
💡RDBMS가 지양하는 것들
- 기본키가 없는 상태의 테이블
- null이 많은 상태의 테이블
- 데이터가 중복되는 상태
- 하나의 속성값이 원자값이 아닌 상태
테이블은 기본키가 있어야 하며, null이 반드시 필요한 경우가 아니라면 사용하지 않는 게 좋다.
그리고 데이터가 중복되지 않도록 해야 한다.
이러한 조건에 해당한다면 공간이 낭비되거나 데이터 조작이 곤란해지는 상황이 생긴다.
테이블을 다시 만들어보면서 문제를 해결해보도록 하자!😁
해결책: 테이블 수정을 통해 고칠 수 있다. 이는 구조적인 문제임을 의미한다.
1. 기본키가 없는 상태의 테이블
CREATE TABLE tblTest
(
name varchar2(30) NOT NULL,
age nnumber(3) NOT NULL,
nick varchar2(30) NOT NULL
);
-- 홍길동, 20, K-히어로
-- 아무개, 22, 맹구
-- 이순신, 20, 바다의왕자
-- 홍길동, 20, K-히어로
-- 홍길동 별명 수정
UPDATE tblTest SET nick = 'K-Hero' WHERE name = '홍길동';
-- 홍길동 탈퇴
DELETE FROM tblTest WHERE name = '홍길동';홍길동의 별명을 수정 또는 홍길동 데이터를 삭제하려고 한다.
그런데 홍길동 데이터가 2개이기 때문에 식별이 불가능하다는 문제가 발생한다.
2. null이 많은 상태의 테이블
CREATE TABLE tblTest
(
name varchar2(30) NOT NULL,
age number(3) NOT NULL,
nick varchar2(30) NOT NULL,
hobby varchar2(100) NULL
);
-- 홍길동, 20, K-히어로, null --취미 없음
-- 아무개, 22, 맹구, 돌모으기
-- 이순신, 24, 바다의왕자, 수영, 활쏘기이순신의 경우 취미가 '수영, 활쏘기'로 2개 이상이다.
값은 쪼개질 수 없어야 하므로 값으로 '수영, 활쏘기'를 그대로 넣어서는 안 된다.
CREATE TABLE tblTest
(
name varchar2(30) NOT NULL,
age number(3) NOT NULL,
nick varchar2(30) NOT NULL,
hobby1 varchar2(100) NULL,
hobby2 varchar2(100) NULL,
hobby3 varchar2(100) NULL,
hobby4 varchar2(100) NULL,
hobby5 varchar2(100) NULL,
);
-- 홍길동, 20, K-히어로, null, null, null, null, null
-- 아무개, 22, 맹구, 돌모으기, 돌부수기, 돌쪼개기, null, null
-- 이순신, 24, 바다의왕자, 수영, 활쏘기, null, null, null
-- 테스트, 25, 테스트, 수영, 독서, 낮잠, 여행, 공부그래서 테이블을 다시 만들어 취미를 5개까지 저장할 수 있게 했다.
그러나 이 경우 null이 여러 번 저장되어 공간이 낭비되므로 잘못 만든 테이블이다.
-- 직원(번호(PK), 직원명, 급여, 거주지, 담당프로젝트)
CREATE TABLE tblStaff
(
seq NUMBER PRIMARY KEY, --직원번호(PK)
name varchar2(30) NOT NULL, --직원명
salary NUMBER NOT NULL, --급여
address varchar2(300) NOT NULL, --거주지
project varchar2(300) --담당프로젝트
);INSERT INTO tblStaff (seq, name, salary, address, project)
VALUES (1, '홍길동', 300, '서울시', '홍콩 수출');
INSERT INTO tblStaff (seq, name, salary, address, project)
VALUES (2, '아무개', 250, '인천시', '땅콩 수출');
INSERT INTO tblStaff (seq, name, salary, address, project)
VALUES (3, '하하하', 350, '의정부시', '매출 분석');직원 정보를 저장하는 테이블을 만들어서 발생하는 문제를 확인해 보도록 하자.
프로젝트 데이터 추가
UPDATE tblStaff SET project = project + ', 고객 관리' WHERE seq = 1; --사용X'홍길동'에게 담당 프로젝트 '고객 관리'를 1건 추가하려고 한다.
그러나 위 코드를 실행할 경우 '홍콩 수출, 고객 관리'로 저장되어 물리적으로 가능하긴 하지만, 나중에 야기하는 문제가 많으므로 절대 사용하지 않는다.
3. 데이터가 중복되는 상태
INSERT INTO tblStaff (seq, name, salary, address, project)
VALUES (4, '홍길동', 300, '서울시', '고객 관리');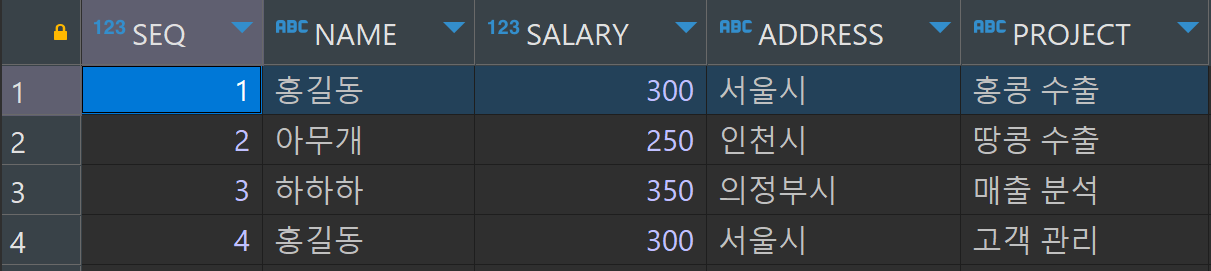
그래서 다른 방안으로 홍길동의 정보를 중복으로 넣어 주었다.
데이터를 확인해 보니 하나의 컬럼 안에 두 개의 데이터가 들어가는 문제는 해결했지만, 같은 사람의 정보가 반복되고 있다.
이 경우 테이블을 잘못 만들었다고 볼 수 있다.
4. 하나의 속성값이 원자값이 아닌 상태
INSERT INTO tblStaff (seq, name, salary, address, project)
VALUES (5, '하하하', 250, '서울시', '게시판 관리, 회원 응대');
INSERT INTO tblStaff (seq, name, salary, address, project)
VALUES (6, '후후후', 250, '서울시', '불량 회원 응대');새로운 담당자 2명을 추가해 주었다.
땅콩 수출 담당자 검색
SELECT * FROM tblStaff WHERE project = '땅콩 수출';
땅콩 수출 데이터를 찾았다.🥜
SELECT * FROM tblStaff WHERE project = '회원 응대'; --출력X
SELECT * FROM tblStaff WHERE project LIKE '%회원 응대%';
회원 응대하는 데이터를 찾았지만 '%'를 사용해서 포함하는 데이터를 찾아야만 조회를 할 수 있다.
게다가 이 경우에는 회원 응대만 찾고 싶은데 찾고 싶지 않았던 다른 사람까지 찾아버린다.
프로젝트 데이터 수정
UPDATE tblStaff SET project = '멤버 조치' WHERE project LIKE '%, 회원 응대%';회원 응대를 찾아서 '게시판 관리, 회원 응대' 데이터를 '멤버 조치'로 수정하면 '게시판 관리'까지 사라져 버린다.
이러한 문제는 원자값을 제대로 유지하지 않아서 발생한다.
DROP TABLE tblStaff;도르마무!🧙 테이블을 재구성하러 왔다!
테이블 재구성
-- 직원(번호(PK), 직원명, 급여, 거주지)
CREATE TABLE tblStaff(
seq NUMBER PRIMARY KEY, --직원번호(PK)
name varchar2(30) NOT NULL, --직원명
salary NUMBER NOT NULL, --급여
address varchar2(300) NOT NULL --거주지
);
-- 프로젝트 정보
CREATE TABLE tblProject(
seq NUMBER PRIMARY KEY, --프로젝트 번호(PK)
project varchar2 (100) NOT NULL, --프로젝트명
staff_seq NUMBER NOT NULL --담당 직원 번호
);프로젝트 정보 테이블을 따로 생성하였다.
어느 한 쪽에서 다른 한 쪽을 짝꿍이라는 걸 증명하기 위한 참조 관계를 만들어야 한다.
보편적으로 기본키를 많이 참조하는 편이다.
담당자 및 프로젝트 데이터 추가
INSERT INTO tblStaff (seq, name, salary, address) VALUES (1, '홍길동', 300, '서울시');
INSERT INTO tblStaff (seq, name, salary, address) VALUES (2, '아무개', 250, '인천시');
INSERT INTO tblStaff (seq, name, salary, address) VALUES (3, '하하하', 250, '부산시');
INSERT INTO tblProject (seq, project, staff_seq) VALUES (1, '홍콩 수출', 1); --홍길동
INSERT INTO tblProject (seq, project, staff_seq) VALUES (2, '땅콩 수출', 2); --아무개
INSERT INTO tblProject (seq, project, staff_seq) VALUES (3, '매출 분석', 3); --하하하
INSERT INTO tblProject (seq, project, staff_seq) VALUES (4, '노조 협상', 1); --홍길동
INSERT INTO tblProject (seq, project, staff_seq) VALUES (5, '땅콩 분양', 2); --아무개
SELECT * FROM tblStaff;
SELECT * FROM tblProject;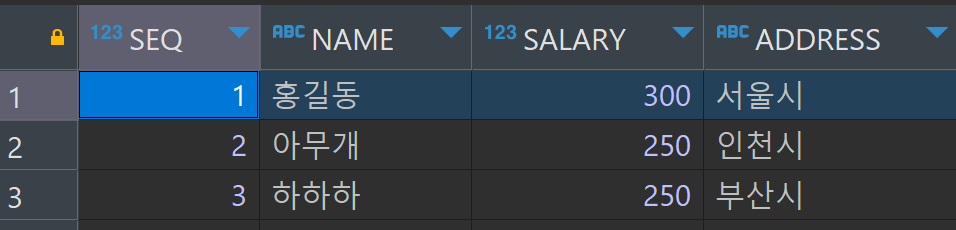
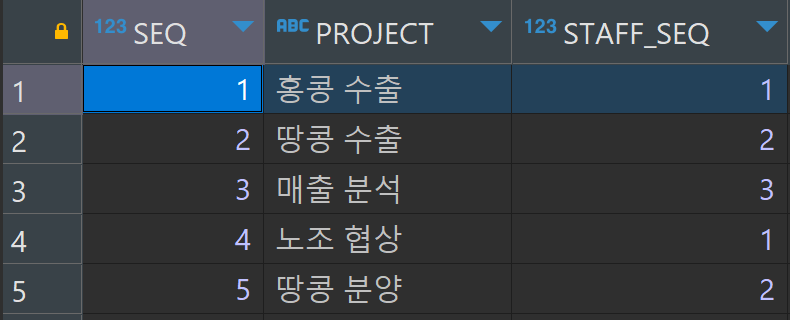
담당자와 프로젝트를 따로 관리하면 데이터가 중복되는 현상이 사라진다.
그리고 프로젝트 하나당 레코드가 하나씩 생성되기 때문에 프로젝트명으로 담당자를 찾는 작업도 문제없이 실행된다.
땅콩 수출 담당자 검색
SELECT staff_seq FROM tblProject WHERE project = '땅콩 수출';
SELECT * FROM tblStaff WHERE seq = 2;
SELECT * FROM tblStaff WHERE seq = (SELECT staff_seq FROM tblProject WHERE project = '땅콩 수출');
서브 쿼리를 이용하여 땅콩 수출 담당자를 검색하였다.
[Oracle] Main Query, Sub Query
💡Main Query Main Query(일반 쿼리)는 하나의 문장 안에 하나의 SELECT(INSERT, UPDATE, DELETE)로 구성 되어 있는 쿼리이다. 💡Sub Query Sub Query(서브 쿼리)는 하나의 문장(SELECT(INSERT, UPDATE, DELETE)) 안에 또 다른
isaac-christian.tistory.com
서브 쿼리에 대해서는 이 글을 참고하도록 하자!
💡문제 발생
신입 사원 입사
1. 신입 사원 추가
INSERT INTO tblStaff (seq, name, salary, address) VALUES (4, '아이작', 250, '성남시');
2. 담당자가 있는 신규 프로젝트 추가
INSERT INTO tblProject (seq, project, staff_seq) VALUES (6, '자재 매입', 4); --아이작
3. 담당자가 없는 신규 프로젝트 추가
INSERT INTO tblProject (seq, project, staff_seq) VALUES (7, '고객 유치', 5); --담당자 없음이때 문제가 하나 발생한다.
담당자 번호만 있고 담당한 사람이 없다. 애초에 A.3 신규 프로젝트 추가를 허용했으면 안 된다.
이 경우 에러가 발생하지 않기 때문에 문제 발생에 유의한다.
이 문제의 해결 방법으로는 Foreign Key를 사용해서 테이블을 다시 만드는 방법이 있다.
-- 직원(번호(PK), 직원명, 급여, 거주지)
CREATE TABLE tblStaff(
seq NUMBER PRIMARY KEY, --직원번호(PK)
name varchar2(30) NOT NULL, --직원명
salary NUMBER NOT NULL, --급여
address varchar2(300) NOT NULL --거주지
);
-- 프로젝트 정보
CREATE TABLE tblProject(
seq NUMBER PRIMARY KEY, --프로젝트 번호(PK)
project varchar2 (100) NOT NULL, --프로젝트명
staff_seq NUMBER NOT NULL REFERENCES tblStaff(seq) --담당 직원 번호
);[Oracle] 제약 사항 (Constraint)
💡제약 사항 제약사항(Constraint)은 해당 컬럼에 들어갈 데이터(값)에 대한 조건이다. 사용자는 컬럼에 엉뚱한 값이 들어가지 않고 올바른 값만 저장될 수 있도록 해야 한다. 만약 숫자형만 들어
isaac-christian.tistory.com
Foreign Key를 어떻게 사용했는지는 위 글을 참고하도록 하자.
ORA-02291: integrity constraint (HR.SYS_C007250) violated - parent key not found이전에는 담당자가 없어도 막무가내로 실행을 해주었는데, Foreign Key 제약을 한 이후부터 에러가 발생한다.
에러 메시지로는 부모키가 없다고 출력된다.
담당자 퇴사
1. '홍길동' 삭제
DELETE FROM tblStaff WHERE seq = 1;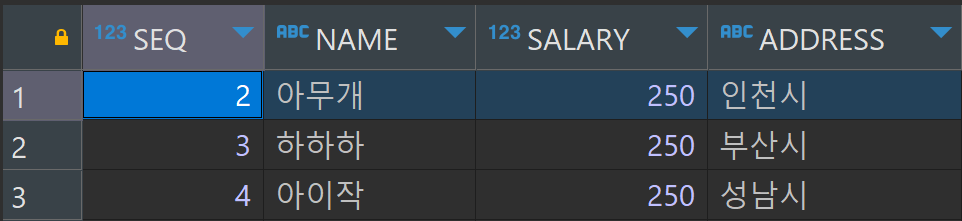
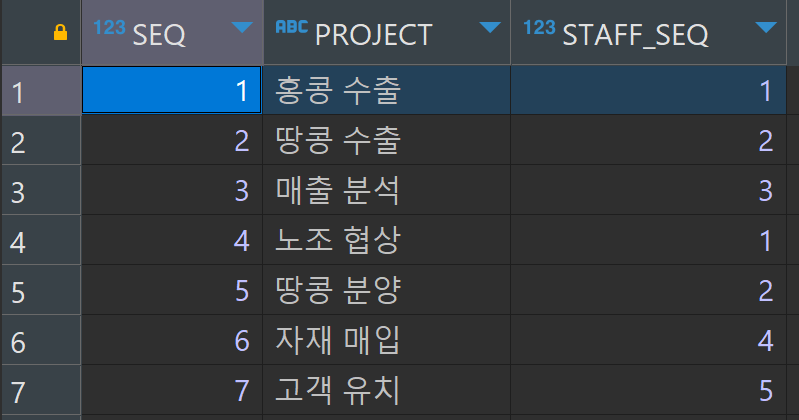
담당자를 삭제하니 프로젝트까지 삭제되어 버렸다.
이 문제를 해결하기 위해 시나리오를 다시 작성한다.
2. '홍길동' 담당 프로젝트 인수 인계(위임)
UPDATE tblProject SET staff_seq = 2 WHERE staff_seq = 1;
3. '홍길동' 삭제
DELETE FROM tblStaff WHERE seq = 1;인수인계를 한 뒤에는 안전하게 담당자 삭제가 된다.

💡RDBMS가 지양하는 것들
- 기본키가 없는 상태의 테이블
- null이 많은 상태의 테이블
- 데이터가 중복되는 상태
- 하나의 속성값이 원자값이 아닌 상태
테이블은 기본키가 있어야 하며, null이 반드시 필요한 경우가 아니라면 사용하지 않는 게 좋다.
그리고 데이터가 중복되지 않도록 해야 한다.
이러한 조건에 해당한다면 공간이 낭비되거나 데이터 조작이 곤란해지는 상황이 생긴다.
테이블을 다시 만들어보면서 문제를 해결해보도록 하자!😁
해결책: 테이블 수정을 통해 고칠 수 있다. 이는 구조적인 문제임을 의미한다.
1. 기본키가 없는 상태의 테이블
CREATE TABLE tblTest
(
name varchar2(30) NOT NULL,
age nnumber(3) NOT NULL,
nick varchar2(30) NOT NULL
);
-- 홍길동, 20, K-히어로
-- 아무개, 22, 맹구
-- 이순신, 20, 바다의왕자
-- 홍길동, 20, K-히어로
-- 홍길동 별명 수정
UPDATE tblTest SET nick = 'K-Hero' WHERE name = '홍길동';
-- 홍길동 탈퇴
DELETE FROM tblTest WHERE name = '홍길동';홍길동의 별명을 수정 또는 홍길동 데이터를 삭제하려고 한다.
그런데 홍길동 데이터가 2개이기 때문에 식별이 불가능하다는 문제가 발생한다.
2. null이 많은 상태의 테이블
CREATE TABLE tblTest
(
name varchar2(30) NOT NULL,
age number(3) NOT NULL,
nick varchar2(30) NOT NULL,
hobby varchar2(100) NULL
);
-- 홍길동, 20, K-히어로, null --취미 없음
-- 아무개, 22, 맹구, 돌모으기
-- 이순신, 24, 바다의왕자, 수영, 활쏘기이순신의 경우 취미가 '수영, 활쏘기'로 2개 이상이다.
값은 쪼개질 수 없어야 하므로 값으로 '수영, 활쏘기'를 그대로 넣어서는 안 된다.
CREATE TABLE tblTest
(
name varchar2(30) NOT NULL,
age number(3) NOT NULL,
nick varchar2(30) NOT NULL,
hobby1 varchar2(100) NULL,
hobby2 varchar2(100) NULL,
hobby3 varchar2(100) NULL,
hobby4 varchar2(100) NULL,
hobby5 varchar2(100) NULL,
);
-- 홍길동, 20, K-히어로, null, null, null, null, null
-- 아무개, 22, 맹구, 돌모으기, 돌부수기, 돌쪼개기, null, null
-- 이순신, 24, 바다의왕자, 수영, 활쏘기, null, null, null
-- 테스트, 25, 테스트, 수영, 독서, 낮잠, 여행, 공부그래서 테이블을 다시 만들어 취미를 5개까지 저장할 수 있게 했다.
그러나 이 경우 null이 여러 번 저장되어 공간이 낭비되므로 잘못 만든 테이블이다.
-- 직원(번호(PK), 직원명, 급여, 거주지, 담당프로젝트)
CREATE TABLE tblStaff
(
seq NUMBER PRIMARY KEY, --직원번호(PK)
name varchar2(30) NOT NULL, --직원명
salary NUMBER NOT NULL, --급여
address varchar2(300) NOT NULL, --거주지
project varchar2(300) --담당프로젝트
);INSERT INTO tblStaff (seq, name, salary, address, project)
VALUES (1, '홍길동', 300, '서울시', '홍콩 수출');
INSERT INTO tblStaff (seq, name, salary, address, project)
VALUES (2, '아무개', 250, '인천시', '땅콩 수출');
INSERT INTO tblStaff (seq, name, salary, address, project)
VALUES (3, '하하하', 350, '의정부시', '매출 분석');직원 정보를 저장하는 테이블을 만들어서 발생하는 문제를 확인해 보도록 하자.
프로젝트 데이터 추가
UPDATE tblStaff SET project = project + ', 고객 관리' WHERE seq = 1; --사용X'홍길동'에게 담당 프로젝트 '고객 관리'를 1건 추가하려고 한다.
그러나 위 코드를 실행할 경우 '홍콩 수출, 고객 관리'로 저장되어 물리적으로 가능하긴 하지만, 나중에 야기하는 문제가 많으므로 절대 사용하지 않는다.
3. 데이터가 중복되는 상태
INSERT INTO tblStaff (seq, name, salary, address, project)
VALUES (4, '홍길동', 300, '서울시', '고객 관리');그래서 다른 방안으로 홍길동의 정보를 중복으로 넣어 주었다.
데이터를 확인해 보니 하나의 컬럼 안에 두 개의 데이터가 들어가는 문제는 해결했지만, 같은 사람의 정보가 반복되고 있다.
이 경우 테이블을 잘못 만들었다고 볼 수 있다.
4. 하나의 속성값이 원자값이 아닌 상태
INSERT INTO tblStaff (seq, name, salary, address, project)
VALUES (5, '하하하', 250, '서울시', '게시판 관리, 회원 응대');
INSERT INTO tblStaff (seq, name, salary, address, project)
VALUES (6, '후후후', 250, '서울시', '불량 회원 응대');새로운 담당자 2명을 추가해 주었다.
땅콩 수출 담당자 검색
SELECT * FROM tblStaff WHERE project = '땅콩 수출';땅콩 수출 데이터를 찾았다.🥜
SELECT * FROM tblStaff WHERE project = '회원 응대'; --출력X
SELECT * FROM tblStaff WHERE project LIKE '%회원 응대%';회원 응대하는 데이터를 찾았지만 '%'를 사용해서 포함하는 데이터를 찾아야만 조회를 할 수 있다.
게다가 이 경우에는 회원 응대만 찾고 싶은데 찾고 싶지 않았던 다른 사람까지 찾아버린다.
프로젝트 데이터 수정
UPDATE tblStaff SET project = '멤버 조치' WHERE project LIKE '%, 회원 응대%';회원 응대를 찾아서 '게시판 관리, 회원 응대' 데이터를 '멤버 조치'로 수정하면 '게시판 관리'까지 사라져 버린다.
이러한 문제는 원자값을 제대로 유지하지 않아서 발생한다.
DROP TABLE tblStaff;도르마무!🧙 테이블을 재구성하러 왔다!
테이블 재구성
-- 직원(번호(PK), 직원명, 급여, 거주지)
CREATE TABLE tblStaff(
seq NUMBER PRIMARY KEY, --직원번호(PK)
name varchar2(30) NOT NULL, --직원명
salary NUMBER NOT NULL, --급여
address varchar2(300) NOT NULL --거주지
);
-- 프로젝트 정보
CREATE TABLE tblProject(
seq NUMBER PRIMARY KEY, --프로젝트 번호(PK)
project varchar2 (100) NOT NULL, --프로젝트명
staff_seq NUMBER NOT NULL --담당 직원 번호
);프로젝트 정보 테이블을 따로 생성하였다.
어느 한 쪽에서 다른 한 쪽을 짝꿍이라는 걸 증명하기 위한 참조 관계를 만들어야 한다.
보편적으로 기본키를 많이 참조하는 편이다.
담당자 및 프로젝트 데이터 추가
INSERT INTO tblStaff (seq, name, salary, address) VALUES (1, '홍길동', 300, '서울시');
INSERT INTO tblStaff (seq, name, salary, address) VALUES (2, '아무개', 250, '인천시');
INSERT INTO tblStaff (seq, name, salary, address) VALUES (3, '하하하', 250, '부산시');
INSERT INTO tblProject (seq, project, staff_seq) VALUES (1, '홍콩 수출', 1); --홍길동
INSERT INTO tblProject (seq, project, staff_seq) VALUES (2, '땅콩 수출', 2); --아무개
INSERT INTO tblProject (seq, project, staff_seq) VALUES (3, '매출 분석', 3); --하하하
INSERT INTO tblProject (seq, project, staff_seq) VALUES (4, '노조 협상', 1); --홍길동
INSERT INTO tblProject (seq, project, staff_seq) VALUES (5, '땅콩 분양', 2); --아무개
SELECT * FROM tblStaff;
SELECT * FROM tblProject;담당자와 프로젝트를 따로 관리하면 데이터가 중복되는 현상이 사라진다.
그리고 프로젝트 하나당 레코드가 하나씩 생성되기 때문에 프로젝트명으로 담당자를 찾는 작업도 문제없이 실행된다.
땅콩 수출 담당자 검색
SELECT staff_seq FROM tblProject WHERE project = '땅콩 수출';
SELECT * FROM tblStaff WHERE seq = 2;
SELECT * FROM tblStaff WHERE seq = (SELECT staff_seq FROM tblProject WHERE project = '땅콩 수출');서브 쿼리를 이용하여 땅콩 수출 담당자를 검색하였다.
[Oracle] Main Query, Sub Query
💡Main Query Main Query(일반 쿼리)는 하나의 문장 안에 하나의 SELECT(INSERT, UPDATE, DELETE)로 구성 되어 있는 쿼리이다. 💡Sub Query Sub Query(서브 쿼리)는 하나의 문장(SELECT(INSERT, UPDATE, DELETE)) 안에 또 다른
isaac-christian.tistory.com
서브 쿼리에 대해서는 이 글을 참고하도록 하자!
💡문제 발생
신입 사원 입사
1. 신입 사원 추가
INSERT INTO tblStaff (seq, name, salary, address) VALUES (4, '아이작', 250, '성남시');
2. 담당자가 있는 신규 프로젝트 추가
INSERT INTO tblProject (seq, project, staff_seq) VALUES (6, '자재 매입', 4); --아이작
3. 담당자가 없는 신규 프로젝트 추가
INSERT INTO tblProject (seq, project, staff_seq) VALUES (7, '고객 유치', 5); --담당자 없음이때 문제가 하나 발생한다.
담당자 번호만 있고 담당한 사람이 없다. 애초에 A.3 신규 프로젝트 추가를 허용했으면 안 된다.
이 경우 에러가 발생하지 않기 때문에 문제 발생에 유의한다.
이 문제의 해결 방법으로는 Foreign Key를 사용해서 테이블을 다시 만드는 방법이 있다.
-- 직원(번호(PK), 직원명, 급여, 거주지)
CREATE TABLE tblStaff(
seq NUMBER PRIMARY KEY, --직원번호(PK)
name varchar2(30) NOT NULL, --직원명
salary NUMBER NOT NULL, --급여
address varchar2(300) NOT NULL --거주지
);
-- 프로젝트 정보
CREATE TABLE tblProject(
seq NUMBER PRIMARY KEY, --프로젝트 번호(PK)
project varchar2 (100) NOT NULL, --프로젝트명
staff_seq NUMBER NOT NULL REFERENCES tblStaff(seq) --담당 직원 번호
);[Oracle] 제약 사항 (Constraint)
💡제약 사항 제약사항(Constraint)은 해당 컬럼에 들어갈 데이터(값)에 대한 조건이다. 사용자는 컬럼에 엉뚱한 값이 들어가지 않고 올바른 값만 저장될 수 있도록 해야 한다. 만약 숫자형만 들어
isaac-christian.tistory.com
Foreign Key를 어떻게 사용했는지는 위 글을 참고하도록 하자.
ORA-02291: integrity constraint (HR.SYS_C007250) violated - parent key not found이전에는 담당자가 없어도 막무가내로 실행을 해주었는데, Foreign Key 제약을 한 이후부터 에러가 발생한다.
에러 메시지로는 부모키가 없다고 출력된다.
담당자 퇴사
1. '홍길동' 삭제
DELETE FROM tblStaff WHERE seq = 1;담당자를 삭제하니 프로젝트까지 삭제되어 버렸다.
이 문제를 해결하기 위해 시나리오를 다시 작성한다.
2. '홍길동' 담당 프로젝트 인수 인계(위임)
UPDATE tblProject SET staff_seq = 2 WHERE staff_seq = 1;
3. '홍길동' 삭제
DELETE FROM tblStaff WHERE seq = 1;인수인계를 한 뒤에는 안전하게 담당자 삭제가 된다.