
💡ORDER BY절
[WITH <Sub Query>]
SELECT column_list
FROM table_name
[WHERE search_condition]
[GROUP BY group_by_expression]
[HAVING search_condition]
[ORDER BY order_expression [ASC|DESC]]- SELECT 컬럼리스트: 3. 컬럼 지정 (보고 싶은 컬럼만 가져오기) > Projection
- FROM 테이블: 1. 테이블 지정
- WHERE 조건: 2. 조건 지정 (보고 싶은 행만 가져오기) > Selection
- ORDER BY 정렬기준: 4. 순서대로 정렬
ORDER BY절의 사용
order by 컬럼명 [ASC|DESC]order by절은 위와 같은 형태로 작성하며, 생략할 경우 ASC로 적용된다.
order by절은 원본 테이블을 정렬하는 게 아니라 결과 테이블을 정렬한다. 원본 테이블은 오라클에 저장된 데이터로, 오라클이 스스로 관리하므로 개발자가 접근할 수 없다.
1차/2차/3차 정렬
1차 정렬
SELECT * FROM TBLINSA ORDER BY BUSEO ASC
1차 정렬은 정렬 기준이 1개인 경우를 의미한다.
2차 정렬
SELECT * FROM TBLINSA ORDER BY BUSEO ASC, JIKWI DESC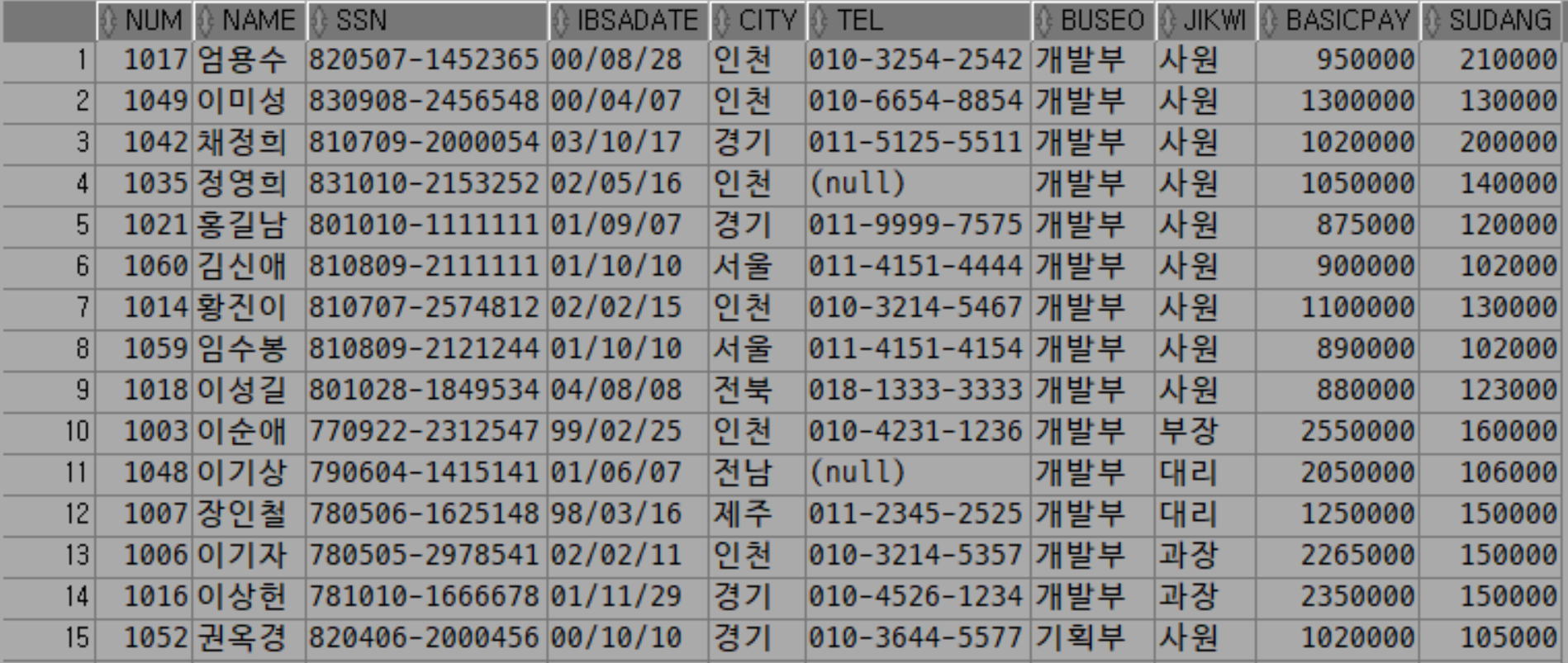
2차 정렬은 정렬을 1차 정렬 이후에 판가름이 나지 않는 경우 제시하는 정렬이다.
3차 정렬
SELECT * FROM TBLINSA ORDER BY BUSEO ASC, JIKWI DESC, BASICPAY DESC;
컬럼 리스트 순서로 정렬
SELECT name, buseo, jikwi FROM TBLINSA ORDER BY 1;
ORDER BY에 숫자가 들어갔다. 이는 컬럼 리스트의 순서로, 1일 경우 첫 번째에 있는 컬럼으로 정렬, 2일 경우 두 번째에 있는 컬럼으로 정렬하라는 것을 의미한다.
그러나 이 문법은 가독성도 떨어지지만, 유지보수에 매우 취약하므로 사용을 지양해야 한다.
가공된 값의 정렬
SELECT * FROM TBLINSA ORDER BY (BASICPAY + SUDANG) DESC;
가공된 값의 급여(basicpay + sudang)로 가장 많이 받는 직원 순으로 정렬할 수 있다.
CASE END 적용
SELECT
NAME, JIKWI
FROM TBLINSA
ORDER BY JIKWI DESC;직위 순으로 정렬: 부장 > 과장 > 대리 > 사원 순으로 정렬하려고 할 때, 직위는 우리가 정한 기준이므로 SQL에서는 문자값으로 정렬을 한다.
우리가 원하는 정렬 방식으로 정렬하기 위해서는 CASE END를 사용해야 한다.
직위순으로 정렬
SELECT
NAME, JIKWI,
CASE
WHEN JIKWI = '부장' THEN 4
WHEN JIKWI = '과장' THEN 3
WHEN JIKWI = '대리' THEN 2
WHEN JIKWI = '사원' THEN 1
END AS JIKWISEQ
FROM TBLINSA
ORDER BY JIKWISEQ DESC;
JIKWISEQ를 이용하여 내림차순 정렬을 하였다.
그런데 JIKWISEQ를 이용하지 않고도 정렬하여 출력하는 방법도 있다.
ORDER BY절에 CASE END 삽입
SELECT
NAME, JIKWI
FROM TBLINSA
ORDER BY CASE
WHEN JIKWI = '부장' THEN 4
WHEN JIKWI = '과장' THEN 3
WHEN JIKWI = '대리' THEN 2
WHEN JIKWI = '사원' THEN 1
END DESC;
이처럼 ORDER BY절에 CASE END를 넣으면 바로 정렬이 된다.
성별순으로 정렬
SELECT
NAME, SSN
FROM TBLINSA
ORDER BY CASE
WHEN SSN LIKE '%-1%' THEN 1
WHEN SSN LIKE '%-2%' THEN 2
END ASC;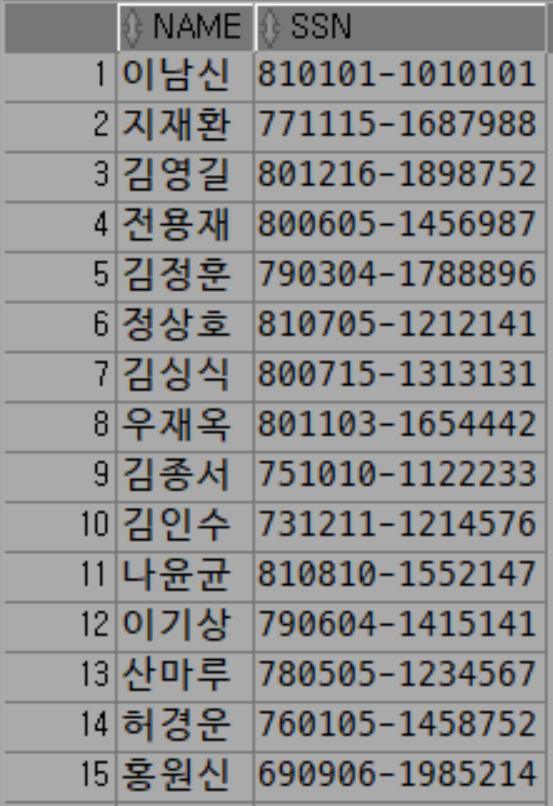
남자 직원만 가져오기
SELECT * FROM TBLINSA
WHERE SSN LIKE '%-1%';
CASE END는 컬럼이 들어가는 곳에는 항상 들어갈 수 있다.
