
🌿검색 정확도 (Relevancy)
RDBMS의 검색
RDBMS는 검색을 할 때 조건에 맞는 데이터인지 아닌지를 구분하여 결과를 반환한다.
이는 조건을 만족하는지, 만족을 못 하는지의 이분법으로만 데이터를 구분하는 셈이다. 결국 얼마나 조건에 정확하게 부합하는지는 판단할 수 없다는 단점이 있다.
엘라스틱 서치의 검색
GET my_english/_search
{
"query": {
"match": {
"message": "quick dog"
}
}
}
엘라스틱서치는 검색을 할 때 알고리즘에 따라 검색 결과가 입력된 조건과 얼마나 정확하게 일치하는지를 계산한다. 그래서 어떤 게 더 가치가 있고 없는지를 알 수 있게 된다.
max_score는 검색한 것들 중에 가장 검색 정확도가 높은 것을 의미한다. 보통 처음에 나오는 검색 결과가 가장 검색 결과가 높은 것을 의미하며, 이는 뒤로 갈수록 검색 의도와는 벗어나고 있다고 볼 수 있다.
검색 정확도는 엘라스틱서치에서 가장 중요한 특징 중에 하나이다.
🌿스코어 (Score)
- BM25 알고리즘 (Best Matching) 알고리즘
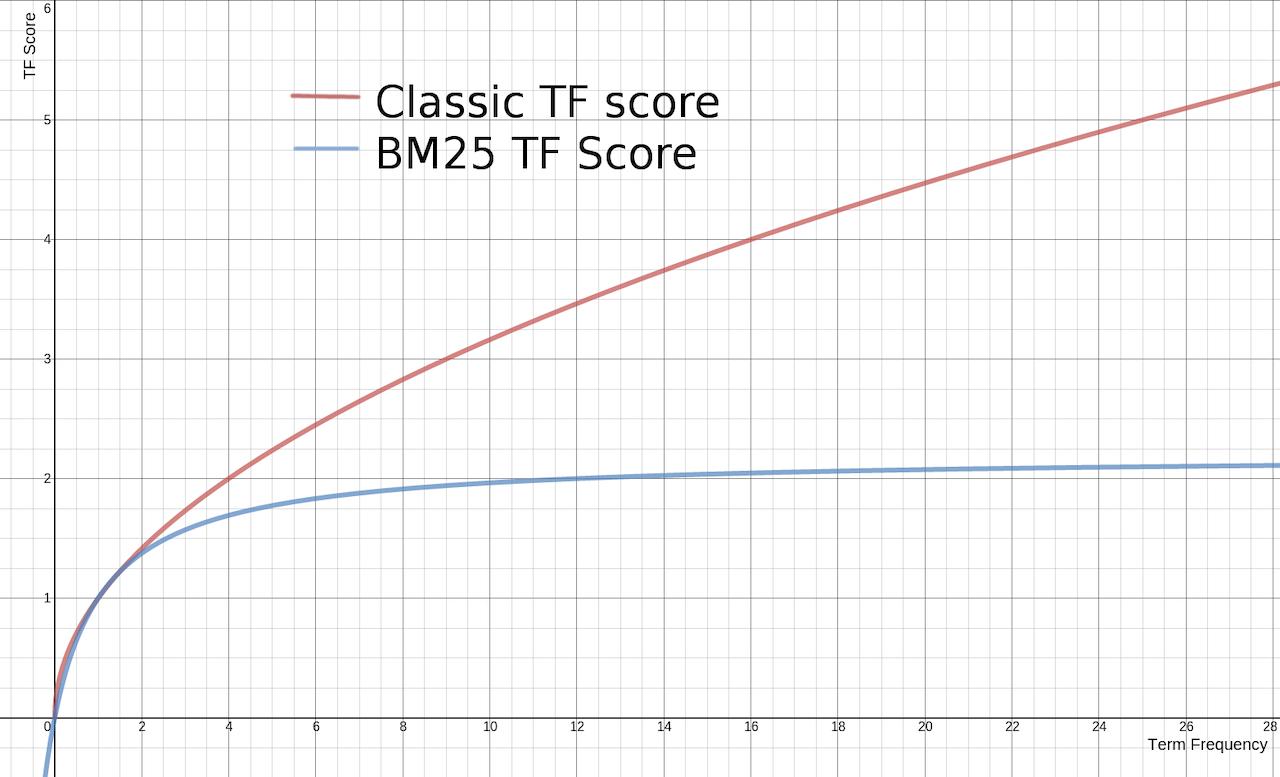
스코어는 검색된 결과가 얼마나 조건에 부합되는지를 나타내는 숫자이다.
이 계산에는 TF, IDF, Field Length 3가지 요소가 사용된다.
TF (Term Frequency)
하나의 도큐먼트 내에서 텀이 얼마나 많이 발견되는지에 대한 검색이다.
예로 들어 "자바"를 검색했을 때 결과로 2개의 도큐먼트가 검색되었다고 하자.
검색 결과로 1번 도큐먼트에는 "자바" 단어가 5번 들어 있었고, 2번 도큐먼트에는 "자바" 단어가 10번 들어있었다고 한다.
TF는 찾고 싶은 데이터가 더 많이 들어있는 경우에 검색 정확도가 높다고 판단한다.
IDF (Inverse Document Frequency)
텀이 발견된 도큐먼트의 개수가 얼마나 많은지에 대한 검색이다.
예로 들어 "자바 클래스"를 검색했다고 하자.
검색 결과로 "자바"를 검색한 경우 10개의 도큐먼트가 나왔고, "클래스"를 검색했을 때 100개의 도큐먼트가 나왔다는 얘기는 "자바"라는 단어의 희소성이 높다는 것을 의미한다.
IDF는 "자바"로 검색했을 때 나오는 결과가 좀 더 정확성이 높은 단어이고, "클래스"로 검색했을 때 나오는 결과는 다른 곳에서도 많이 발견되기 때문에 정확성이 낮은 단어라고 판단한다.
Field Length
검색된 도큐먼트의 길이에 따라 정확도를 반영한다.
예로 들어 "자바"를 검색했다고 하자.
1번 도큐먼트에서는 message라는 필드 안에 "자바 자료"에서 검색이 되었다. 그리고 2번 도큐먼트에서는 message라는 필드 안에 "안녕하세요. 저는 Isaac입니다. 저는 올해 대학을 졸업했습니다. 저는 디자이너이며, 취미로 자바 공부도 했습니다."에서 "자바"가 발견되었다.
1번 도큐먼트에서의 자바의 비중과 2번 도큐먼트에서의 자바의 비중은 서로 다르다.
Field Length는 문장이 짧을수록 단어의 중요도가 더 높아진다고 판단한다.

🌿검색 정확도 (Relevancy)
RDBMS의 검색
RDBMS는 검색을 할 때 조건에 맞는 데이터인지 아닌지를 구분하여 결과를 반환한다.
이는 조건을 만족하는지, 만족을 못 하는지의 이분법으로만 데이터를 구분하는 셈이다. 결국 얼마나 조건에 정확하게 부합하는지는 판단할 수 없다는 단점이 있다.
엘라스틱 서치의 검색
GET my_english/_search
{
"query": {
"match": {
"message": "quick dog"
}
}
}엘라스틱서치는 검색을 할 때 알고리즘에 따라 검색 결과가 입력된 조건과 얼마나 정확하게 일치하는지를 계산한다. 그래서 어떤 게 더 가치가 있고 없는지를 알 수 있게 된다.
max_score는 검색한 것들 중에 가장 검색 정확도가 높은 것을 의미한다. 보통 처음에 나오는 검색 결과가 가장 검색 결과가 높은 것을 의미하며, 이는 뒤로 갈수록 검색 의도와는 벗어나고 있다고 볼 수 있다.
검색 정확도는 엘라스틱서치에서 가장 중요한 특징 중에 하나이다.
🌿스코어 (Score)
- BM25 알고리즘 (Best Matching) 알고리즘
스코어는 검색된 결과가 얼마나 조건에 부합되는지를 나타내는 숫자이다.
이 계산에는 TF, IDF, Field Length 3가지 요소가 사용된다.
TF (Term Frequency)
하나의 도큐먼트 내에서 텀이 얼마나 많이 발견되는지에 대한 검색이다.
예로 들어 "자바"를 검색했을 때 결과로 2개의 도큐먼트가 검색되었다고 하자.
검색 결과로 1번 도큐먼트에는 "자바" 단어가 5번 들어 있었고, 2번 도큐먼트에는 "자바" 단어가 10번 들어있었다고 한다.
TF는 찾고 싶은 데이터가 더 많이 들어있는 경우에 검색 정확도가 높다고 판단한다.
IDF (Inverse Document Frequency)
텀이 발견된 도큐먼트의 개수가 얼마나 많은지에 대한 검색이다.
예로 들어 "자바 클래스"를 검색했다고 하자.
검색 결과로 "자바"를 검색한 경우 10개의 도큐먼트가 나왔고, "클래스"를 검색했을 때 100개의 도큐먼트가 나왔다는 얘기는 "자바"라는 단어의 희소성이 높다는 것을 의미한다.
IDF는 "자바"로 검색했을 때 나오는 결과가 좀 더 정확성이 높은 단어이고, "클래스"로 검색했을 때 나오는 결과는 다른 곳에서도 많이 발견되기 때문에 정확성이 낮은 단어라고 판단한다.
Field Length
검색된 도큐먼트의 길이에 따라 정확도를 반영한다.
예로 들어 "자바"를 검색했다고 하자.
1번 도큐먼트에서는 message라는 필드 안에 "자바 자료"에서 검색이 되었다. 그리고 2번 도큐먼트에서는 message라는 필드 안에 "안녕하세요. 저는 Isaac입니다. 저는 올해 대학을 졸업했습니다. 저는 디자이너이며, 취미로 자바 공부도 했습니다."에서 "자바"가 발견되었다.
1번 도큐먼트에서의 자바의 비중과 2번 도큐먼트에서의 자바의 비중은 서로 다르다.
Field Length는 문장이 짧을수록 단어의 중요도가 더 높아진다고 판단한다.