
💡릴레이션
릴레이션(Relation)은 행과 열로 구성된 테이블이다. 따라서 릴레이션이라고 하면 표를 떠올리면 된다.
이때 행과 열은 단순히 구조만 나타내는 게 아니라 서로 연관되어 있는데, 서로 관계있는 것들을 모아놓았기에 릴레이션이라는 표현을 사용한 것이다.
릴레이션 스키마와 인스턴스
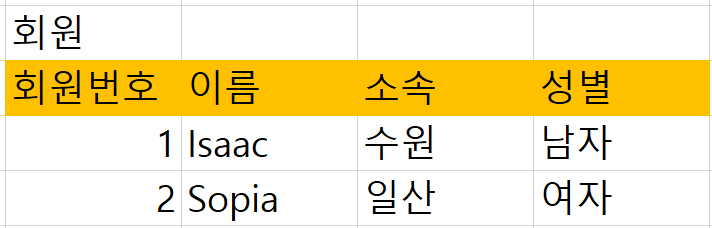
회원 테이블에 주황색으로 컬럼이 정의되어 있다. 이를 스키마라고 한다.
스키마에 구성된 하나하나를 속성(어트리뷰트)라고 한다. 속성은 컬럼의 정보이다.
표의 행(레코드)에 데이터를 집어 넣는데, 이를 인스턴스라고 부르기도 하고, 이론적으로는 튜플이라는 표현을 쓰기도 한다. 튜블, 레코드, 로우, 인스턴스 이 말을 모두 같은 말이다. 어디에서 이 말을 만들어 냈는지에 대한 차이가 있을 뿐이다.
각 속성이 어떤 값을 가질 수 있는지에 대해서는 도메인이라는 용어로 정리한다.
차수는 컬럼의 개수를 말한다. 위 테이블은 차수가 4개이다.
튜블은 레코드라고 했다. 카디날리티는 튜플(행)의 개수, 즉 레코드(데이터)의 개수를 의미한다.
- 속성: 릴레이션 스키마의 열
- 도메인: 컬럼(속성)이 가질 수 있는 값의 집합
- 차수: 컬럼(속성)의 개수
- 튜플: 릴레이션의 행
- 카디날리티: 튜플의 개수
릴레이션 스키마 표기
- 회원(회원번호, 이름, 소속, 성별)
- 회원(회원번호: integer, 이름: char(40), 소속: char(40), 성별: char(40))
회원 릴레이션 스키마는 위와 같이 표기할 수 있다.
보통은 전자의 표현을 사용한다.
데이터 구조 설계
속성의 이름만 가지고서는 어떤 데이터를 가지고 있는지 알 수 없다.
예를 들어, '회원번호'라는 속성의 이름만을 보고는 그 값이 어떤 의미를 가지는지 알기 어렵다. 이 숫자가 무엇을 나타내는지, 어떤 사람의 정보를 가리키는지, 또는 다른 속성과 어떤 관련성이 있는지 등은 사람이 알 수는 있지만, 컴퓨터가 자동으로 이해하기 어렵다는 말이다.
데이터베이스를 사용하는 사람은 각 속성의 의미와 값들 간의 관계를 이해하고 데이터를 의미 있는 방식으로 활용할 수 있어야 한다. 따라서 데이터베이스를 설계할 때는 속성의 이름을 명확하게 지정하고, 데이터의 구조와 의미를 이해하기 쉽게 설계하는 것이 중요하다.
수학적 표현
오라클에서 사용하는 SELECT, INSERT 등의 대부분의 정의가 수학적 표현을 따른다.
관계 데이터 모델이 수학에 영향을 많이 받은 모델이다.
릴레이션의 특징⭐
- 각 속성은 하나의 값을 가져야 한다.
- 각 속성은 고유한 이름을 가져야 한다.
- 각 속성의 값은 특정한 데이터 도메인에 속하는 값만을 가진다.
- 릴레이션 내에서 속성들의 순서는 중요하지 않다.
- 릴레이션 내에서 동일한 튜플이 중복되어 저장되지 않는다.
- 릴레이션 내에서 튜플들의 순서는 중요하지 않다.
1. 각 속성은 하나의 값을 가져야 한다.

테이블을 생성할 때, 어떤 속성을 가질지를 설계부터 한다. 나는 회원 정보를 관리하고 싶어서 번호, 이름, 나이, 주소, 취미로 구성을 하면 적당할 듯 하다.
이제 도메인 정의를 할 차례이다. 취미에는 독서, 운동, 낮잠, 여행 등의 단어를 집어 넣게 될 것이다. 이러한 샘플을 미리 정의해둔 것을 도메인이라고 한다.
나이의 경우 도메인은 최소 20자 이상 100자 이내의 정수값이 된다. 즉 도메인은 샘플 데이터이다.
더이상 쪼개지지 않는 것을 원자값이라고 한다. Swim과 Sing은 더이상 쪼개지지 않는 원자값이며, 이러한 데이터가 들어가야 한다. 취미가 여행과 운동이라고 해서 Trip, Sport라고 해서는 안 된다는 뜻이다. 이를 반대로 얘기하면 관계형 데이터 모델이는 한 개의 데이터만을 가질 수 있다고 할 수 있다.
2. 각 속성은 고유한 이름을 가져야 한다.
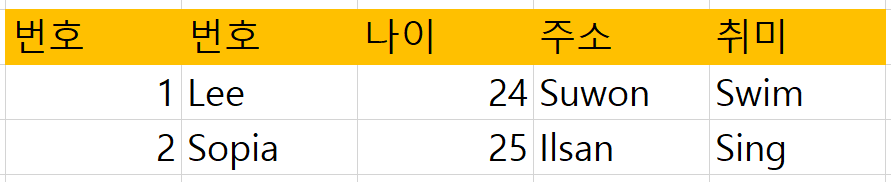
식별자가 같으면 안 된다.
위와 같이 속성으로 '번호'가 두 번 사용되면 안 되며, '나이'와 '주소' 등과 같이 서로 다른 속성 이름으로 사용되어야 한다.
3. 각 속성의 값은 특정한 데이터 도메인에 속하는 값만을 가진다.
속성 '번호'의 값은 1과 2로, 모두 정수이고, 속성 '나이'의 값은 24와 25로, 모두 정수입니다.
그리고 속성 '주소'의 값은 "Suwon"과 "Ilsan"으로, 모두 문자열이고, 속성 '취미'의 값은 "Swim"과 "Sing"으로, 모두 문자열이다.
이처럼 테이블에서 각 속성의 값은 모두 동일한 데이터 도메인에 속해야 한다.
4. 릴레이션 내에서 속성들의 순서는 중요하지 않다.
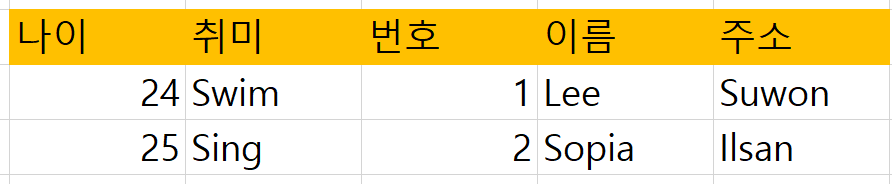
원본 테이블의 컬럼 순서는 아무 의미가 없다.
속성들의 나열 순서가 바뀌어도 데이터의 의미나 구조에는 영향을 미치지 않는다.
5. 릴레이션 내에서 동일한 튜플이 중복되어 저장되지 않는다.⭐

튜플의 중복을 허용하지 않는 이유는 중복된 튜플을 구분할 수 없기 때문이다.
이건 배열이 아니기 때문에 행의 번호가 없다. 사람이 보기에는 1번째 행, 2번째 행, 3번째 행으로 보이지만 오라클과 같은 관계 데이터 모델은 Set과 같아서 행에 번호가 없다.
똑같은 데이터를 집어 넣더라도 들어가긴 하지만, 중복된 값 중 하나만을 지울 수가 없다.
6. 릴레이션 내에서 튜플들의 순서는 중요하지 않다.
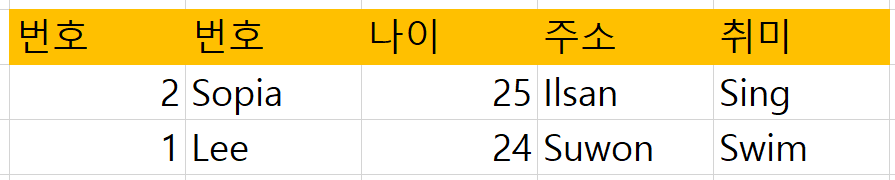
튜플(레코드) 순서를 따지지 않는다.
따라서 사용자 입장에서는 컬럼 순서가 바뀌든, 레코드의 순서가 바뀌든 아무 상관이 없다.

💡릴레이션
릴레이션(Relation)은 행과 열로 구성된 테이블이다. 따라서 릴레이션이라고 하면 표를 떠올리면 된다.
이때 행과 열은 단순히 구조만 나타내는 게 아니라 서로 연관되어 있는데, 서로 관계있는 것들을 모아놓았기에 릴레이션이라는 표현을 사용한 것이다.
릴레이션 스키마와 인스턴스
회원 테이블에 주황색으로 컬럼이 정의되어 있다. 이를 스키마라고 한다.
스키마에 구성된 하나하나를 속성(어트리뷰트)라고 한다. 속성은 컬럼의 정보이다.
표의 행(레코드)에 데이터를 집어 넣는데, 이를 인스턴스라고 부르기도 하고, 이론적으로는 튜플이라는 표현을 쓰기도 한다. 튜블, 레코드, 로우, 인스턴스 이 말을 모두 같은 말이다. 어디에서 이 말을 만들어 냈는지에 대한 차이가 있을 뿐이다.
각 속성이 어떤 값을 가질 수 있는지에 대해서는 도메인이라는 용어로 정리한다.
차수는 컬럼의 개수를 말한다. 위 테이블은 차수가 4개이다.
튜블은 레코드라고 했다. 카디날리티는 튜플(행)의 개수, 즉 레코드(데이터)의 개수를 의미한다.
- 속성: 릴레이션 스키마의 열
- 도메인: 컬럼(속성)이 가질 수 있는 값의 집합
- 차수: 컬럼(속성)의 개수
- 튜플: 릴레이션의 행
- 카디날리티: 튜플의 개수
릴레이션 스키마 표기
- 회원(회원번호, 이름, 소속, 성별)
- 회원(회원번호: integer, 이름: char(40), 소속: char(40), 성별: char(40))
회원 릴레이션 스키마는 위와 같이 표기할 수 있다.
보통은 전자의 표현을 사용한다.
데이터 구조 설계
속성의 이름만 가지고서는 어떤 데이터를 가지고 있는지 알 수 없다.
예를 들어, '회원번호'라는 속성의 이름만을 보고는 그 값이 어떤 의미를 가지는지 알기 어렵다. 이 숫자가 무엇을 나타내는지, 어떤 사람의 정보를 가리키는지, 또는 다른 속성과 어떤 관련성이 있는지 등은 사람이 알 수는 있지만, 컴퓨터가 자동으로 이해하기 어렵다는 말이다.
데이터베이스를 사용하는 사람은 각 속성의 의미와 값들 간의 관계를 이해하고 데이터를 의미 있는 방식으로 활용할 수 있어야 한다. 따라서 데이터베이스를 설계할 때는 속성의 이름을 명확하게 지정하고, 데이터의 구조와 의미를 이해하기 쉽게 설계하는 것이 중요하다.
수학적 표현
오라클에서 사용하는 SELECT, INSERT 등의 대부분의 정의가 수학적 표현을 따른다.
관계 데이터 모델이 수학에 영향을 많이 받은 모델이다.
릴레이션의 특징⭐
- 각 속성은 하나의 값을 가져야 한다.
- 각 속성은 고유한 이름을 가져야 한다.
- 각 속성의 값은 특정한 데이터 도메인에 속하는 값만을 가진다.
- 릴레이션 내에서 속성들의 순서는 중요하지 않다.
- 릴레이션 내에서 동일한 튜플이 중복되어 저장되지 않는다.
- 릴레이션 내에서 튜플들의 순서는 중요하지 않다.
1. 각 속성은 하나의 값을 가져야 한다.
테이블을 생성할 때, 어떤 속성을 가질지를 설계부터 한다. 나는 회원 정보를 관리하고 싶어서 번호, 이름, 나이, 주소, 취미로 구성을 하면 적당할 듯 하다.
이제 도메인 정의를 할 차례이다. 취미에는 독서, 운동, 낮잠, 여행 등의 단어를 집어 넣게 될 것이다. 이러한 샘플을 미리 정의해둔 것을 도메인이라고 한다.
나이의 경우 도메인은 최소 20자 이상 100자 이내의 정수값이 된다. 즉 도메인은 샘플 데이터이다.
더이상 쪼개지지 않는 것을 원자값이라고 한다. Swim과 Sing은 더이상 쪼개지지 않는 원자값이며, 이러한 데이터가 들어가야 한다. 취미가 여행과 운동이라고 해서 Trip, Sport라고 해서는 안 된다는 뜻이다. 이를 반대로 얘기하면 관계형 데이터 모델이는 한 개의 데이터만을 가질 수 있다고 할 수 있다.
2. 각 속성은 고유한 이름을 가져야 한다.
식별자가 같으면 안 된다.
위와 같이 속성으로 '번호'가 두 번 사용되면 안 되며, '나이'와 '주소' 등과 같이 서로 다른 속성 이름으로 사용되어야 한다.
3. 각 속성의 값은 특정한 데이터 도메인에 속하는 값만을 가진다.
속성 '번호'의 값은 1과 2로, 모두 정수이고, 속성 '나이'의 값은 24와 25로, 모두 정수입니다.
그리고 속성 '주소'의 값은 "Suwon"과 "Ilsan"으로, 모두 문자열이고, 속성 '취미'의 값은 "Swim"과 "Sing"으로, 모두 문자열이다.
이처럼 테이블에서 각 속성의 값은 모두 동일한 데이터 도메인에 속해야 한다.
4. 릴레이션 내에서 속성들의 순서는 중요하지 않다.
원본 테이블의 컬럼 순서는 아무 의미가 없다.
속성들의 나열 순서가 바뀌어도 데이터의 의미나 구조에는 영향을 미치지 않는다.
5. 릴레이션 내에서 동일한 튜플이 중복되어 저장되지 않는다.⭐
튜플의 중복을 허용하지 않는 이유는 중복된 튜플을 구분할 수 없기 때문이다.
이건 배열이 아니기 때문에 행의 번호가 없다. 사람이 보기에는 1번째 행, 2번째 행, 3번째 행으로 보이지만 오라클과 같은 관계 데이터 모델은 Set과 같아서 행에 번호가 없다.
똑같은 데이터를 집어 넣더라도 들어가긴 하지만, 중복된 값 중 하나만을 지울 수가 없다.
6. 릴레이션 내에서 튜플들의 순서는 중요하지 않다.
튜플(레코드) 순서를 따지지 않는다.
따라서 사용자 입장에서는 컬럼 순서가 바뀌든, 레코드의 순서가 바뀌든 아무 상관이 없다.