
💡GROUP BY절
[WITH <Sub Query>]
SELECT column_list
FROM table_name
[WHERE search_condition]
[GROUP BY group_by_expression]
[HAVING search_condition]
[ORDER BY order_expresstion [ASC|DESC]]- SELECT 컬럼리스트: 4. 컬럼 지정 (보고 싶은 컬럼만 가져오기) > Projection
- FROM 테이블: 1. 테이블 지정
- WHERE 조건: 2. 조건 지정 (보고 싶은 행만 가져오기) > Selection
- group by 기준: 3. (레코드끼리) 그룹을 나눈다.
- ORDER BY 정렬기준: 5. 순서대로 정렬
언제 GROUP BY를 사용할까?
SELECT * FROM tblInsa;
SELECT round(avg(basicpay)) FROM tblInsa; --1556527원 (전체 60명)
SELECT DISTINCT buseo FROM tblInsa; --7개 부서
SELECT round(avg(basicpay)) FROM tblInsa WHERE buseo = '총무부'; --1714857
SELECT round(avg(basicpay)) FROM tblInsa WHERE buseo = '개발부'; --1387857
SELECT round(avg(basicpay)) FROM tblInsa WHERE buseo = '영업부'; --1601513
SELECT round(avg(basicpay)) FROM tblInsa WHERE buseo = '기획부'; --1855714
SELECT round(avg(basicpay)) FROM tblInsa WHERE buseo = '인사부'; --1533000
SELECT round(avg(basicpay)) FROM tblInsa WHERE buseo = '자재부'; --1416733
SELECT round(avg(basicpay)) FROM tblInsa WHERE buseo = '홍보부'; --1451833부서별 평균 급여를 구하고자 할 때, WHERE 절을 이용해 하나씩 구할 수 있다.
이렇게 그룹별 통계값을 구할 때, GROUP BY를 사용한다. GROUP BY의 목적은 그룹별 통계값을 구하는 것이다.
그리고 통계값을 구한다는 얘기는 집계 함수(count, sum, avg, max 등등)를 사용한다는 말이다.
GROUP BY절의 사용
SELECT
*
FROM 테이블
GROUP BY 그룹짓기위한 기준컬럼;그룹을 짓기 위해서는 기준이 필요하다. GROUP BY는 컬럼을 기준으로 그룹을 짓는다.
이 테이블에서 기준은 성별이 될 수도, 지역이 될 수도 있다.
부서별 급여 통계
SELECT
count(*) AS "부서별 인원수",
round(avg(basicpay)) AS "부서별 평균급여",
sum(basicpay) AS "부서별 지급액",
max(basicpay) AS "부서내 최고 급여",
min(basicpay) AS "부서내 최저 급여",
buseo
FROM tblInsa
GROUP BY buseo;
부서를 기준으로 급여의 통계를 계산하였다.
ORA-00979: not a GROUP BY expression
--ORA-00979: not a GROUP BY expression
SELECT
*
FROM TBLINSA
GROUP BY buseo;
--ORA-00979: not a GROUP BY expression
SELECT
count(*), name
FROM TBLINSA
GROUP BY buseo;GROUP BY의 목적이 집계함수를 내는 거라고 했다.
count(*)와 name의 성질이 다르기 때문에 name을 사용할 수 없다. GROUP BY가 있는 SELECT절은 일반 컬럼을 명시할 수 없기 때문이다.
GROUP BY가 있는 SELECT절은 집합하고 관련된 행동은 할 수 있어도, 개인과 관련된 행동은 할 수 없다는 점을 명심하자.
SELECT
count(*), buseo
FROM TBLINSA
GROUP BY buseo;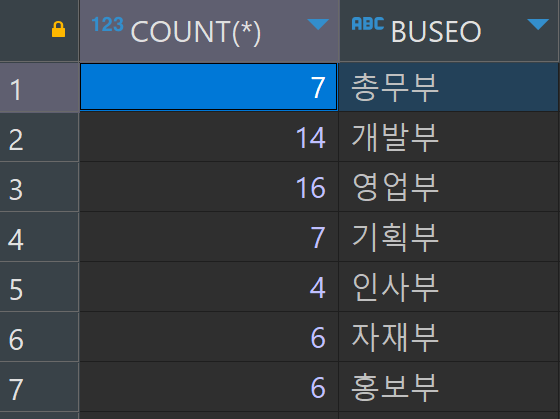
예외적으로 그룹으로 쓴 컬럼은 사용할 수 있다!😊
다중 그룹
-- 일차 그룹
SELECT
buseo,
count(*)
FROM TBLINSA
GROUP BY buseo;
-- 다중 그룹
SELECT
buseo,
jikwi,
count(*)
FROM TBLINSA
GROUP BY buseo, jikwi;다중 그룹의 경우 GROUP BY가 buseo, jikwi 두 개인 것을 확인할 수 있다.
급여별 그룹
SELECT
(floor(basicpay / 1000000) + 1) * 100 || '만원 이하' AS money,
count(*)
FROM TBLINSA
GROUP BY floor(basicpay / 1000000);
완료한 일정과 완료하지 않은 일정
SELECT
CASE
WHEN completedate IS NOT NULL THEN 1
ELSE 2
END,
count(*)
FROM tbltodo
GROUP BY CASE
WHEN completedate IS NOT NULL THEN 1
ELSE 2
END;
rollup()
rollup 함수는 그룹별 중간 통계를 내는 역할을 한다.
rollup 함수는 group by의 집계 결과를 더 자세하게 반환해준다.
rollup 함수의 사용
SELECT
buseo,
count(*) AS 인원수,
sum(basicpay),
round(avg(basicpay)),
max(basicpay),
min(basicpay)
FROM TBLINSA
GROUP BY ROLLUP(buseo);
rollup 함수를 실행하자 하단부에 레코드 하나가 더 생겼다.
rollup 함수가 어디에 쓰였냐에 따라서 다른 결과를 낸다. sum은 sum값의 합을 구하고, round는 round값의 평균을 구하고, max는 max값 중 가장 큰 값을 구하고, min은 min값 중 가장 작은 값을 구한다.
SELECT
buseo,
count(*) AS 인원수,
sum(basicpay),
round(avg(basicpay)),
max(basicpay),
min(basicpay)
FROM TBLINSA
GROUP BY ROLLUP(buseo, jikwi);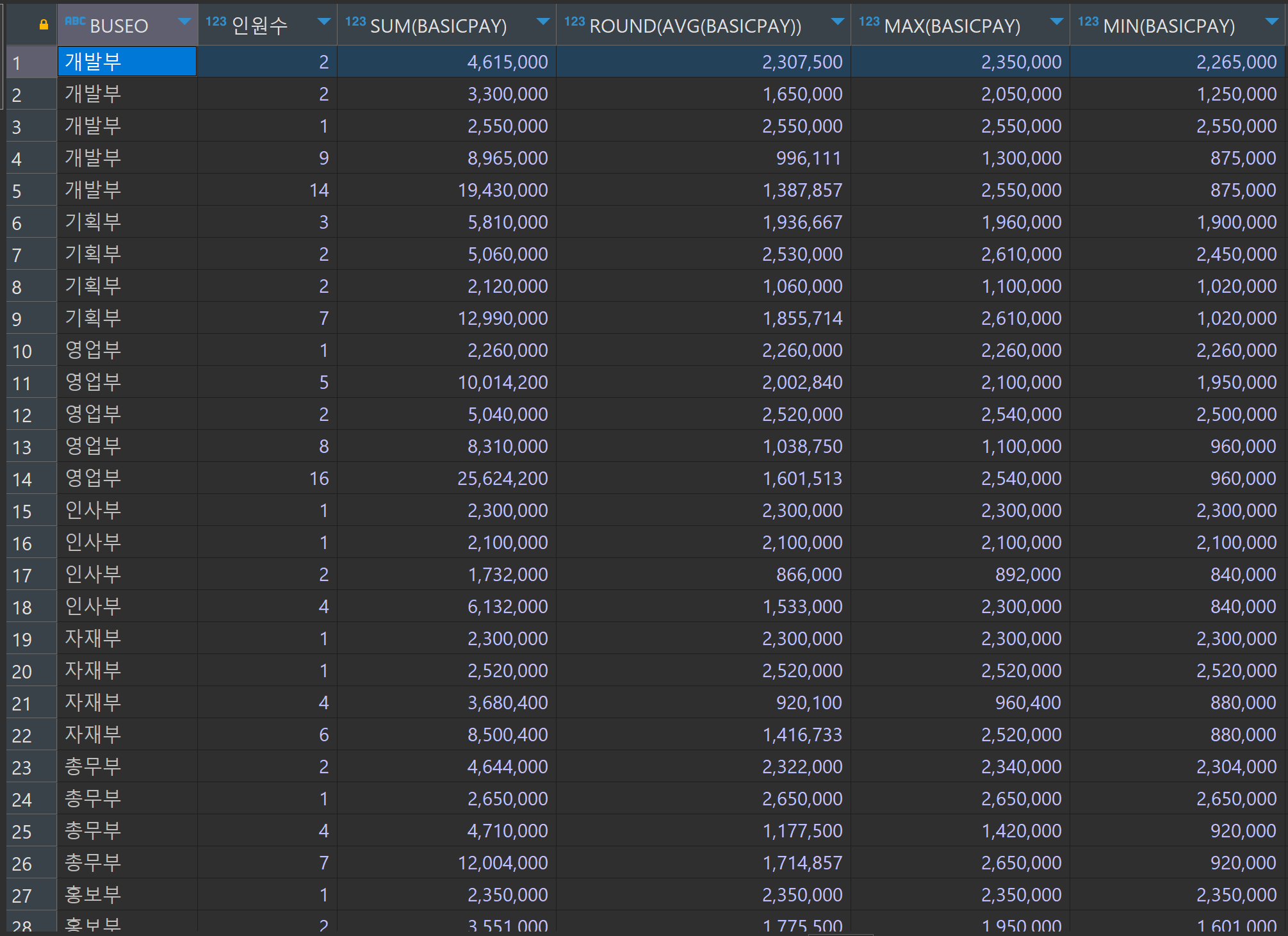
차원이 들어갈수록 중간에 계속 rollup 함수가 결산을 한다.
개발부, 기획부, 영업부.. 등의 부서마다 가장 하단에 중간 통계를 냈다.
cube()
- rollup > 다중 그룹 컬럼 > 수직 관계(전체 인원 총계, 부서별 총계)
- cube > 다중 그룹 컬럼 > 수평 관계(전체 인원 총계, 부서별 총계, 직위별 총계)
cube 함수는 rollup 함수와 반대로 상단부에 중간 통계를 출력한다.
cube 함수의 사용
SELECT
buseo,
count(*) AS 인원수,
sum(basicpay),
round(avg(basicpay)),
max(basicpay),
min(basicpay)
FROM TBLINSA
GROUP BY CUBE(buseo);
SELECT
buseo,
count(*) AS 인원수,
sum(basicpay),
round(avg(basicpay)),
max(basicpay),
min(basicpay)
FROM TBLINSA
GROUP BY CUBE(buseo, jikwi);
rollup 함수와 cube 함수의 차이는 2차, 3차 다차로 갈 때 생긴다.
cube 함수는 rollup 함수와 다르게 상단부에 그룹별 중간 통계를 낼 뿐만 아니라, 중간 통계를 낸 것들의 통계를 추가로 제공한다.
💡HAVING절
[WITH <Sub Query>]
SELECT column_list
FROM table_name
[WHERE search_condition]
[GROUP BY group_by_expression]
[HAVING search_condition]
[ORDER BY order_expresstion [ASC|DESC]]- SELECT 컬럼리스트: 5. 컬럼 지정
- FROM 테이블: 1. 테이블 지정
- WHERE 조건: 2. 조건 지정 (레코드에 대한 조건 - 개인 조건 > 컬럼)
- group by 기준: 3. (레코드끼리) 그룹을 나눈다.
- having 조건: 4. 조건 지정 (그룹에 대한 조건 - 그룹 조건 > 집계 함수)
- ORDER BY 정렬기준: 6. 순서대로 정렬
HAVING절의 사용
WHERE절
--WHERE절
SELECT --4. 각 그룹별로 집계 함수를 실행한다.
buseo,
round(avg(basicpay))
FROM TBLINSA --1. 60명의 데이터를 가져온다.
WHERE basicpay >= 1500000 --2. 60명을 대상으로 조건을 검사한다.
GROUP BY buseo; --3. 2번을 통과한 사람들(27명)을 대상으로 그룹을 짓는다.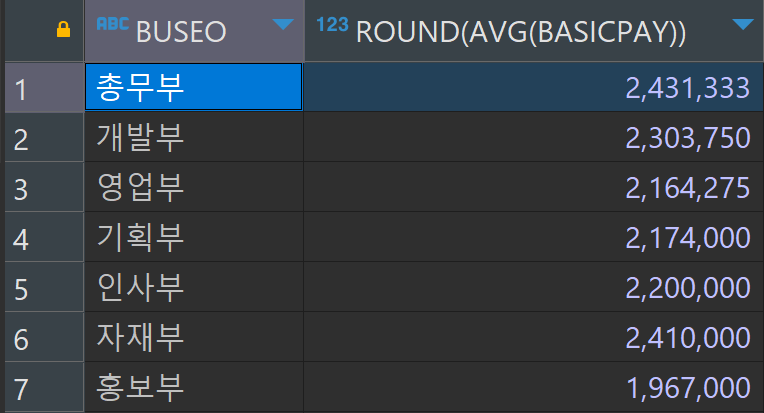
HAVING절
--HAVING절
SELECT --4. 각 그룹별로 집계 함수를 실행한다.
buseo,
round(avg(basicpay))
FROM TBLINSA --1. 60명의 데이터를 가져온다.
GROUP BY buseo --2. 60명을 대상으로 그룹을 짓는다.
HAVING avg(basicpay) >= 1500000; --3. 그룹별로 조건을 검사한다.
HAVING은 조건절로 GROUP BY절 없이는 사용할 수 없다. HAVING절은 반드시 GROUP BY와 함께 사용한다.
GROUP BY로 그룹으로 지어진 순간부터 집계 함수로 호출하는 것 밖에 할 수 없게 된다.
WHERE절은 레코드에 대한 조건이고, HAVING절은 그룹에 대한 조건이다.
WHERE절이 💃개인에 대한 오디션이라고 하면, HAVING절은 👯♀팀에 대한 오디션이라고 생각하며 된다.
ORA-00979: not a GROUP BY expressio그룹의 데이터가 아니라 개인 데이터를 HAVING절에서 사용할 경우 에러가 발생한다.
예로 들어 HAVING basicpay >= 1500000; 로 avg 함수를 사용하지 않은 경우 개인의 데이터로 인식하여 에러를 출력한다.
인원수가 10명 이상인 부서
SELECT
buseo AS 부서,
count(*) AS 인원수
FROM tblInsa
GROUP BY buseo
HAVING count(*) >= 10;
과장과 부장의 인원합이 3명 이상인 부서
SELECT
buseo AS 부서,
count(*) AS 인원수
FROM tblInsa
WHERE jikwi IN ('과장', '부장')
GROUP BY buseo
HAVING count(*) >= 3;
시도별 인원수 (서울, 인천, 부산..)
SELECT * FROM TBLADDRESSBOOK;
SELECT substr(address, 1, instr(address, ' ') - 1) FROM TBLADDRESSBOOK;
주소의 첫 단어만을 가져오고 싶다고 할 때, instr 함수를 이용해 주소의 첫 번째 ' '를 찾는다.
substr(컬럼, 시작위치, 문자개수) 함수를 이용해 첫 단어를 가져온다. 이때 문자개수 - 1을 하지 않으면 뒤의 공백까지 가져온다.
SELECT
substr(address, 1, instr(address, ' ') - 1) AS 시도,
count(*) AS 인원수
FROM TBLADDRESSBOOK
GROUP BY substr(address, 1, instr(address, ' ') - 1)
ORDER BY 인원수 DESC;
Alias 처리를 하고 인원수로 내림차순하여 출력했다.
부서별 / 직급별 인원수
SELECT
buseo AS 부서명,
count(*) AS 총인원,
count(decode(jikwi, '부장', 1)) AS 부장,
count(decode(jikwi, '과장', 1)) AS 과장,
count(decode(jikwi, '대리', 1)) AS 대리,
count(decode(jikwi, '사원', 1)) AS 사원
FROM TBLINSA
GROUP BY buseo;
