
💡텍스트 전처리
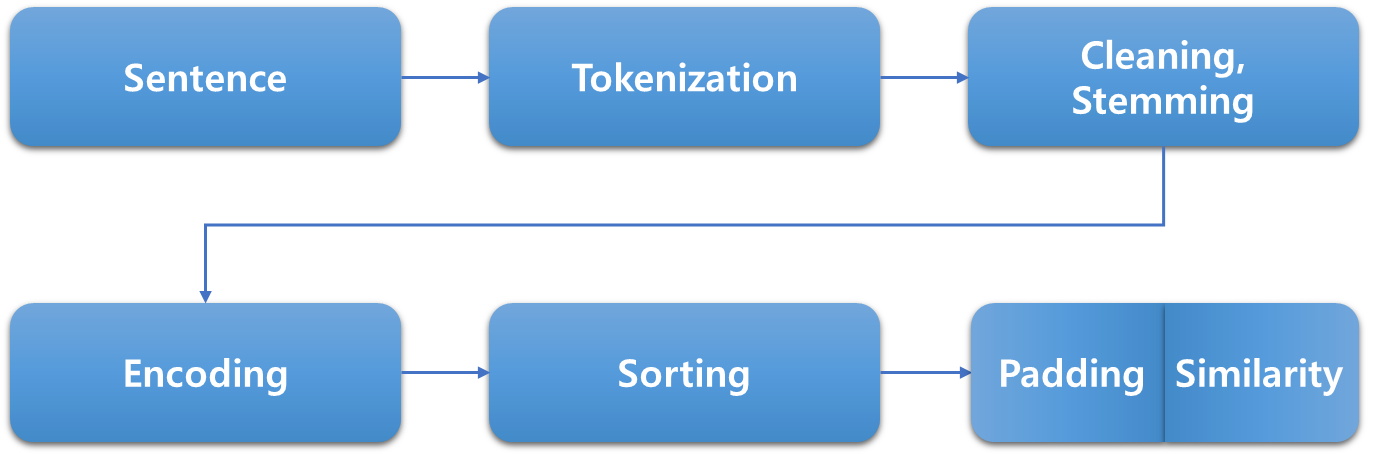
텍스트 전처리는 자연어를 컴퓨터가 이해하고 처리할 수 있는 형태로 변환하는 과정이다. 이를 통해 기계는 자연어를 이해하고, 인공지능은 텍스트 데이터를 학습할 수 있게 된다.
텍스트 전처리 과정은 Sentence, Tokenization, Cleaning, Stemming, Encoding, Sorting, Padding/Similarity로 진행된다.
🔎언어의 형태소
한글은 띄어쓰기가 되어 있지 않은데 함축적으로 들어 있는 내용과 파생 표현이 많기 때문에 토큰화를 진행하기가 어렵다. 그렇기 때문에 자연어를 효과적으로 처리할 수 있도록 전처리 과정이 필수적이다.
예시 문장: 바쁜 일상 속에서도 책을 읽는 것은 마음의 휴식이 된다.
- "바쁜": 자립 형태소 (형용사)
- "일상": 자립 형태소 (명사)
- "속에서도": 의존 형태소 (조사)
- "책": 자립 형태소 (명사)
- "을": 의존 형태소 (조사)
- "읽": 자립 형태소 (동사 어간)
- "는": 의존 형태소 (관형사)
- "것": 자립 형태소 (명사)
- "은": 의존 형태소 (조사)
- "마음": 자립 형태소 (명사)
- "의": 의존 형태소 (조사)
- "휴식": 자립 형태소 (명사)
- "이": 의존 형태소 (관형사)
- "된다": 의존 형태소 (동사)
자립 형태소: 명사, 수사, 부사, 감탄사
의존 형태소: 조사, 어미 어간
토큰화 (Tokenization)
토큰화는 텍스트를 의미 있는 최소 단위로 분리하는 과정으로, 문장을 단어 또는 형태소와 같은 의미 부여가 가능한 단위로 나누는 작업을 한다.
문장 토큰화는 문장 단위로 의미를 나누는 것을 의미하며, 잘 사용하지 않는다.
원본 문장: "The adventurous explorer discovered an ancient treasure hidden deep within the dense, mysterious jungle during a daring expedition."
예시 문장: ["The", "adventurous", "explorer", "discovered", "an", "ancient", "treasure", "hidden", "deep", "within", "the", "dense", "mysterious", "jungle", "during", "a", "daring", "expedition"]
Treebank Tokenization
# NLTK 설치
pip install nltk
# NLTK에서 Treebank Tokenization 모듈 가져오기
import nltk
from nltk.tokenize import TreebankWordTokenizer
# Treebank Tokenizer 객체 생성
tokenizer = TreebankWordTokenizer()
# 토큰화 수행
sentence = "Sample sentence for Tokenization."
tokens = tokenizer.tokenize(sentence)
# 결과 출력
print(tokens)Treebank Tokenization은 NLTK 라이브러리의 TreebankWordTokenizer 모듈을 통해 사용할 수 있다. 이 토큰화 기법은 Penn Treebank 코퍼스에 기반하여 영어 문장을 토큰으로 분리하는 데 사용한다.
패키지에 따라서 하이픈을 무시하고 모델과 베이스를 분리하기도 한다. 따라서 패키지의 특성을 확인하여 토큰화를 진행하는 것이 중요하다.
정제 (Cleaning)
정제 및 추출 단계에서는 토큰화된 결과에서 불필요한 정보를 제거하고 중요한 정보를 추출한다. 이를 통해 텍스트 데이터를 정리하고 의미 있는 부분을 강조한다.
불필요한 구두점이나 불용어(Stop words)를 제거하고, 단어의 원형을 추출하는 등의 작업을 진행한다.
원본 문장: "The adventurous explorer discovered an ancient treasure hidden deep within the dense, mysterious jungle during a daring expedition."
예시 문장: ["adventurous", "explorer", "discovered", "ancient", "treasure", "hidden", "deep", "dense", "mysterious", "jungle", "daring", "expedition"]
대문자와 소문자 통일
정제 작업에서는 데이터의 사용 목적에 맞추어 노이즈를 제거한다. 이 과정에서 대문자를 소문자로 통일하는 작업을 하는데, 이때 주의해야 할 점이 있다.
미국을 의미하는 US를 us로 바꾸면 의미가 달라지기 때문에 이러한 부분에서 예외 처리를 할 필요가 있다.
출현 횟수가 적은 단어 제거
'Floras and faunas'와 같이 논문이나 시험에서 사용되는 출현 횟수가 적은 단어가 있다. 이러한 단어가 문장에 중심 단어가 되지 않는다면 굳이 토큰화를 할 필요가 없으므로 제거해도 된다. 그러나 딱 한 번 등장하더라도 키워드가 되는 단어라면 지워서는 안 된다.
결국 전처리 과정에서 모두 컴퓨터에서 처리할 수 있는 것은 아니며, 아직까지 사람의 주관이 필요하다.
길이가 짧은 단어, 지시(대)명사, 관사 제거
길이가 2 이하인 단어 또는 지시(대)명사(this, that 등)와 관사(a, an, the)를 제거한다.
추출 (Stemming)
어간(Stem)은 단어의 의미를 담은 핵심 부분을 말하며, 접사(Affix)는 단어에 추가적인 용법을 부여하는 부분이다. 예를 들어, "running"이라는 단어에서 어간은 "run"이며, 접사는 "ning"이다.
불필요한 접사 제거
추출 작업에서는 단어에서 의미를 가진 어간을 추출하여 원형 단어를 도출하고, 불필요한 접사를 제거한다. 이때, 지워도 의미에 큰 영향을 미치지 않는 부분은 지워진다.
예를 들어, "is", "are", "was", "were"와 같은 형태소, "s", "ing", "ness"와 같은 어미는 의미에 큰 영향을 미치지 않기 때문에 제거될 수 있다.
어간 추출 (Stemming)
어간 추출은 단어에서 접사를 제거하여 단어의 기본 형태를 찾는 과정이다.
예를 들어, "running"의 어간은 "run"이다. 이때, "running"에서 "-ing"을 제거하여 어간을 추출한다.
어간 추출은 단어의 의미를 축소하여 처리하므로, 동일한 어간을 가진 단어들은 유사한 의미를 갖게 된다.
대표적인 어간 추출 알고리즘으로는 Porter Algorithm이 있다.
표제어 추출 (Lemmatization)
표제어 추출은 단어를 그 형태소의 기본 사전 형태로 변환하는 과정이다.
어간 추출과 달리 단어의 품사 정보를 보존한다. 예를 들어, "better"의 표제어는 "good"이다.
표제어 추출은 더 정확한 결과를 얻을 수 있지만, 어간 추출보다 연산 비용이 높다.
불용어 (Stopword)
불용어는 문장에서 대세로 작용하지 않거나 중요도가 낮은 단어들을 의미한다. 이러한 단어들은 텍스트 처리나 자연어 처리 과정에서 제외하거나 제거함으로써 효율적인 분석을 할 수 있다.
예를 들면 'the', 'is', 'and', 'in' 등이 일반적인 불용어에 해당한다.
불용어 제거 방법
- 불용어 목록을 받아오기: 미리 정의된 불용어 목록을 사용하거나, 특정 상황에 맞게 사용자가 직접 불용어를 선정한다.
- 정제할 문장을 토큰화 (tokenize): 문장을 단어 또는 어절로 나누어 토큰화한다.
- 토큰화된 각 단어에 대한 처리:
- 불용어 목록에 없는 경우: 해당 단어를 정제 결과에 추가한다.
- 불용어 목록에 있는 경우: 해당 단어를 무시하고 다음 단어로 넘어간다.
stopwords_list = ['the', 'is', 'and', 'in', 'to']
def remove_stopwords(sentence, stopwords):
tokens = sentence.split() # 예시로 문장을 띄어쓰기로 토큰화
result = [word for word in tokens if word.lower() not in stopwords]
return ' '.join(result)
original_sentence = "The quick brown fox jumps over the lazy dog."
processed_sentence = remove_stopwords(original_sentence, stopwords_list)
print(processed_sentence)위 예시에서는 'The', 'the', 'over', 'in'과 같은 불용어를 제거하고 정제된 문장을 출력한다.
불용어 제거까지 마치면 문장에는 단어 리스트만 남은 상태이다.
인코딩 (Encoding)
인코딩은 텍스트를 숫자로 변환하는 과정이다. 인코딩을 하는 이유는 텍스트를 숫자로 바꿔야만 기계 학습 알고리즘이 이해하고 학습할 수 있기 때문이다.
각 단어에 고유한 숫자를 할당하여 텍스트를 숫자로 표현하면 모델은 숫자로 된 데이터를 입력으로 받아들이고 학습할 수 있게 된다.
정수 인코딩 (Integer Encoding)
원본 문장: "The adventurous explorer discovered an ancient treasure hidden deep within the dense, mysterious jungle during a daring expedition."
예시 문장: {"adventurous": 1, "explorer": 2, "discovered": 3, "ancient": 4, "treasure": 5, "hidden": 6, "deep": 7, "dense": 8, "mysterious": 9, "jungle": 10, "daring": 11, "expedition": 12}
위 예시는 정수 인코딩을 한 결과로, 문장의 토큰화를 통해 단어 단위로 분리하여 각 단어를 해당 정수로 대체하여 문장을 정수로 표현한다.
빈 단어 사전(vocabulary)을 만들어서, 토큰화된 각 단어에 대해 빈도를 계산하며, 빈도에 따라 단어를 정수로 인코딩하고, 빈도가 높은 순으로 정렬된 사전을 생성한다.
원-핫 인코딩(One-hot encoding)
원-핫 인코딩은 단어 집합(vocabulary)의 크기를 벡터의 차원으로 설정한다.
표현하고자 하는 단어의 인덱스에 1의 값을 부여하고, 다른 인덱스에는 0을 부여하여 단어의 벡터 표현을 생성한다.
원-핫 인코딩을 통해 각 단어는 벡터로 표현되며, 벡터 간 유사성을 계산할 수 있다는 특징이 있다.
# 정수 인코딩
sentence = "The adventurous explorer discovered an ancient treasure hidden deep within the dense, mysterious jungle during a daring expedition."
word2index = {word: idx + 1 for idx, word in enumerate(sorted(set(sentence.split())))}
integer_encoded = [word2index[word] for word in sentence.split()]
# 원-핫 인코딩
from keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer()
tokenizer.fit_on_texts([sentence])
one_hot_encoded = tokenizer.texts_to_matrix([sentence], mode='binary')위와 같이 정수 인코딩과 원-핫 인코딩을 통해 단어를 숫자로 표현할 수 있다.
TF-IDF (Term Frequency-Inverse Document Frequency)
TF-IDF 방법은 단어가 특정 문서에서 얼마나 자주 등장하는지와 전체 문서 집합에서 얼마나 고유한지를 고려하여 가중치를 부여한다.
Term Frequency (TF)
- 특정 문서에서 특정 단어의 등장 횟수를 나타낸다.
- 특정 단어가 문서 내에서 얼마나 자주 등장하는지를 측정하여 해당 단어의 중요도를 표현한다.
- 일반적인 TF는 등장 횟수를 그대로 사용하거나 로그 스케일 등을 적용하여 사용한다.
Inverse Document Frequency (IDF)
- 특정 단어가 전체 문서 중에서 얼마나 중요한지를 나타낸다.
- 특정 단어가 전체 문서 집합에서 등장하는 빈도를 역수로 취한 값이다.
- 즉, 흔하게 등장하는 단어는 낮은 가중치를 가지고, 드물게 등장하는 단어는 높은 가중치를 가지도록 한다.
TF-IDF 공식
TF−IDF=tf(d,t)×idf(d,t)
- : 특정 문서 번호
- : 특정 단어 번호
- : 특정 문서 에서 특정 단어 의 등장 횟수
- : 특정 단어 가 등장한 문서의 수
- : 총 문서의 수
TF-IDF 계산 과정
- 각 문서에 대해 TF를 계산한다.
- 전체 문서에서 각 단어의 DF(문서 빈도)를 계산한다.
- IDF를 계산한다.
- TF와 IDF를 곱하여 TF-IDF를 계산한다.
정렬 (Sorting)
정렬은 주어진 데이터를 특정한 기준에 따라 순서대로 나열하는 것을 의미한다.
Python에서는 sorted() 함수를 사용하여 정렬할 수 있으며, 여기서 enumerate() 함수를 함께 사용하면 데이터의 순서를 추적하면서 정렬할 수 있다.
enumerate() 함수
# 정렬할 리스트
data = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
# enumerate와 lambda 함수를 사용한 정렬
sorted_data = sorted(enumerate(data), key=lambda x: x[1])
# 정렬 결과 출력
for index, value in sorted_data:
print(f"Index: {index}, Value: {value}")- enumerate(data): data 리스트의 각 요소에 대해 (index, value) 형태의 튜플을 생성한다.
- key=lambda x: x[1]: sorted() 함수의 key 인자를 사용하여 정렬 기준을 설정한다. 여기서는 튜플의 두 번째 요소, 즉 값(value)을 기준으로 정렬한다.
- sorted() 함수는 정렬된 튜플들을 반환한다.
- 결과를 출력할 때 enumerate()로 추적한 인덱스와 값을 함께 출력한다.
이렇게 함께 사용된 enumerate() 함수를 통해 정렬 전의 원본 데이터의 인덱스와 정렬 후의 순서를 연결할 수 있다.
Padding/Similarity
패딩은 시퀀스 데이터의 길이를 일치시키기 위해 추가적인 데이터를 삽입하는 기술을 의미한다.
자연어 처리에서는 주로 문장의 길이를 맞추기 위해 사용되며, 길이가 다를 경우에 인코딩을 할 때 Sorting을 통해서 등장 횟수가 많은 단어를 앞에 배치할 수도 있다.
Zero-padding
제로 패딩은 추가된 데이터를 0으로 채우는 방식을 말한다.
주로 순환 신경망 (Recurrent Neural Networks, RNNs)에서 시퀀스 데이터를 처리할 때 활용된다.
Recurrent Neural Networks (RNNs)
RNN은 순차적인 데이터, 특히 시퀀스 데이터를 처리하는 데 사용되는 신경망 구조이다.
문장, 시계열 데이터 등의 입력에 대해 이전 정보를 기억하고 활용할 수 있어 자연어 처리와 같은 일련의 작업에 적합하다.
RNN은 시퀀스의 길이에 민감하게 반응하는데, 일정한 길이로 시퀀스를 맞춰주기 위해 패딩이 필요할 수 있다.
Zero-padding in RNNs
RNN은 입력 시퀀스의 길이가 일정해야 제대로 동작한다. 만약 다양한 길이의 문장이나 시계열 데이터를 다룰 때, 제로 패딩을 통해 모든 시퀀스의 길이를 동일하게 만들어줘야 한다.
이를 통해 RNN이 고정된 크기의 입력을 처리하게 되며, 뒤따라오는 패딩 부분은 실제 정보가 아니므로 영향을 미치지 않도록 한다.
Zero-padding의 활용
from tensorflow.keras.preprocessing.sequence import pad_sequences
sequences = [
[1, 2, 3],
[4, 5],
[6, 7, 8, 9]
]
# zero-padding을 적용하여 모든 시퀀스의 길이를 동일하게 만듦
padded_sequences = pad_sequences(sequences, padding='post')
print(padded_sequences)위 코드에서 pad_sequences 함수는 시퀀스를 패딩하여 길이를 맞춰주었다.
padding='post'는 Zero-padding을 문장 뒷부분에 적용하도록 지정한 것이다.
참고자료
자연어처리 입문강의, 김동욱, MetaCode, 2024.01.26.
