
💡명령어 실행 처리 과정
클라이언트 컴퓨터에는 SQL Developer, DBeaver 같은 프로그램이 있고, 오라클 서버 컴퓨터에는 실제 프로세스가 동작하는 메모리와 오라클이 저장되어 있는 저장장치가 있다.
ANSI-SQL과 익명 프로시저는 동작 방식이 같고, 실명 프로시저는 동작 방식이 다르다.
1. ANSI-SQL
2. 익명 프로시저
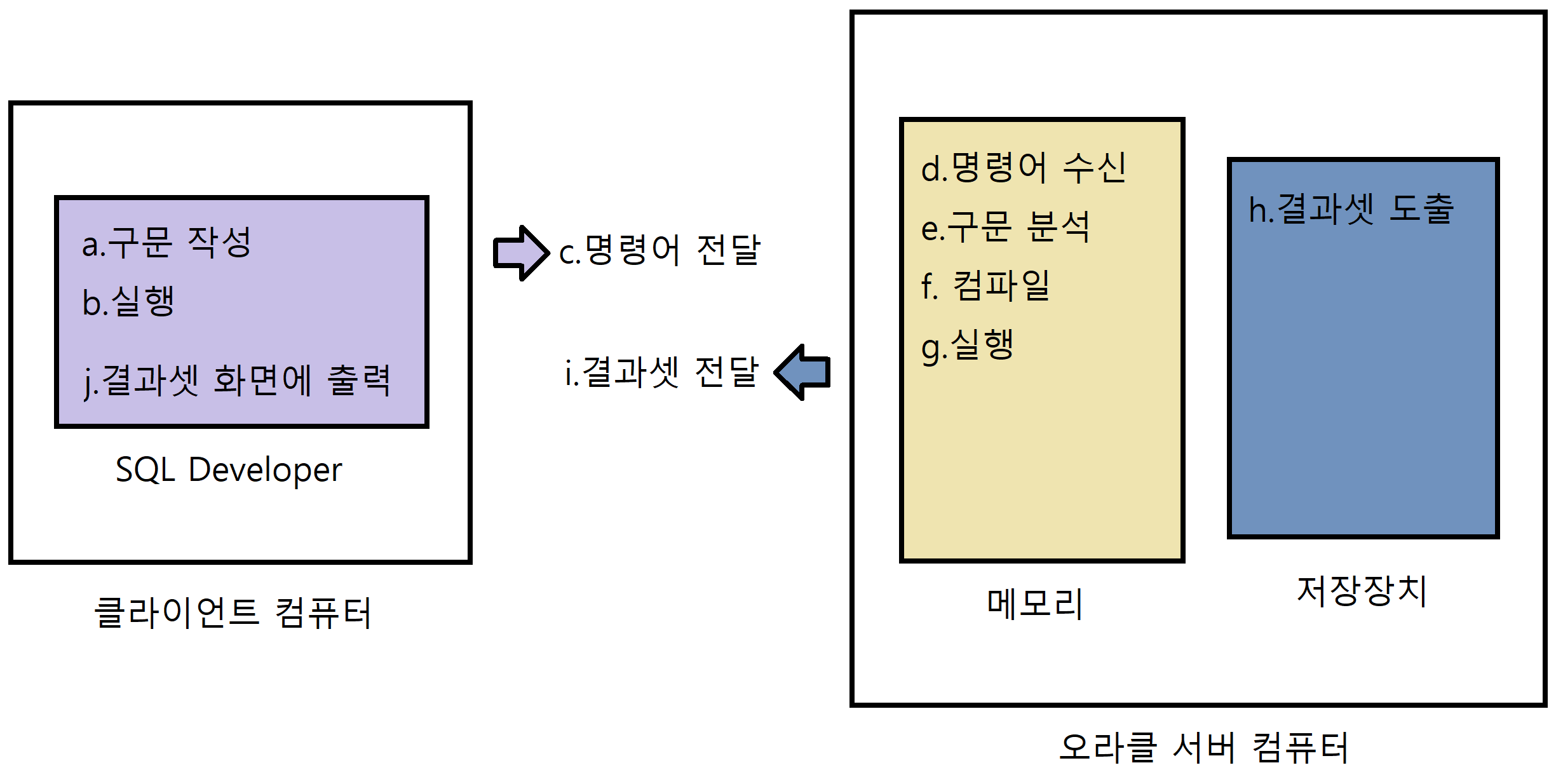
실행 과정
a. 클라이언트에서 구문(select)을 작성한다.
b. 실행 (Ctrl + Enter)
c. 명령어를 오라클 서버에 전달
d. 서버가 명령어를 수신
e. 구문 분석(파싱) + 문법 검사
f. 컴파일
g. 실행 (프로시저 실행)
h. 결과 셋 도출
i. 결과 셋을 클라이언트에게 반환
j. 결과 셋을 화면에 출력
실행 과정 설명
a: 구문을 작성한다고 뭔가 일어나는 건 아니다. 이게 실제 액션이 일어나려면 실행이 되어야 한다.
b: a와 b 행동을 한 곳은 클라이언트 컴퓨터의 SQL Developer이다.
c: 실행을 하면 SQL Developer에서 작성한 내용을 메모리(오라클 서버)로 전달된다.
e: 파싱은 Select, from 등의 단어 하나하나가 올바른 단어인지 문법을 검사하는 것이다.
f: 모든 단어가 올바른 문법으로 작성된 것이 확인되었을 경우 컴파일을 한다.
g: 저장장치에 있는 인사 테이블을 메모리에 가져온다.
h: 만들어진 결과 테이블을 클라이언트에 돌려준다.
다시 실행
SELECT * FROM tblInsa;
위 쿼리를 연속해서 2번 실행한다고 할 때, 첫 번째 실행과 두 번째 실행 결과가 동일하다는 보장이 없다.
아무리 같은 문장을 실행한다고 하더라도 다른 팀원이 그 사이에 데이터를 수정하여 변화가 생겼을 가능성이 있기 때문에 매번 다른 것으로 받아들여 a~j까지 과정을 다시 실행한다.
한 번 실행했던 명령어를 다시 실행한다고 하더라도 위의 모든 과정을 재실행하므로 첫 번째 실행하는 비용 다시 실행하는 비용이 같다.
3. 실명 프로시저
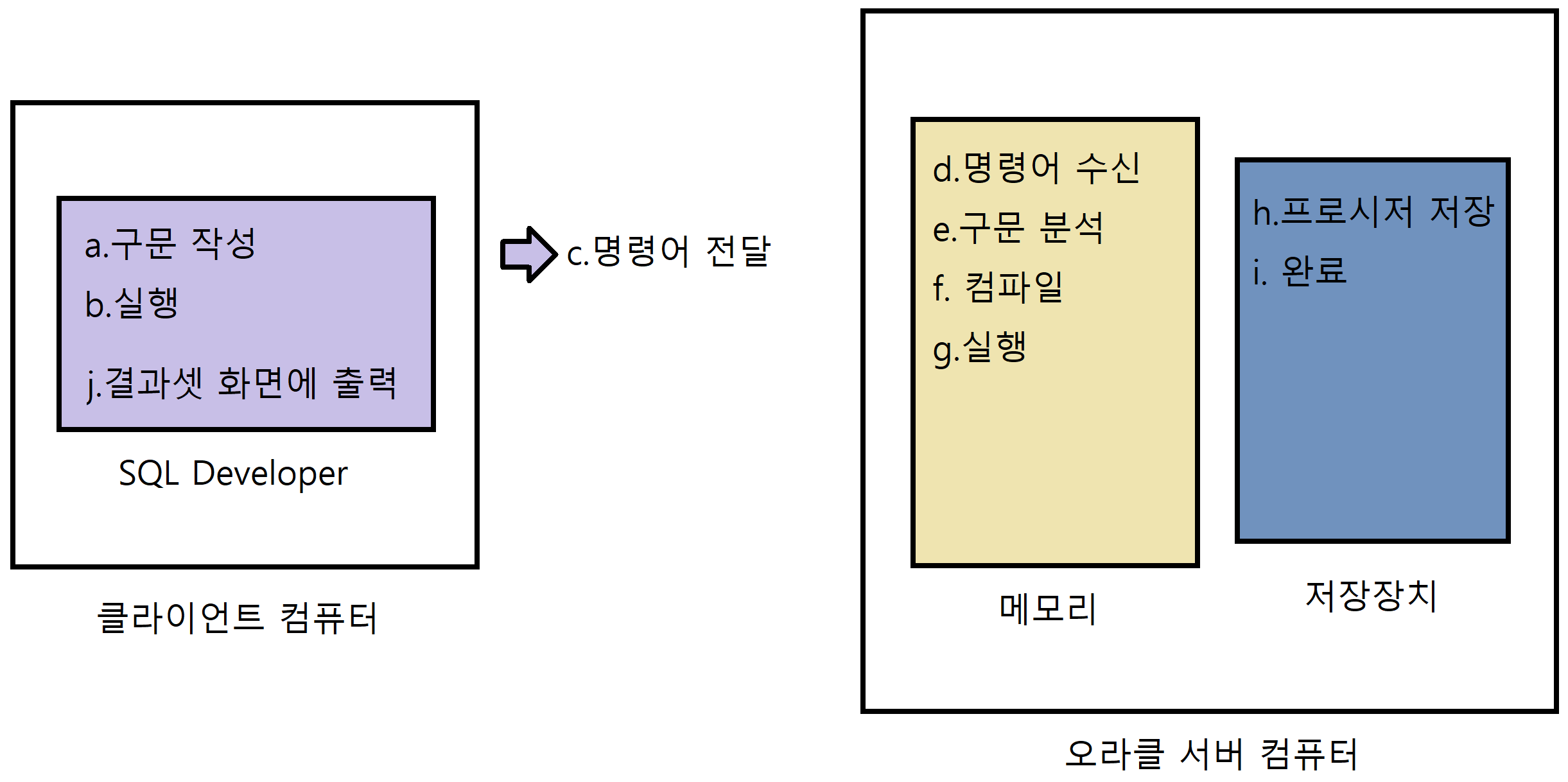
실행 과정
a. 클라이언트에서 구문(create)을 작성한다.
b. 실행 (Ctrl + Enter)
c. 명령어를 오라클 서버에 전달
d. 서버가 명령어를 수신
e. 구문 분석(파싱) + 문법 검사
f. 컴파일
g. 실행 (프로시저 실행)
h. 오라클 서버에 프로시저를 생성 (저장)
i. 완료
실행 과정 설명
a: 프로시저를 만드는 구문부터 실행하였다.
h: 오라클 서버에 저장되는 프로시저는 소스(원본)가 저장되는 게 아니고 구문을 컴파일한 기계어(결과)가 저장된다.
💡실명 프로시저
익명 프로시저는 1회용이므로 사용할 때마다 생성한다고 했다.
실명 프로시저는 재사용이 가능하며, 오라클에 저장한다는 특징이 있어 '저장 프로시저(Stored Procedure)'라는 표현을 더 많이 사용한다.
네트워크 트래픽의 이점
ANSI-SQL과 익명 프로시저는 코드를 저장하지 않기 때문에 매번 전체를 실행하고 컴파일한다.
하지만 실명 프로시저는 처음만 실행하면 그다음부터는 더 이상 컴파일하지 않고 생성한 프로시저의 이름만 호출하기 때문에 네트워크 트래픽이 상당히 줄어든다.
💡저장 프로시저
저장 프로시저(Stored Procedure)는 매개변수와 반환값을 구성하는 것에 제약이 없다.
익명 프로시저 선언
declare
변수 선언;
커서 선언;
begin
구현부;
exceoption
예외 처리;
end;
저장 프로시저 선언
create [or replace] procedure 프로시저명
is(as)
[변수 선언;
커서 선언;]
begin
구현부;
[exceoption
예외 처리;]
end;익명 프로시저에서 create로 이름을 붙여주면 저장 프로시저가 된다.
declare 대신에 is나 as 둘 중 하나를 필수로 사용한다.
저장 프로시저 생성
DECLARE
vnum NUMBER;
BEGIN
vnum := 100;
dbms_output.put_line(vnum);
END;
이 익명 프로시저를 저장 프로시저로 만들어보자.
CREATE OR REPLACE PROCEDURE procTest
IS
vnum NUMBER;
BEGIN
vnum := 100;
dbms_output.put_line(vnum);
END;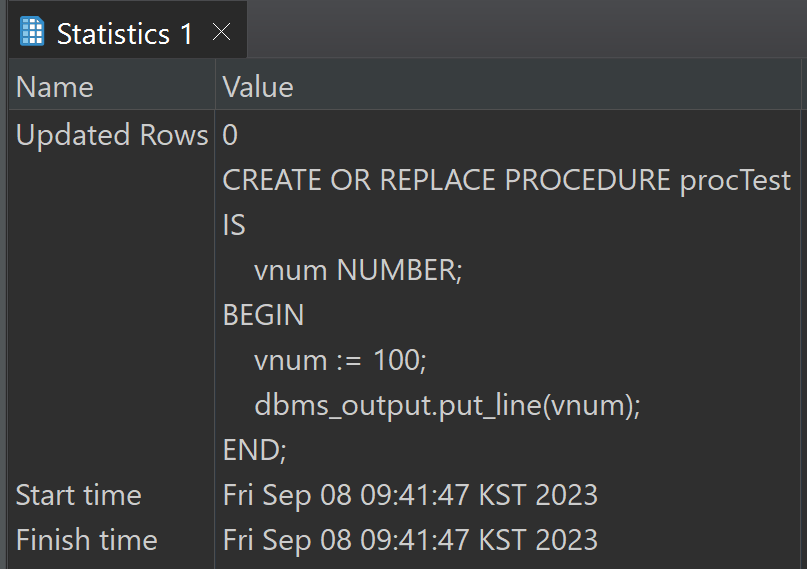
익명 프로시저를 실행했을 때와는 달리 저장 프로시저를 생성하는 걸로는 '100'이 출력되지 않는다.
그 이유는 위 코드는 저장 프로시저 객체를 만들 뿐, 안에 있는 것을 출력하지 않기 때문이다.
저장 프로시저는 메서드를 정의한 것이라고 생각하면 된다.
저장 프로시저 호출
BEGIN
procTest; --프로시저 호출
END;
저장 프로시저를 호출해 주어야 출력이 된다.
익명 블록의 도움을 받아 저장 프로시저를 호출할 수 있다.
📌매개변수가 있는 프로시저
CREATE OR REPLACE PROCEDURE procTest(pnum number)
IS
vresult NUMBER; --일반변수
BEGIN
vresult := pnum * 2;
dbms_output.put_line(vresult);
END procTest;END 뒤에 procTest 이름을 적는 게 좋다. 이는 가독성 때문이다.
괄호 안에 pnum이라는 이름으로 number자료형의 매개변수를 하나 받았다.
그리고 선언부에 일반 변수 vresult를 만들었다.
매개변수 전달
BEGIN
--PL/SQL 영역
procTest(100);
END;블럭 안에서 매개변수가 있는 프로시저를 실행하였다.
ANSI-SQL영역에서 출력
EXECUTE procTest(400);
EXEC procTest(500);
CALL procTest(500);
매개변수가 있는 프로시저 생성 시 규칙
CREATE OR REPLACE PROCEDURE procTest(
name varchar2
)
IS
--변수 선언이 없어도 반드시 기재
BEGIN
dbms_output.put_line('안녕? 네가 ' || name || '이니?');
END procTest;BEGIN
procTest('Isaac');
END;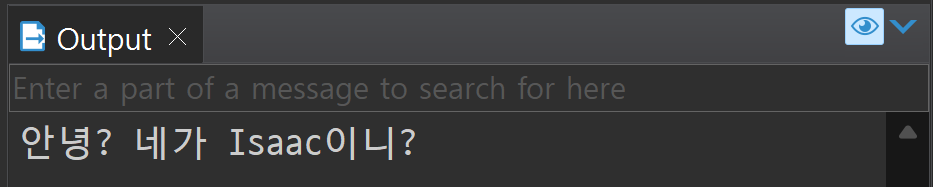
IS는 변수 선언이 없어도 반드시 기재해야 한다.
프로시저의 매개변수는 길이와 not null 표현이 불가능하다.
default값
CREATE OR REPLACE PROCEDURE procTest(
width NUMBER,
height NUMBER DEFAULT 10
)
IS
vresult NUMBER;
BEGIN
vresult := width * height;
dbms_output.put_line(vresult);
END procTest;BEGIN
procTest(10, 20); --width(10), height(10)
procTest(10); --width(10), height(10-DEFAULT)
END;height를 입력하여 호출하지 않았을 때에는 defualt 값이 들어간다.
📌매개변수 모드
- Call by Value
- Call by Reference
Call by Value는 매개변수 값을 넘기는 방식(값형 인자)이다.
Call by Reference는 매개변수 참조값(주소)을 넘기는 방식(참조형 인자)이다.
매개변수가 값을 전달하는 방식으로는 위의 두 가지가 있다.
- in 모드
- out 모드
- in out 모드
in out 모드 in과 out 모드의 기능을 합쳐 놓은 것으로, 혼동이 될 수 있기 때문에 잘 사용하지 않는다.
매개변수 모드의 사용
CREATE OR REPLACE PROCEDURE procTest(
--pnum1 NUMBER,
--pnum2 NUMBER
pnum1 IN NUMBER, --IN PARAMETER (인자값)
pnum2 IN NUMBER, --IN PARAMETER
presult OUT NUMBER --OUT PARAMETER (반환값)
)
IS
BEGIN
presult := pnum1 + pnum2;
END procTest;매개변수 모드를 적기도 하지만, 보통은 생략하는 편이다.
아니?? 이럴 수가..😮 매개변수는 바깥에서 값을 가져와 전달하는 역할을 했는데, 매개변수에 값을 집어넣고 있다.
pnum1, pnum2 파라미터는 우리가 쓰던 매개변수이며, out parameter에 엉뚱하게 값을 넣으며 끝이 났다.
BEGIN
procTest(10, 20, 100); --X
END;파라미터가 3개이기 때문에 매개변수를 3개를 입력하였다.
구현부에서 10 + 20으로 presult가 30인데, 100을 넣어주었다. 그러자 실행이 안 된다.
out이 붙은 파라미터는 절대로 값을 넣을 수 없다. 여기는 상수, 즉 값 자체를 넣을 수 없으며 대신에 변수를 넣는다.
DECLARE
vnum NUMBER;
BEGIN
procTest(10, 20, vnum);
dbms_output.put_line(vnum);
END;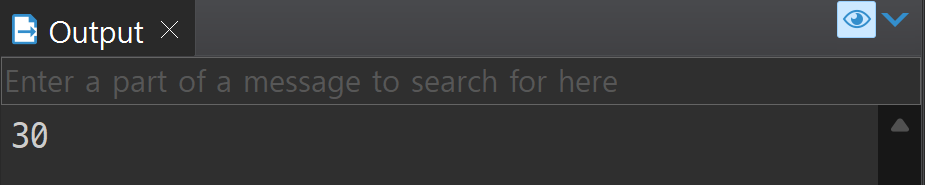
vnum 변수를 생성하여 매개변수로 넣어주었다. vnum은 현재 null 상태이다.
vnum을 출력하자 30이 출력된다.
이때는 참조값 복사(Call by Reference)가 작동이 되어서 변수의 값이 아니라 메모리 주소가 전달이 된다.
즉, presult는 일종의 반환값으로 생각하면 된다.
매개변수 모드의 활용
CREATE OR REPLACE PROCEDURE procTest(
--pnum1 IN NUMBER,
--pnum2 IN NUMBER
pnum1 IN NUMBER, --IN PARAMETER (인자값)
pnum2 IN NUMBER, --IN PARAMETER
presult OUT NUMBER, --OUT PARAMETER (반환값)
presult2 OUT NUMBER,
presult3 OUT number
)
IS
BEGIN
presult := pnum1 + pnum2;
presult2 := pnum1 - pnum2;
presult3 := pnum1 * pnum2;
END procTest;
DECLARE
vnum NUMBER;
vnum2 NUMBER;
vnum3 NUMBER;
BEGIN
procTest(10, 20, vnum, vnum2, vnum3);
dbms_output.put_line(vnum);
dbms_output.put_line(vnum2);
dbms_output.put_line(vnum3);
END;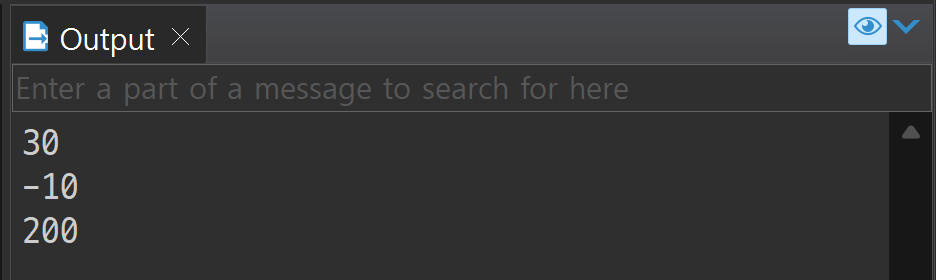
매개변수를 적는 만큼 반환값을 다양하게 돌려주는 게 가능하다.
문제 1
- 인자: 부서
- 반환: 해당 부서의 직원 중 급여를 가장 많이 받는 사람의 번호
CREATE OR REPLACE PROCEDURE procTest1 (
pbuseo varchar2,
pnum OUT NUMBER
)
IS
BEGIN
SELECT num INTO pnum FROM TBLINSA
WHERE basicpay = (SELECT max(basicpay) FROM tblInsa WHERE buseo = pbuseo)
AND buseo = pbuseo;
END procTest1;DECLARE
vnum NUMBER;
BEGIN
procTest1('기획부', vnum);
dbms_output.put_line(vnum);
END;
문제 2
- 인자: 직원 번호
- 반환: 직원 번호의 직원과 같은 지역에 사는 직원 수, 같은 직위에 해당하는 직원 수, 해당 직원보다 급여를 많이 받는 직원 수
CREATE OR REPLACE PROCEDURE procTest2 (
pnum IN NUMBER, --직원 번호
pcnt1 OUT NUMBER,
pcnt2 OUT NUMBER,
pcnt3 OUT NUMBER
)
IS
BEGIN
--같은 지역에 사는 직원 수
SELECT count(*) INTO pcnt1 FROM tblInsa WHERE city = (SELECT city FROM tblInsa WHERE num = 1001);
--같은 직위의 직원 수
SELECT count(*) INTO pcnt2 FROM tblInsa WHERE jikwi = (SELECT jikwi FROM tblInsa WHERE num = 1001);
--해당 직원보다 급여를 더 많이 받는 직원 수
SELECT count(*) INTO pcnt3 FROM tblInsa WHERE basicpay > (SELECT basicpay FROM tblInsa WHERE num = 1001);
END procTest2;DECLARE
vcnt1 NUMBER;
vcnt2 NUMBER;
vcnt3 NUMBER;
BEGIN
procTest2(1023, vcnt1, vcnt2, vcnt3);
dbms_output.put_line(vcnt1);
dbms_output.put_line(vcnt2);
dbms_output.put_line(vcnt3);
END;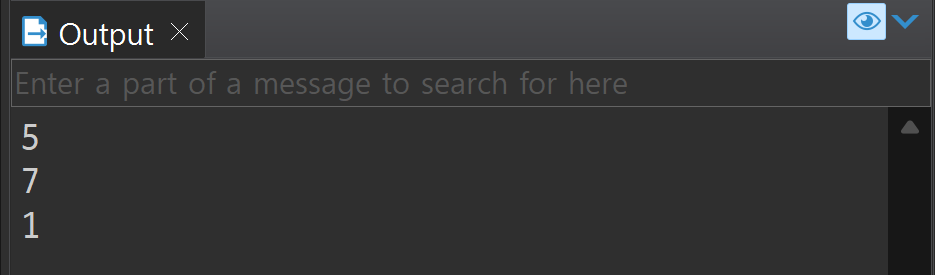
직원 퇴사 프로시저 (procDeleteStaff)
INSERT INTO tblStaff (seq, name, salary, address) VALUES (1, '홍길동', 300, '서울시');
INSERT INTO tblStaff (seq, name, salary, address) VALUES (2, '아무개', 250, '인천시');
INSERT INTO tblStaff (seq, name, salary, address) VALUES (3, '하하하', 250, '부산시');
INSERT INTO tblProject (seq, project, staff_seq) VALUES (1, '홍콩 수출', 1); --홍길동
INSERT INTO tblProject (seq, project, staff_seq) VALUES (2, 'TV 광고', 2); --아무개
INSERT INTO tblProject (seq, project, staff_seq) VALUES (3, '매출 분석', 3); --하하하
INSERT INTO tblProject (seq, project, staff_seq) VALUES (4, '노조 협상', 1); --홍길동
INSERT INTO tblProject (seq, project, staff_seq) VALUES (5, '대리점 분양', 2); --아무개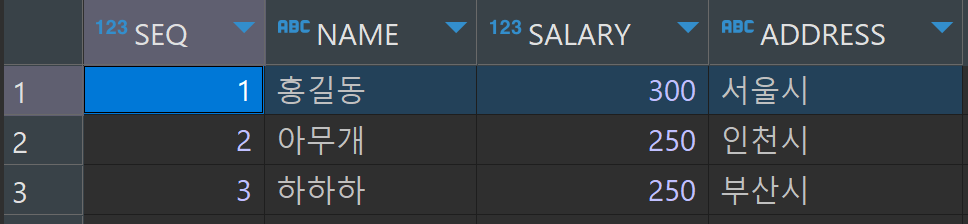
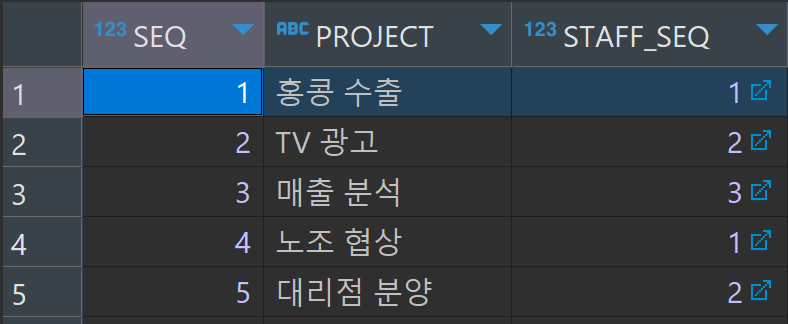
1. 퇴사 직원이 담당하고 있는 프로젝트를 확인한다.
2. 담당 프로젝트가 존재하면 위임한다.
3. 퇴사 직원을 삭제한다.
CREATE OR REPLACE PROCEDURE procDeleteStaff (
pseq NUMBER, --퇴사할 직원번호
pstaff NUMBER, --위임받을 직원번호
presult OUT NUMBER --피드백 > 성공(1) OR 실패(0)
)
IS
vcnt NUMBER; --퇴사 직원의 담당 프로젝트 개수
BEGIN
--1. 퇴사 직원이 담당하고 있는 프로젝트를 확인한다.
SELECT count(*) INTO vcnt FROM tblProject WHERE staff_seq = pseq;
--2. 담당 프로젝트가 존재하면 위임한다.
IF vcnt > 0 THEN
--위임
UPDATE tblProject SET staff_seq = pstaff WHERE staff_seq = pseq;
ELSE
--아무것도 안 함
NULL; --개발자의 의도 표시
END IF;
--3. 퇴사 직원을 삭제한다.
DELETE FROM tblStaff WHERE seq = pseq;
--4. 피드백 (성공)
presult := 1;
EXCEPTION
--4. 피드백 (실패)
WHEN OTHERS THEN
presult := 0;
END procDeleteStaff;1단계에서 퇴사 직원이 담당하고 있는 프로젝트의 개수를 확인하여 vcnt에 담당 프로젝트 개수를 넣는다.
2단계에서 vcnt를 확인하여 담당 프로젝트가 존재할 경우 프로젝트를 위임하고, 존재하지 않을 경우 아무것도 하지 않는다.
else절에 아무것도 안 하겠다는 표시로 null을 적었다. 아무것도 없이 null이 적혀 있으면 이 조건의 else절에서는 아무것도 하지 말라는 개발자의 의도를 표현한 것이다.
DECLARE
vresult NUMBER;
BEGIN
procDeleteStaff(1, 2, vresult);
IF vresult = 1 THEN
dbms_output.put_line('퇴사 성공');
ELSE
dbms_output.put_line('퇴사 실패');
END IF;
END;

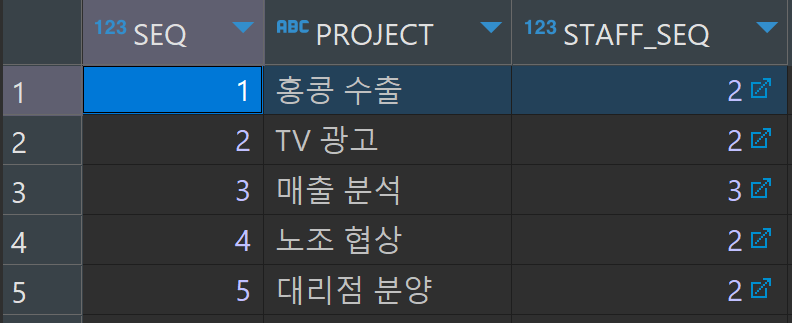
코드를 실행하자 퇴사 성공이 되며, 직원 테이블과 담당 프로젝트 테이블에 수정이 되었다.
위임받을 직원을 현재 프로젝트를 가장 적게 담당하고 있는 직원에게 자동으로 위임되도록 코드를 수정해 보도록 하자.
프로젝트를 가장 적게 담당하고 있는 직원의 프로젝트 수가 동률일 경우 rownum = 1을 사용한다.
💡저장 함수
저장 함수(Stored Function)는 매개변수와 반환값이 필수라는 제약이 있다.
저장 프로시저는 in 파라미터나 out 파라미터를 쓰는 게 개발자의 자유였지만, 저장 함수는 필수로 만들어야 한다.
그런데 이때 반환값은 out 파라미터를 말하는 게 아니다. 이때의 반환값은 return문을 말한다.
저장 함수에서는 out 파라미터를 사용하지 않고, 대신에 return문을 사용한다. 이러한 특성 때문에 호출하는 구문이 다르다.
저장 프로시저
CREATE OR REPLACE PROCEDURE procSum(
num1 IN NUMBER,
num2 IN NUMBER,
presult OUT number
)
IS
BEGIN
presult := num1 + num2;
END procSum;
DECLARE
vresult NUMBER;
BEGIN
procSum(5, 10, vresult);
dbms_output.put_line(vresult);
END;저장 프로시저는 PL/SQL 전용으로 사용하여 업무 절차를 모듈화 시켜 놓은 것이다.
저장 함수는 ANSI-SQL에서 사용한다.
저장 함수
CREATE OR REPLACE FUNCTION fnSum(
num1 IN NUMBER,
num2 IN NUMBER
--presult out number
) RETURN number
IS
BEGIN
RETURN num1 + num2;
--presult := num1 + num2;
END fnSum;BEGIN
dbms_output.put_line(fnSum(5, 10));
END;out을 사용하면 함수의 고유 특성이 사라지고 프로시저와 동일해진다.
return을 사용할 때 반환되는 타입을 명시해 준다.
저장 함수의 사용
select
name, basicpay, sudang,
--procSum(basicpay, sudang, 변수)
fnSum(basicpay, sudang)
from tblInsa;create or replace function fnGender(pssn varchar2) return varchar2
is
begin
return case
when substr(pssn, 8, 1) = '1' then '남자'
when substr(pssn, 8, 1) = '2' then '여자'
end;
end fnGender;select
name, buseo, jikwi,
case
when substr(ssn, 8, 1) = '1' then '남자'
when substr(ssn, 8, 1) = '2' then '여자'
end as gender,
fnGender(ssn) as gender2
from tblInsa;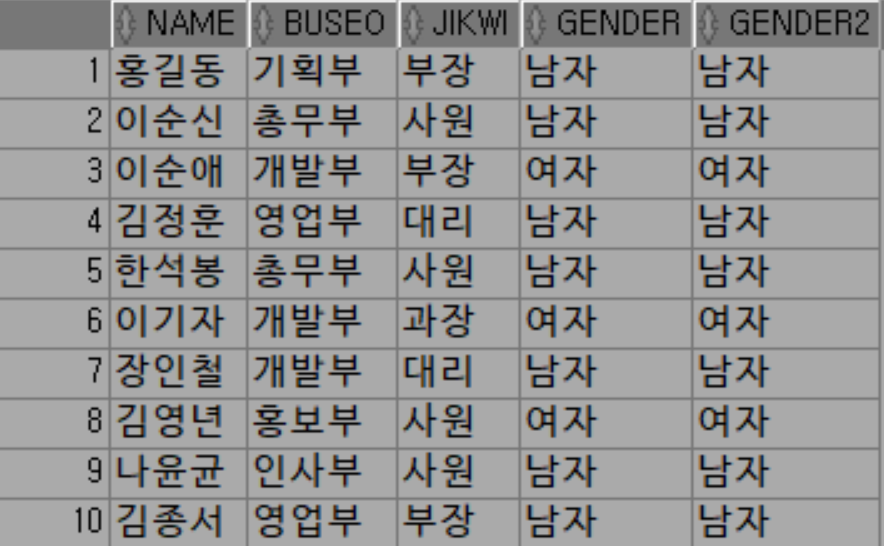
💡트리거 (Trigger)
트리거는 프로시저의 한 종류이다.
개발자의 호출이 아닌, 미리 지정한 특정 사건이 발생하면 시스템이 자동으로 실행하는 프로시저이다.
먼저 사건을 예약하고, 언젠가 그 사건이 발생하게 되면 그 상태의 프로시저가 호출이 된다.
사건의 종류를 지정해 놓을 뿐, 언제 터질지는 알 수가 없다. 그래서 오라클에게 호출을 맡겨놓는다.
사건은 뭘까?
특정 테이블을 지정을 하면 오라클이 테이블을 모니터링하기 시작한다.
직원 한 명이 삭제, 수정, 추가되었을 때 이를 사건이라고 한다. 그리고 이 시점에 미리 준비해 놓은 프로시저를 호출하는 게 바로 트리거이다.
트리거 구문
create or replace trigger 트리거명
before|after
insert|update|delete
on 테이블명
[for each row]
declare
선언부;
begin
구현부;
exception
예외처리부;
end;
트리거의 사용
before|after 트리거
CREATE OR replace TRIGGER trgInsa
BEFORE --before|after
DELETE --삭제가 발생하는지 감시
ON tblInsa --tblInsa 테이블(감시)
BEGIN
dbms_output.put_line(to_char(sysdate, 'hh24:mi:ss') || '트리거가 실행되었습니다.');
END trgInsa;tblinsa 테이블만 보면서 언제 직원이 삭제되는지를 감시한다.
before는 삭제가 발생하기 직전에 아래의 구현부를 먼저 실행하라는 의미이다.
사건이 터지고 난 뒤에 실행하려면 after 트리거를 걸면 된다.
시작하거나 중지시키는 명령어가 없으므로 트리거를 없애기 위해서는 drop 해야 한다.
CREATE OR replace TRIGGER trgInsa
BEFORE --before|after
DELETE --삭제가 발생하는지 감시
ON tblInsa --tblInsa 테이블(감시)
BEGIN
dbms_output.put_line(to_char(sysdate, 'hh24:mi:ss') || '트리거가 실행되었습니다.');
--월요일에는 퇴사 불가
if to_char(sysdate, 'dy') = '월' Then
--강제로 에러 발생 (throw now Exception())
raise_application_error(-20001, '월요일에는 퇴사가 불가합니다.');
end if;
END trgInsa;DELETE FROM tblInsa WHERE num = 1010;
raise_application_error 구문으로 에러를 강제로 발생시킬 수 있다.
로그 기록 트리거
테이블 생성
CREATE TABLE tblLogDiary (
seq number PRIMARY KEY,
message varchar2(1000) NOT NULL,
regdate date DEFAULT sysdate NOT NULL
);
CREATE SEQUENCE seqLogDiary;
트리거 생성
CREATE OR REPLACE TRIGGER trgDiary
AFTER
INSERT OR UPDATE OR DELETE
ON tblDiary
DECLARE
vmessage varchar2(1000);
BEGIN
dbms_output.put_line(to_char(sysdate, 'hh24:mi:ss') || '트리거가 실행되었습니다.');
END trgDiary;
트리거 실행
INSERT INTO tblDiary VALUES (11, '프로시저를 공부했다.', '흐림', sysdate);
UPDATE tblDiary SET subject = '프로시저를 복습했다.' WHERE seq = 11;
DELETE FROM tblDiary WHERE seq = 11;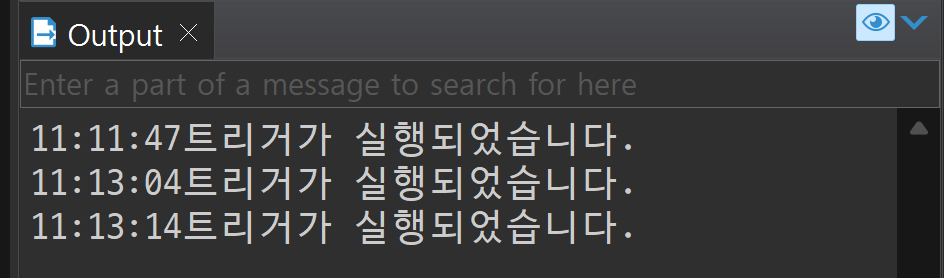
insert, update, delete를 or로 묶어 함께 트리거를 실행할 수 있다.
만약 이를 구분하여 실행하려면 if문을 사용하면 된다.
if문으로 trigger 구분
CREATE OR REPLACE TRIGGER trgDiary
AFTER
INSERT OR UPDATE OR DELETE
ON tblDiary
DECLARE
vmessage varchar2(1000);
BEGIN
--dbms_output.put_line(to_char(sysdate, 'hh24:mi:ss') || '트리거가 실행되었습니다.');
IF inserting THEN
--dbms_output.put_line('추가');
vmessage := '새로운 항목이 추가되었습니다.';
ELSIF updating THEN
--dbms_output.put_line('수정');
vmessage := '기존 항목이 수정되었습니다.';
ELSIF deleting THEN
--dbms_output.put_line('삭제');
vmessage := '기존 항목이 삭제되었습니다.';
END IF;
INSERT INTO tblLogDiary VALUES (seqLogDiary.nextVal, vmessage, DEFAULT);
END trgDiary;INSERT INTO tblDiary VALUES (11, '프로시저를 공부했다.', '흐림', sysdate);
UPDATE tblDiary SET subject = '프로시저를 복습했다.' WHERE seq = 11;
DELETE FROM tblDiary WHERE seq = 11;
이러한 로그 작업은 트리거로 구현하는 대표적인 작업 중에 하나이다.
for each row
1. 생략
문장(Query) 단위 트리거. (Table level trigger)
사건에 적용된 행의 개수와 무관하다. 따라서 트리거를 1번만 호출한다.
적용된 레코드의 정보는 중요하지 않고, 사건 자체가 중요한 경우에 사용한다.
2. 사용
행(Record) 단위 트리거
사건이 실행될 때마다 하나하나 트리거를 실행한다.
적용된 레코드의 정보가 사건 자체보다 중요한 경우에 사용한다.
상관관계를 사용한다. 이때 일종의 가상 레코드가 쓰인다. (:old, :new)
insert
- :new > 방금 추가된 행
update
- :old > 수정되기 전 행
- :new > 수정된 후 행
delete
- :old > 삭제되기 전 행
아무 때나 가상 레코드를 사용할 수 없으므로, 상황에 따라 사용해야 한다.
insert는 사건이 발생하기 전에는 레코드가 없으므로 old를 사용할 수 없고, delete는 사건이 발생된 후에 레코드가 없으므로 new를 사용할 수 없다.
for each row의 사용
CREATE OR REPLACE TRIGGER trgMen
AFTER
DELETE
ON tblMen
FOR EACH ROW
BEGIN
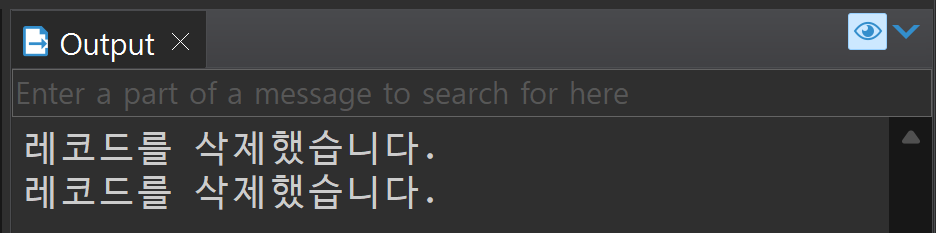
dbms_output.put_line('레코드를 삭제했습니다.' || :OLD.name);
END trgMen;DELETE FROM tblMen WHERE name = '홍길동'; --1명 삭제 > 트리거 1회 실행
DELETE FROM tblmen WHERE age < 25; --2명 삭제 > 트리거 1회 실행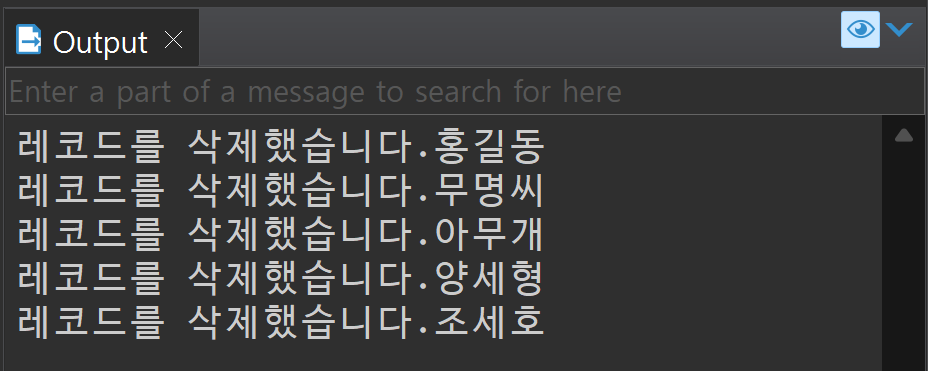
CREATE OR REPLACE TRIGGER trgMen
AFTER
UPDATE
ON TBLMEN
FOR EACH ROW
BEGIN
dbms_output.put_line('레코드를 수정했습니다.' || :OLD.name);
dbms_output.put_line('수정하기 전 나이: ' || :OLD.age); --수정 전 나이
dbms_output.put_line('수정하기 전 나이: ' || :NEW.age); --수정 후 나이
END trgMen;
UPDATE tblMen SET age = age + 1 WHERE name = '홍길동';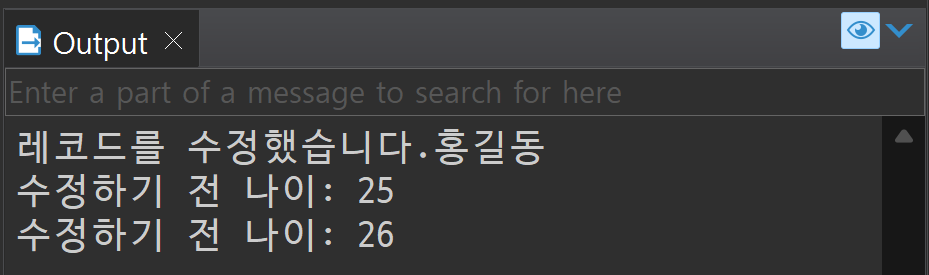
UPDATE tblMen SET age = age + 1;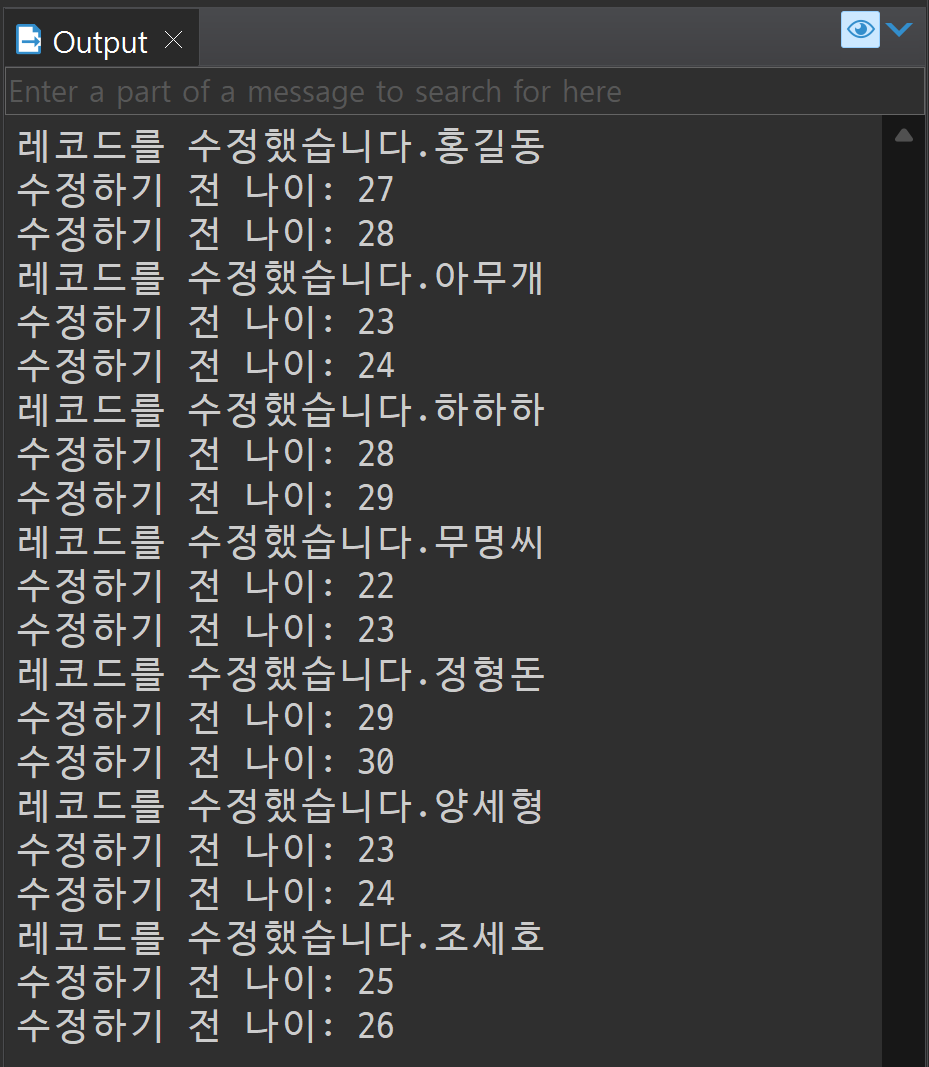
퇴사 트리거
CREATE OR REPLACE TRIGGER trgDeleteStaff
BEFORE --3. 전에
DELETE --2. 퇴사
ON tblStaff --1. 직원 테이블에서
FOR EACH ROW --4. 해당 직원 정보
BEGIN
--5. 위임 진행
UPDATE tblProject SET
staff_seq = 3
WHERE staff_seq = :OLD.seq; --퇴사하는 직원 번호
END trgDeleteStaff;SELECT * FROM tblStaff;
SELECT * FROM tblProject;
DELETE FROM tblStaff WHERE seq = 1;직원을 퇴사하는 프로시저를 만들어 퇴사 바로 직전에 담당 프로젝트를 체크하여 다른 사람에게 위임할 수 있게 해 보도록 하자.
회원 테이블, 게시판 테이블
포인트 제도
- 글 작성: 포인트 + 100
- 글 삭제: 포인트 - 100
CREATE TABLE tblUser(
id varchar2(30) PRIMARY KEY,
point NUMBER DEFAULT 1000 NOT NULL
);
INSERT INTO tblUser VALUES ('isaac', default);
CREATE TABLE tblBoard (
seq NUMBER PRIMARY KEY,
subject varchar2(1000) NOT NULL,
id varchar2(30) NOT NULL REFERENCES tblUser(id)
);
CREATE SEQUENCE seqBoard;
Case 1. Hard
-- 1.1 글쓰기
INSERT INTO tblBoard VALUES (seqBoard.nextVal, '게시판입니다.', 'isaac');
-- 1.2 포인트 누적하기
UPDATE tblUser SET point = point + 100 WHERE id = 'isaac';
-- 1.3 글삭제
DELETE FROM tblBoard WHERE seq = 1;
-- 1.4 포인트 차감하기
UPDATE tblUser SET point = point - 50 WHERE id = 'isaac';Hard 한 방법으로, 개발자가 직접 제어하는 방법으로 기능을 구현하였다.
이 방법의 가장 큰 문제점은 일부 업무를 누락시킬 경우 안전장치가 없으면 포인트 관리가 제대로 이루어지지 않을 수 있다는 점이다.
Case 2. 프로시저
CREATE OR REPLACE PROCEDURE procAddBoard (
pid varchar2,
psubject varchar2
)
IS
BEGIN
-- 2.1 글쓰기
INSERT INTO tblBoard VALUES (seqBoard.nextVal, psubject, pid);
-- 2.2 포인트 누적하기
UPDATE tblUser SET point = point + 100 WHERE id = pid;
END procAddBoard;CREATE OR REPLACE PROCEDURE procDeleteBoard (
pseq NUMBER
)
IS
vid varchar2(30);
BEGIN
-- 2.1 삭제글의 작성자
SELECT id INTO vid FROM tblBoard WHERE seq = pseq;
-- 2.2 글삭제
DELETE FROM tblBoard WHERE seq = pseq;
-- 2.3 포인트 차감하기
UPDATE tblUser SET point = point - 50 WHERE id = vid;
END procDeleteBoard;프로시저로 기능을 구현하였다.
삭제를 먼저 하면 누가 글을 썼는지 알 방법이 없으므로, vid 변수에 삭제글의 작성자를 저장하여 사용한다.


Case 3. 트리거
CREATE OR REPLACE TRIGGER trgBoard
AFTER
INSERT OR DELETE
ON tblBoard
FOR EACH ROW
BEGIN
IF inserting THEN
UPDATE tblUser SET point = point + 100 WHERE id = :NEW.id;
ELSIF deleting THEN
UPDATE tblUser SET point = point - 50 WHERE id = :OLD.id;
END IF;
END trgBoard;INSERT INTO tblBoard VALUES (seqBoard.nextVal, '글을 작성했습니다.', 'isaac');
DELETE FROM tblBoard WHERE seq = 3;프로시저와 트리거를 둘 다 사용할 수 있다면 보통은 프로시저를 사용한다.
프로시저는 호출할 때를 제외하고 비용이 들어가지 않지만, 트리거는 실행하는 순간 24시간 계속 실행되기 때문이다.
