도메인에 맞는 사용자 지정 모델을 만들 수 있다.
의료 이미지 분석
의료 이미지 분석에서는 Fine-Tuning을 사용하여 특정 질병을 감지하는 데 필요한 고도의 정밀도를 갖춘 모델을 개발할 수 있다. 모델을 의료 분야에 맞게 Fine-Tuning 하여 해당 질병의 특징을 정확하게 식별할 수 있다.
감정 분석
감정 분석에서는 특정 도메인이나 언어에 대한 감정을 분석하는 데 Fine-Tuning을 활용할 수 있다. 예를 들어, 특정 브랜드나 제품에 대한 고객 리뷰의 감정을 파악하는 데 Fine-Tuning을 사용하여 모델을 특정 도메인에 맞게 조정할 수 있다.
💡Prompt-Tuning
Prompt-Tuning은 새로운 작업에 적응시키기 위해 가장 적합한 특정 Prompt(입력 텍스트) 매개변수를 찾아 모델을 튜닝하는 과정이다. 이는 LLM이 특정 작업을 수행하도록 유도하는 텍스트나 명령을 의미한다.
Prompt-Tuning은 주어진 작업의 요구사항과 목적에 따라 모델의 입력을 조정하여 성능을 최적화한다. 이를 통해 특정 작업에 대한 성능을 개선하거나 모델이 원하는 방식으로 동작하도록 할 수 있다.
Prompt-Tuning의 장단점
장점
1. 데이터 효율성이 높다.
Prompt-Tuning은 적은 데이터로도 효과적인 결과를 얻을 수 있다. 이미 사전 학습된 모델의 지식을 활용하여 작은 양의 추가 데이터만으로도 모델을 특정 작업에 적용할 수 있다. 이는 데이터를 효율적으로 활용하여 모델을 개선할 수 있는 장점을 제공한다.
2. 빠르게 적용할 수 있다.
전체 모델을 재학습할 필요가 없기 때문에 Prompt-Tuning은 빠르게 적용할 수 있다. 특히 시간에 민감한 프로젝트에 유용하며, 새로운 작업에 대한 모델을 빠르게 구축하고 테스트할 수 있다.
단점
1. 맞춤화가 제한적이다.
Fine-Tuning에 비해 Prompt-Tuning의 맞춤화 정도가 제한적일 수 있다. 특정 작업에 대한 깊은 최적화가 필요한 경우, 이 방법만으로는 한계가 있을 수 있다. 따라서 특정 작업에 더 깊이 맞춤화할 필요가 있는 경우에는 Fine-Tuning을 선택하는 것이 더 적절할 수 있다.
2. 프롬프트 설계가 어렵다.
효과적인 프롬프트를 설계하는 것은 쉽지 않다. 정확하고 효과적인 프롬프트를 개발하기 위해서는 해당 작업의 전문 지식과 언어 모델의 작동 방식을 잘 이해해야 한다. 또한, 프롬프트가 작업을 명확하게 정의하고 모델이 올바른 결과를 생성하도록 유도하는 데 필요한 정보를 제공해야 한다
Prompt-Tuning의 과정
1. 데이터 수집 및 준비
특정 작업에 관련된 데이터를 수집한다. 이 데이터는 모델이 특정 작업을 수행하기 위해 필요한 정보를 포함한다.
예를 들어, 의료 도메인에서의 질문 응답 시스템을 만든다면, 의료 관련 질문과 해당 질문에 대한 정확한 답변으로 구성된 데이터셋을 수집한다.
2. 모델 학습
수집한 데이터를 사용하여 모델을 학습한다.
모델에 입력되는 것은 주로 질문에 해당하는 텍스트인 "프롬프트"이다. 모델은 이 프롬프트를 기반으로 질문에 대한 답변을 생성하는 방식으로 학습된다.
이 과정에서 모델은 주어진 프롬프트와 관련된 문맥을 이해하고, 이를 바탕으로 적절한 답변을 생성하는 방법을 학습한다.
3. 평가 및 튜닝
학습된 모델을 평가하고 필요에 따라 추가적인 튜닝을 수행한다.
평가는 일반적으로 테스트 데이터셋을 사용하여 수행된다. 모델이 주어진 질문에 대해 올바른 답변을 생성하는지 확인하고 성능을 평가한다.
필요한 경우 모델의 하이퍼파라미터를 조정하거나 추가적인 학습을 수행하여 모델의 성능을 향상한다.
Prompt-Tuning의 활용 예시
자연어 처리 작업
자연어 처리 작업에서는 번역, 요약, 질문 응답 등 다양한 작업에 대한 유연한 대응이 필요하다. Prompt-Tuning을 사용하여 모델을 특정 작업에 맞게 조정할 수 있으며, 이는 모델이 다양한 작업에 빠르게 적응할 수 있도록 도와준다.
챗봇 개발
챗봇 개발에서는 다양한 사용자 쿼리에 대응하는 모델이 필요하다. Prompt-Tuning을 사용하여 챗봇 모델을 다양한 대화 시나리오에 빠르게 적응할 수 있도록 조정할 수 있다.
💡Fine-Tuning과 Prompt-Tuning 과정 예시
영화 감정 분석
파인튜닝 과정
- 기본 모델 선택
- BERT라는 사전에 학습된 언어 모델을 선택하였다. BERT는 대규모 데이터셋에서 학습된 일반적인 언어 이해 모델이다.
- 파인튜닝 데이터 수집 및 준비
- IMDb(Internet Movie Database)에서 영화 리뷰 데이터를 수집하고 준비한다. 이 데이터는 영화 리뷰와 해당 리뷰의 감정(긍정 또는 부정)으로 구성되어 있다.
- 모델 파인튜닝
- BERT 모델을 선택하고 수집한 IMDb 영화 리뷰 데이터를 사용하여 모델을 파인튜닝한다.
- 모델 파라미터를 미세 조정하고 영화 리뷰 데이터에 맞게 모델을 학습시킨다. 이 과정에서는 모델의 일부 층을 동결하고 일부 층을 재학습시키는 등의 방법을 사용하여 모델을 해당 작업에 맞게 조정한다.
- 평가 및 조정
- 파인튜닝된 모델을 평가하고 필요에 따라 추가적인 조정을 수행한다.
- 이 과정에서는 주로 검증 데이터셋을 사용하여 모델의 성능을 평가하고, 필요한 경우 하이퍼파라미터를 조정하거나 추가적인 학습을 수행하여 모델의 성능을 향상한다.
프롬프트 튜닝 과정
- 데이터 수집 및 준비
- 영화 리뷰 데이터와 해당 리뷰의 감정(긍정 또는 부정)으로 구성된 데이터셋을 수집하고 준비한다.
- 모델 학습
- 수집한 데이터를 사용하여 모델을 학습한다.
- 모델에 입력되는 것은 주로 질문에 해당하는 텍스트인 "프롬프트"이다. 예를 들어, "이 영화는 긍정적인가요?"와 같은 형식의 프롬프트를 사용하여 모델을 학습시킨다.
- 평가 및 튜닝
- 학습된 모델을 평가하고 필요에 따라 추가적인 튜닝을 수행한다.
- 평가는 일반적으로 테스트 데이터셋을 사용하여 수행된다. 모델이 주어진 프롬프트에 대해 올바른 감정(긍정 또는 부정)을 생성하는지 확인하고 성능을 평가한다.
- 필요한 경우 모델의 하이퍼파라미터를 조정하거나 추가적인 학습을 수행하여 모델의 성능을 향상한다.
텍스트 생성
파인튜닝 과정
- 기본 모델 선택
- GPT-3라는 사전에 학습된 대규모 언어 모델을 선택한다. GPT-3는 다양한 종류의 텍스트 생성 작업에 탁월한 성능을 보인다.
- 파인튜닝 데이터 수집 및 준비
- 글쓰기 연습용 텍스트 데이터를 수집하고 준비한다. 이 데이터는 다양한 주제와 스타일의 텍스트로 구성된다.
- 모델 파인튜닝
- GPT-3 모델을 선택하고 수집한 글쓰기 연습용 텍스트 데이터를 사용하여 모델을 파인튜닝한다.
- 모델 파라미터를 미세 조정하고 텍스트 생성 작업에 맞게 모델을 학습시킨다.
- 평가 및 조정
- 파인튜닝된 모델을 평가하고 필요에 따라 추가적인 조정을 수행한다.
- 이 과정에서는 주로 생성된 텍스트의 품질을 평가하고, 필요한 경우 하이퍼파라미터를 조정하거나 추가적인 학습을 수행하여 모델의 성능을 향상시킨다.
프롬프트 튜닝 과정
- 데이터 수집 및 준비
- 특정 주제에 관련된 텍스트 데이터를 수집하고 준비한다.
- 모델 학습
- 수집한 데이터를 사용하여 모델을 학습한다.
- 모델에 입력되는 것은 주로 질문에 해당하는 텍스트인 "프롬프트"이다. 예를 들어, "프로그래밍에 대해 설명해 주세요."와 같은 형식의 프롬프트를 사용하여 모델을 학습시킨다.
- 평가 및 튜닝
- 학습된 모델을 평가하고 필요에 따라 추가적인 튜닝을 수행한다.
- 평가는 일반적으로 테스트 데이터셋을 사용하여 수행된다. 모델이 주어진 프롬프트에 대해 올바른 텍스트를 생성하는지 확인하고 성능을 평가한다.
- 필요한 경우 모델의 하이퍼파라미터를 조정하거나 추가적인 학습을 수행하여 모델의 성능을 향상한다.
💡Log Parsing
로그 파싱을 위한 Fine-Tuning과 Prompt-Tuning은 로그 데이터를 처리하고 분석하는 데 사용될 수 있는 중요한 기술이다. 로그는 시스템 작동 및 오류 정보를 기록하는 데 사용되며, 이러한 정보를 분석하여 시스템의 동작을 이해하고 문제를 해결하는 데 도움을 준다. 이러한 기술을 Fine-Tuning과 Prompt-Tuning을 통해 로그 데이터에 적용하는 것은 다음과 같은 과정을 포함할 수 있다.
Fine-Tuning for Log Parsing
로그 파싱 작업에 대해 Fine-Tuning을 수행할 때, 먼저 사전 학습된 모델을 가져와서 로그 데이터에 대한 추가 학습을 진행한다. 이를 통해 모델은 로그 메시지의 구조와 패턴을 학습하고, 로그 데이터를 파싱 하는 데 필요한 지식을 습득한다. 예를 들어, 로그 메시지의 유형을 식별하거나 특정 필드를 추출하는 작업을 수행할 수 있다.
Prompt-Tuning for Log Parsing
로그 파싱에 대한 Prompt-Tuning을 수행할 때, 특정 로그 메시지를 처리하기 위한 프롬프트를 설계한다. 이 프롬프트는 모델에게 로그 메시지를 파싱하고 원하는 정보를 추출하도록 지시한다. 예를 들어, "로그 메시지를 파싱 하여 날짜, 시간 및 오류 유형을 추출하라"와 같은 프롬프트를 사용하여 모델을 로그 파싱 작업에 대해 특정하게 지시할 수 있다.
적용 및 성능 평가
Fine-Tuning과 Prompt-Tuning을 통해 로그 파싱에 적용된 모델을 사용하여 실제 로그 데이터를 처리하고 분석한다. 이를 통해 모델이 로그 메시지를 올바르게 파싱하고 필요한 정보를 추출하는 데 얼마나 효과적인지를 평가할 수 있다. 성능 평가는 정확도, 처리 속도 및 리소스 사용량 등을 고려하여 수행될 수 있다.
Fine-Tuning과 Prompt-Tuning의 융합
Fine-Tuning과 Prompt-Tuning 각각의 장점을 결합하여 더욱 강력한 모델을 만들 수 있다. 먼저 Fine-Tuning을 통해 모델을 새로운 작업에 맞게 학습시킨 후, Prompt-Tuning을 사용하여 모델의 출력을 더욱 세밀하게 제어할 수 있다. 이러한 융합은 모델의 예측 성능을 향상하고, 원하는 출력을 보다 정확하게 조절할 수 있는 장점을 제공한다.
참고 자료
파인튜닝(Fine-tuning)이란? – LLM 구축 방법, appen, 2023.12.14.
Prompt engineering vs. fine-tuning: What's the difference?, Stephen J. Bigelow, 2023.08.21.
파인튜닝 VS 프롬프트 튜닝! AI 모델 최적화 방법 비교, Fine tuning, Prompt tuning, Znlsl, 2024.01.14.
프롬프트 튜닝(Prompt Tuning)이해하기! 프롬프트 원리, 장점, 주의점, Znlsl, 2024.01.14.
GPT-3 등장과 그 후: Prompting and Promt Tuning (Prefix-Tuning, P-Tuning), 이지혜, 2023.12.26.
Fine Tuning, Wikipedia, 2024.01.06.
Prompt engineering, Wikipedia, 2024.03.09.
The Art of Prompt Engneering — 1. Prompt Engineering이란 무엇인가?, daewoo kim, 2023.04.26.
An illustration of fine-tuning and prompt tuning for log parsing, Van-Hoang Le, Hongyu Zhang, 2023.02.